 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
A Scalable Probabilistic Model for Reward Optimizing Slate Recommendation
Aug 10, 2022
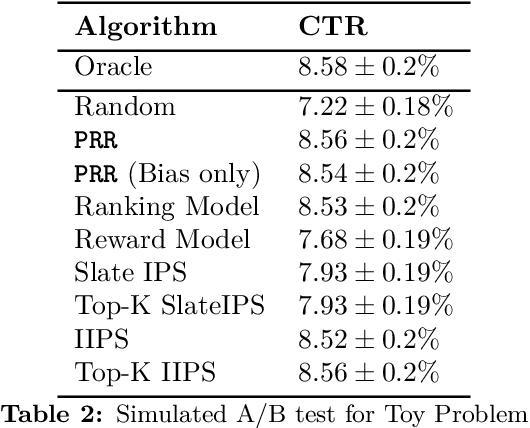
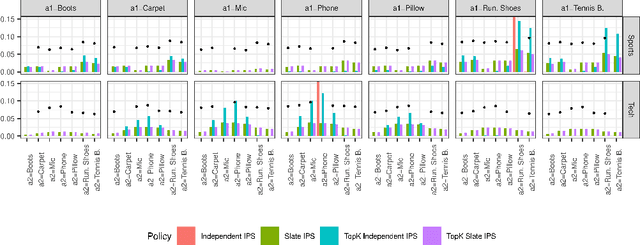
We introduce Probabilistic Rank and Reward model (PRR), a scalable probabilistic model for personalized slate recommendation. Our model allows state-of-the-art estimation of user interests in the following ubiquitous recommender system scenario: A user is shown a slate of K recommendations and the user chooses at most one of these K items. It is the goal of the recommender system to find the K items of most interest to a user in order to maximize the probability that the user interacts with the slate. Our contribution is to show that we can learn more effectively the probability of the recommendations being successful by combining the reward - whether the slate was clicked or not - and the rank - the item on the slate that was selected. Our method learns more efficiently than bandit methods that use only the reward, and user preference methods that use only the rank. It also provides similar or better estimation performance to independent inverse-propensity-score methods and is far more scalable. Our method is state of the art in terms of both speed and accuracy on massive datasets with up to 1 million items. Finally, our method allows fast delivery of recommendations powered by maximum inner product search (MIPS), making it suitable in extremely low latency domains such as computational advertising.
Simplifying Node Classification on Heterophilous Graphs with Compatible Label Propagation
May 19, 2022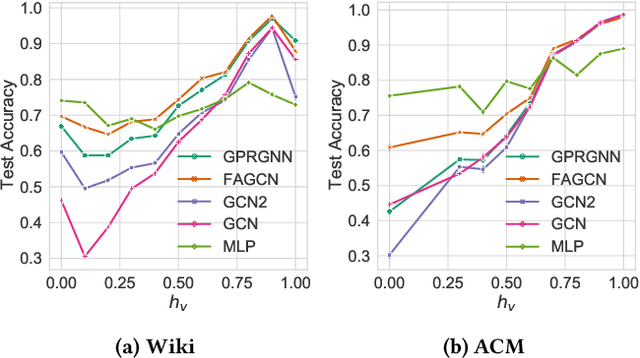

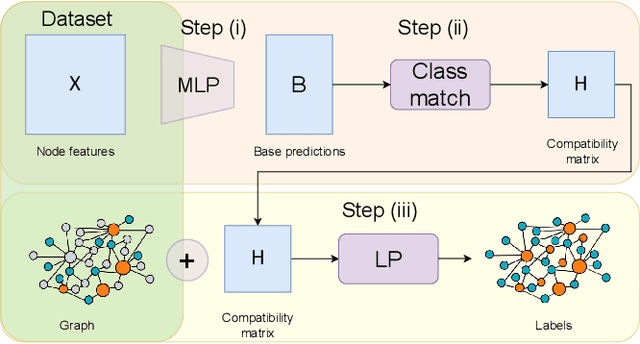
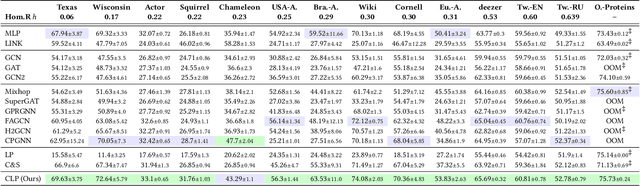
Graph Neural Networks (GNNs) have been predominant for graph learning tasks; however, recent studies showed that a well-known graph algorithm, Label Propagation (LP), combined with a shallow neural network can achieve comparable performance to GNNs in semi-supervised node classification on graphs with high homophily. In this paper, we show that this approach falls short on graphs with low homophily, where nodes often connect to the nodes of the opposite classes. To overcome this, we carefully design a combination of a base predictor with LP algorithm that enjoys a closed-form solution as well as convergence guarantees. Our algorithm first learns the class compatibility matrix and then aggregates label predictions using LP algorithm weighted by class compatibilities. On a wide variety of benchmarks, we show that our approach achieves the leading performance on graphs with various levels of homophily. Meanwhile, it has orders of magnitude fewer parameters and requires less execution time. Empirical evaluations demonstrate that simple adaptations of LP can be competitive in semi-supervised node classification in both homophily and heterophily regimes.
