 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOBRAS-TS: A new approach to Semi-Supervised Clustering of Time Series
Paper and Code


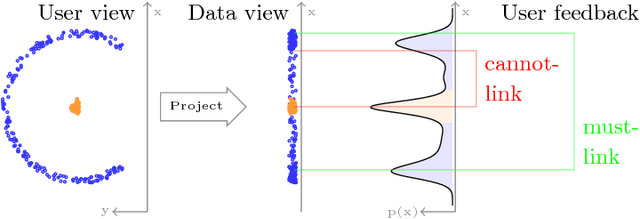
Clustering is ubiquitous in data analysis, including analysis of time series. It is inherently subjective: different users may prefer different clusterings for a particular dataset. Semi-supervised clustering addresses this by allowing the user to provide examples of instances that should (not) be in the same cluster. This paper studies semi-supervised clustering in the context of time series. We show that COBRAS, a state-of-the-art semi-supervised clustering method, can be adapted to this setting. We refer to this approach as COBRAS-TS. An extensive experimental evaluation supports the following claims: (1) COBRAS-TS far outperforms the current state of the art in semi-supervised clustering for time series, and thus presents a new baseline for the field; (2) COBRAS-TS can identify clusters with separated components; (3) COBRAS-TS can identify clusters that are characterized by small local patterns; (4) a small amount of semi-supervision can greatly improve clustering quality for time series; (5) the choice of the clustering algorithm matters (contrary to earlier claims in the literature).