 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: On the Offensive Potential of AI
Dec 24, 2024



Our society increasingly benefits from Artificial Intelligence (AI). Unfortunately, more and more evidence shows that AI is also used for offensive purposes. Prior works have revealed various examples of use cases in which the deployment of AI can lead to violation of security and privacy objectives. No extant work, however, has been able to draw a holistic picture of the offensive potential of AI. In this SoK paper we seek to lay the ground for a systematic analysis of the heterogeneous capabilities of offensive AI. In particular we (i) account for AI risks to both humans and systems while (ii) consolidating and distilling knowledge from academic literature, expert opinions, industrial venues, as well as laymen -- all of which being valuable sources of information on offensive AI. To enable alignment of such diverse sources of knowledge, we devise a common set of criteria reflecting essential technological factors related to offensive AI. With the help of such criteria, we systematically analyze: 95 research papers; 38 InfoSec briefings (from, e.g., BlackHat); the responses of a user study (N=549) entailing individuals with diverse backgrounds and expertise; and the opinion of 12 experts. Our contributions not only reveal concerning ways (some of which overlooked by prior work) in which AI can be offensively used today, but also represent a foothold to address this threat in the years to come.
Interplay between Federated Learning and Explainable Artificial Intelligence: a Scoping Review
Nov 07, 2024