Reinforcement Learning Textbook
Jan 19, 2022This textbook covers principles behind main modern deep reinforcement learning algorithms that achieved breakthrough results in many domains from game AI to robotics. All required theory is explained with proofs using unified notation and emphasize on the differences between different types of algorithms and the reasons why they are constructed the way they are.
Combining Reward and Rank Signals for Slate Recommendation
Jul 29, 2021


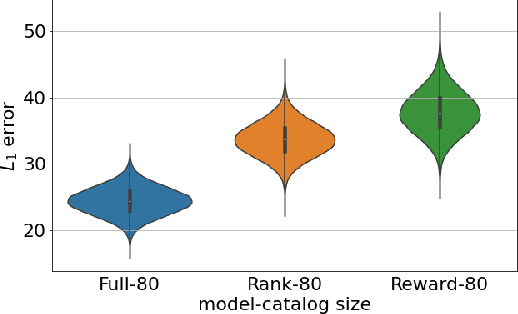
We consider the problem of slate recommendation, where the recommender system presents a user with a collection or slate composed of K recommended items at once. If the user finds the recommended items appealing then the user may click and the recommender system receives some feedback. Two pieces of information are available to the recommender system: was the slate clicked? (the reward), and if the slate was clicked, which item was clicked? (rank). In this paper, we formulate several Bayesian models that incorporate the reward signal (Reward model), the rank signal (Rank model), or both (Full model), for non-personalized slate recommendation. In our experiments, we analyze performance gains of the Full model and show that it achieves significantly lower error as the number of products in the catalog grows or as the slate size increases.
Are Hyperbolic Representations in Graphs Created Equal?
Jul 15, 2020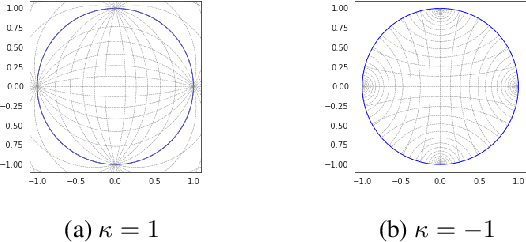

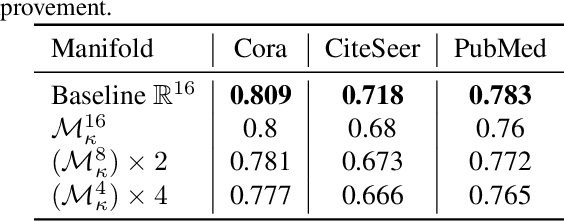

Recently there was an increasing interest in applications of graph neural networks in non-Euclidean geometry; however, are non-Euclidean representations always useful for graph learning tasks? For different problems such as node classification and link prediction we compute hyperbolic embeddings and conclude that for tasks that require global prediction consistency it might be useful to use non-Euclidean embeddings, while for other tasks Euclidean models are superior. To do so we first fix an issue of the existing models associated with the optimization process at zero curvature. Current hyperbolic models deal with gradients at the origin in ad-hoc manner, which is inefficient and can lead to numerical instabilities. We solve the instabilities of kappa-Stereographic model at zero curvature cases and evaluate the approach of embedding graphs into the manifold in several graph representation learning tasks.
Modern Deep Reinforcement Learning Algorithms
Jul 06, 2019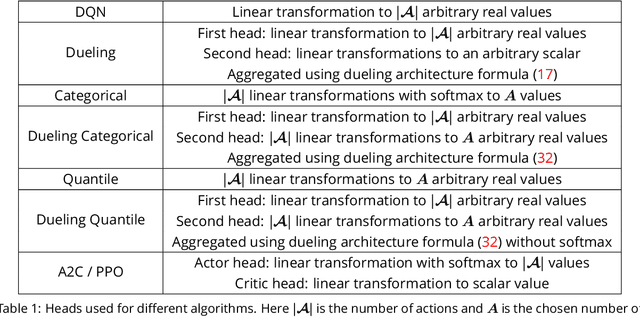
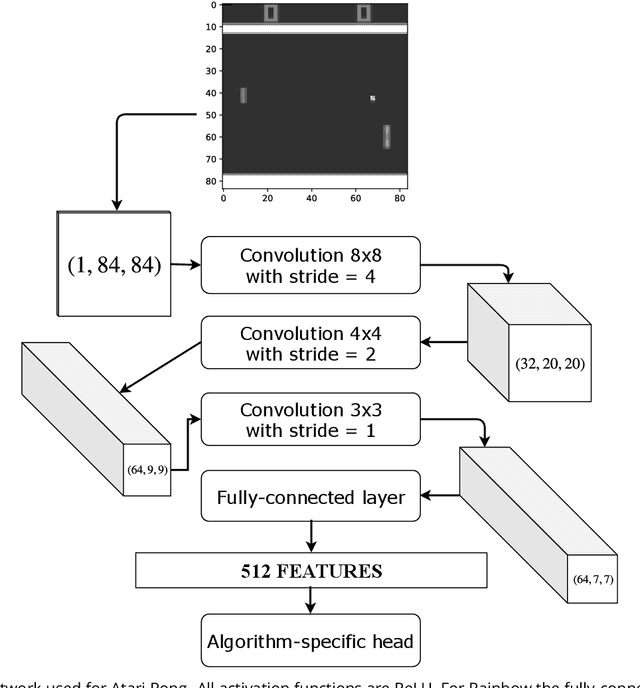
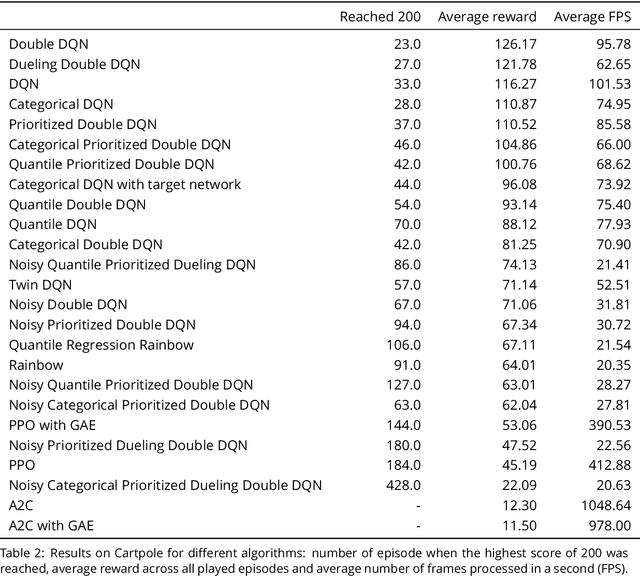
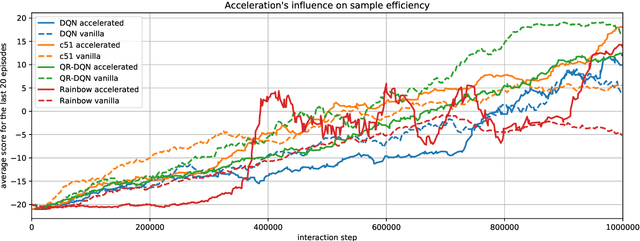
Recent advances in Reinforcement Learning, grounded on combining classical theoretical results with Deep Learning paradigm, led to breakthroughs in many artificial intelligence tasks and gave birth to Deep Reinforcement Learning (DRL) as a field of research. In this work latest DRL algorithms are reviewed with a focus on their theoretical justification, practical limitations and observed empirical properties.