The joint implementation of Federated learning (FL) and Explainable artificial intelligence (XAI) will allow training models from distributed data and explaining their inner workings while preserving important aspects of privacy. Towards establishing the benefits and tensions associated with their interplay, this scoping review maps those publications that jointly deal with FL and XAI, focusing on publications where an interplay between FL and model interpretability or post-hoc explanations was found. In total, 37 studies met our criteria, with more papers focusing on explanation methods (mainly feature relevance) than on interpretability (mainly algorithmic transparency). Most works used simulated horizontal FL setups involving 10 or fewer data centers. Only one study explicitly and quantitatively analyzed the influence of FL on model explanations, revealing a significant research gap. Aggregation of interpretability metrics across FL nodes created generalized global insights at the expense of node-specific patterns being diluted. 8 papers addressed the benefits of incorporating explanation methods as a component of the FL algorithm. Studies using established FL libraries or following reporting guidelines are a minority. More quantitative research and structured, transparent practices are needed to fully understand their mutual impact and under which conditions it happens.
A Design Toolbox for the Development of Collaborative Distributed Machine Learning Systems
Oct 12, 2023To leverage data for the sufficient training of machine learning (ML) models from multiple parties in a confidentiality-preserving way, various collaborative distributed ML (CDML) system designs have been developed, for example, to perform assisted learning, federated learning, and split learning. CDML system designs show different traits, including high agent autonomy, ML model confidentiality, and fault tolerance. Facing a wide variety of CDML system designs with different traits, it is difficult for developers to design CDML systems with traits that match use case requirements in a targeted way. However, inappropriate CDML system designs may result in CDML systems failing their envisioned purposes. We developed a CDML design toolbox that can guide the development of CDML systems. Based on the CDML design toolbox, we present CDML system archetypes with distinct key traits that can support the design of CDML systems to meet use case requirements.
Scalable Data Point Valuation in Decentralized Learning
May 01, 2023Existing research on data valuation in federated and swarm learning focuses on valuing client contributions and works best when data across clients is independent and identically distributed (IID). In practice, data is rarely distributed IID. We develop an approach called DDVal for decentralized data valuation, capable of valuing individual data points in federated and swarm learning. DDVal is based on sharing deep features and approximating Shapley values through a k-nearest neighbor approximation method. This allows for novel applications, for example, to simultaneously reward institutions and individuals for providing data to a decentralized machine learning task. The valuation of data points through DDVal allows to also draw hierarchical conclusions on the contribution of institutions, and we empirically show that the accuracy of DDVal in estimating institutional contributions is higher than existing Shapley value approximation methods for federated learning. Specifically, it reaches a cosine similarity in approximating Shapley values of 99.969 % in both, IID and non-IID data distributions across institutions, compared with 99.301 % and 97.250 % for the best state of the art methods. DDVal scales with the number of data points instead of the number of clients, and has a loglinear complexity. This scales more favorably than existing approaches with an exponential complexity. We show that DDVal is especially efficient in data distribution scenarios with many clients that have few data points - for example, more than 16 clients with 8,000 data points each. By integrating DDVal into a decentralized system, we show that it is not only suitable for centralized federated learning, but also decentralized swarm learning, which aligns well with the research on emerging internet technologies such as web3 to reward users for providing data to algorithms.
Reward Systems for Trustworthy Medical Federated Learning
May 01, 2022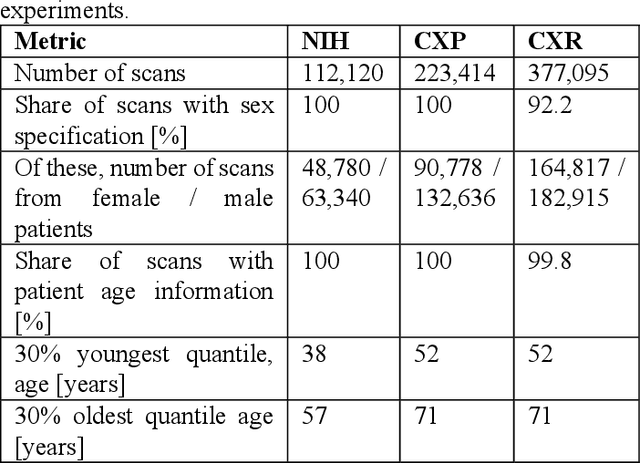
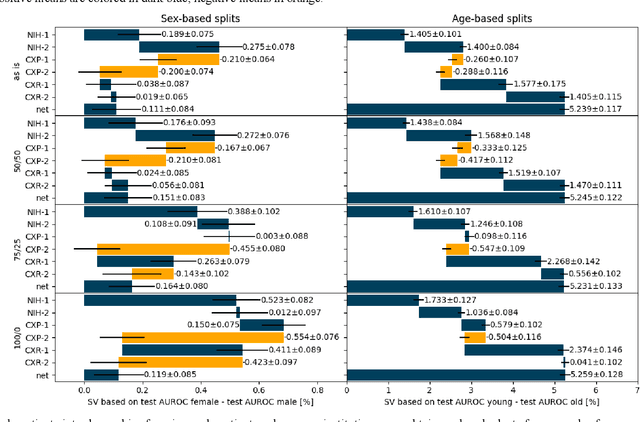
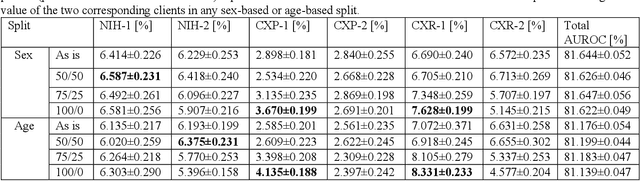
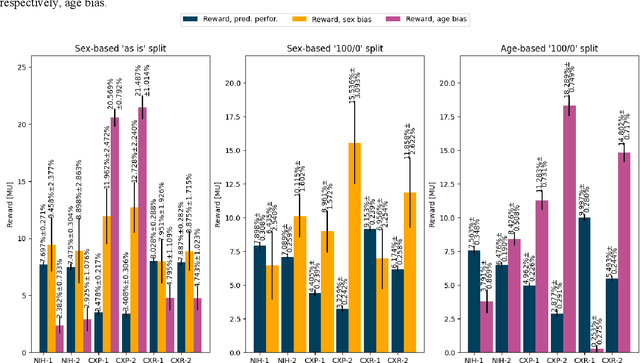
Federated learning (FL) has received high interest from researchers and practitioners to train machine learning (ML) models for healthcare. Ensuring the trustworthiness of these models is essential. Especially bias, defined as a disparity in the model's predictive performance across different subgroups, may cause unfairness against specific subgroups, which is an undesired phenomenon for trustworthy ML models. In this research, we address the question to which extent bias occurs in medical FL and how to prevent excessive bias through reward systems. We first evaluate how to measure the contributions of institutions toward predictive performance and bias in cross-silo medical FL with a Shapley value approximation method. In a second step, we design different reward systems incentivizing contributions toward high predictive performance or low bias. We then propose a combined reward system that incentivizes contributions toward both. We evaluate our work using multiple medical chest X-ray datasets focusing on patient subgroups defined by patient sex and age. Our results show that we can successfully measure contributions toward bias, and an integrated reward system successfully incentivizes contributions toward a well-performing model with low bias. While the partitioning of scans only slightly influences the overall bias, institutions with data predominantly from one subgroup introduce a favorable bias for this subgroup. Our results indicate that reward systems, which focus on predictive performance only, can transfer model bias against patients to an institutional level. Our work helps researchers and practitioners design reward systems for FL with well-aligned incentives for trustworthy ML.
Why Do Machine Learning Practitioners Still Use Manual Tuning? A Qualitative Study
Mar 03, 2022