Unsupervised Community Detection with Modularity-Based Attention Model
May 20, 2019
In this paper we take a problem of unsupervised nodes clustering on graphs and show how recent advances in attention models can be applied successfully in a "hard" regime of the problem. We propose an unsupervised algorithm that encodes Bethe Hessian embeddings by optimizing soft modularity loss and argue that our model is competitive to both classical and Graph Neural Network (GNN) models while it can be trained on a single graph.
Anonymous Walk Embeddings
Jun 08, 2018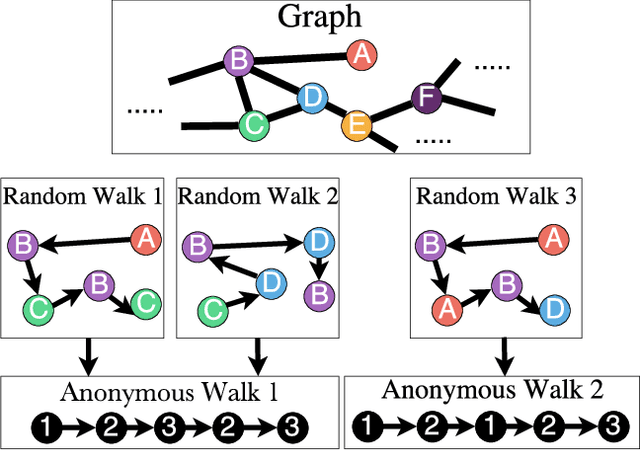
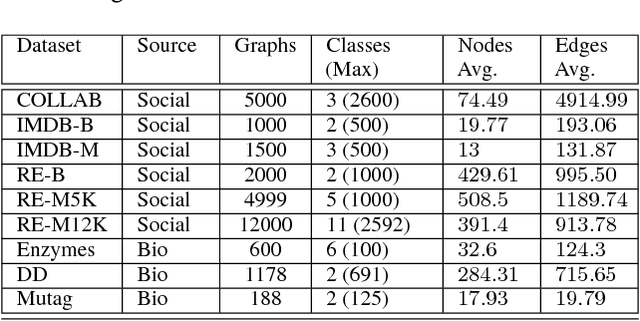
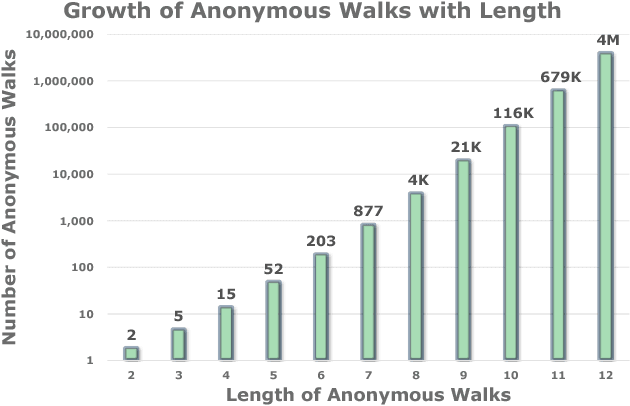
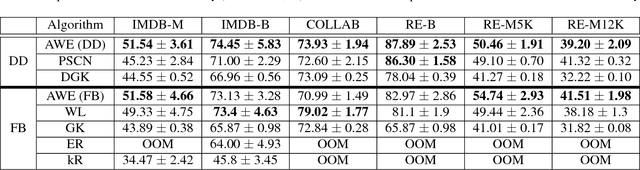
The task of representing entire graphs has seen a surge of prominent results, mainly due to learning convolutional neural networks (CNNs) on graph-structured data. While CNNs demonstrate state-of-the-art performance in graph classification task, such methods are supervised and therefore steer away from the original problem of network representation in task-agnostic manner. Here, we coherently propose an approach for embedding entire graphs and show that our feature representations with SVM classifier increase classification accuracy of CNN algorithms and traditional graph kernels. For this we describe a recently discovered graph object, anonymous walk, on which we design task-independent algorithms for learning graph representations in explicit and distributed way. Overall, our work represents a new scalable unsupervised learning of state-of-the-art representations of entire graphs.