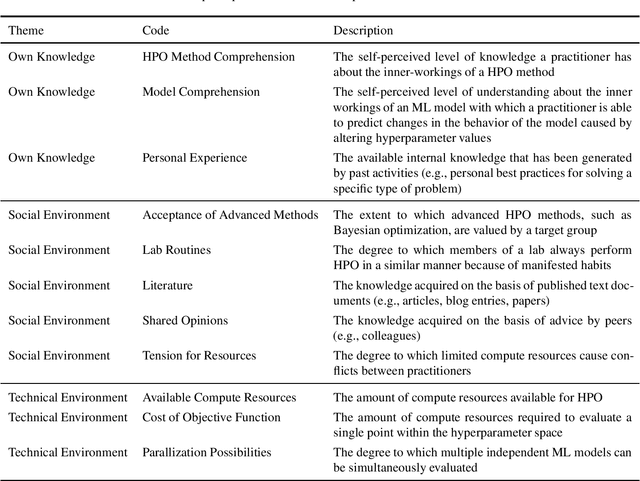
Current advanced hyperparameter optimization (HPO) methods, such as Bayesian optimization, have high sampling efficiency and facilitate replicability. Nonetheless, machine learning (ML) practitioners (e.g., engineers, scientists) mostly apply less advanced HPO methods, which can increase resource consumption during HPO or lead to underoptimized ML models. Therefore, we suspect that practitioners choose their HPO method to achieve different goals, such as decrease practitioner effort and target audience compliance. To develop HPO methods that align with such goals, the reasons why practitioners decide for specific HPO methods must be unveiled and thoroughly understood. Because qualitative research is most suitable to uncover such reasons and find potential explanations for them, we conducted semi-structured interviews to explain why practitioners choose different HPO methods. The interviews revealed six principal practitioner goals (e.g., increasing model comprehension), and eleven key factors that impact decisions for HPO methods (e.g., available computing resources). We deepen the understanding about why practitioners decide for different HPO methods and outline recommendations for improvements of HPO methods by aligning them with practitioner goals.
Architecture Matters: Investigating the Influence of Differential Privacy on Neural Network Design
Nov 29, 2021

One barrier to more widespread adoption of differentially private neural networks is the entailed accuracy loss. To address this issue, the relationship between neural network architectures and model accuracy under differential privacy constraints needs to be better understood. As a first step, we test whether extant knowledge on architecture design also holds in the differentially private setting. Our findings show that it does not; architectures that perform well without differential privacy, do not necessarily do so with differential privacy. Consequently, extant knowledge on neural network architecture design cannot be seamlessly translated into the differential privacy context. Future research is required to better understand the relationship between neural network architectures and model accuracy to enable better architecture design choices under differential privacy constraints.
On the Convergence of Artificial Intelligence and Distributed Ledger Technology: A Scoping Review and Future Research Agenda
Feb 05, 2020


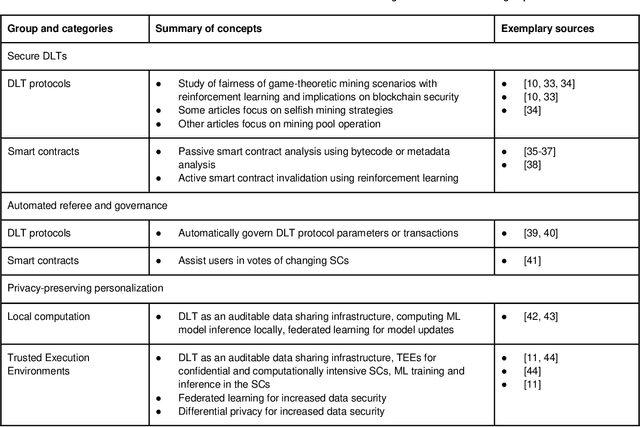
Developments in Artificial Intelligence (AI) and Distributed Ledger Technology (DLT) currently lead to lively debates in academia and practice. AI processes data to perform tasks that were previously thought possible only for humans. DLT has the potential to create consensus over data among a group of participants in uncertain environments. In recent research, both technologies are used in similar and even the same systems. Examples include the design of secure distributed ledgers or the creation of allied learning systems distributed across multiple nodes. This can lead to technological convergence, which in the past, has paved the way for major innovations in information technology. Previous work highlights several potential benefits of the convergence of AI and DLT but only provides a limited theoretical framework to describe upcoming real-world integration cases of both technologies. We aim to contribute by conducting a systematic literature review on previous work and providing rigorously derived future research opportunities. This work helps researchers active in AI or DLT to overcome current limitations in their field, and practitioners to develop systems along with the convergence of both technologies.