 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Optimizer Benchmark
Jun 26, 2024



In this paper, we present the Fast Optimizer Benchmark (FOB), a tool designed for evaluating deep learning optimizers during their development. The benchmark supports tasks from multiple domains such as computer vision, natural language processing, and graph learning. The focus is on convenient usage, featuring human-readable YAML configurations, SLURM integration, and plotting utilities. FOB can be used together with existing hyperparameter optimization (HPO) tools as it handles training and resuming of runs. The modular design enables integration into custom pipelines, using it simply as a collection of tasks. We showcase an optimizer comparison as a usage example of our tool. FOB can be found on GitHub: https://github.com/automl/FOB.
Non-Sequential Ensemble Kalman Filtering using Distributed Arrays
Nov 21, 2023



This work introduces a new, distributed implementation of the Ensemble Kalman Filter (EnKF) that allows for non-sequential assimilation of large datasets in high-dimensional problems. The traditional EnKF algorithm is computationally intensive and exhibits difficulties in applications requiring interaction with the background covariance matrix, prompting the use of methods like sequential assimilation which can introduce unwanted consequences, such as dependency on observation ordering. Our implementation leverages recent advancements in distributed computing to enable the construction and use of the full model error covariance matrix in distributed memory, allowing for single-batch assimilation of all observations and eliminating order dependencies. Comparative performance assessments, involving both synthetic and real-world paleoclimatic reconstruction applications, indicate that the new, non-sequential implementation outperforms the traditional, sequential one.
Why Do Machine Learning Practitioners Still Use Manual Tuning? A Qualitative Study
Mar 03, 2022


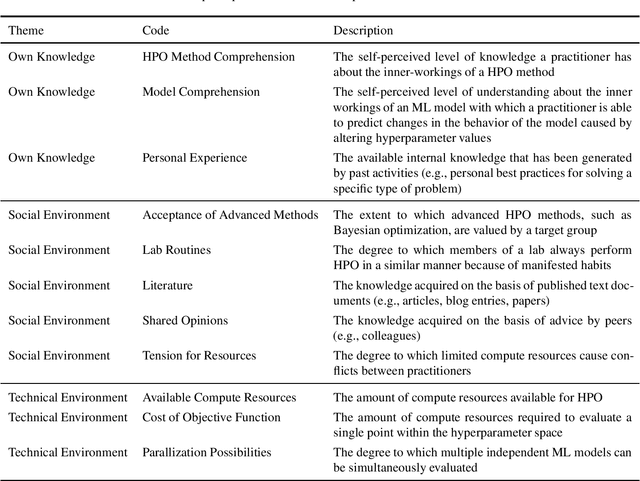
Current advanced hyperparameter optimization (HPO) methods, such as Bayesian optimization, have high sampling efficiency and facilitate replicability. Nonetheless, machine learning (ML) practitioners (e.g., engineers, scientists) mostly apply less advanced HPO methods, which can increase resource consumption during HPO or lead to underoptimized ML models. Therefore, we suspect that practitioners choose their HPO method to achieve different goals, such as decrease practitioner effort and target audience compliance. To develop HPO methods that align with such goals, the reasons why practitioners decide for specific HPO methods must be unveiled and thoroughly understood. Because qualitative research is most suitable to uncover such reasons and find potential explanations for them, we conducted semi-structured interviews to explain why practitioners choose different HPO methods. The interviews revealed six principal practitioner goals (e.g., increasing model comprehension), and eleven key factors that impact decisions for HPO methods (e.g., available computing resources). We deepen the understanding about why practitioners decide for different HPO methods and outline recommendations for improvements of HPO methods by aligning them with practitioner goals.
Robust and Scalable Differentiable Neural Computer for Question Answering
Jul 07, 2018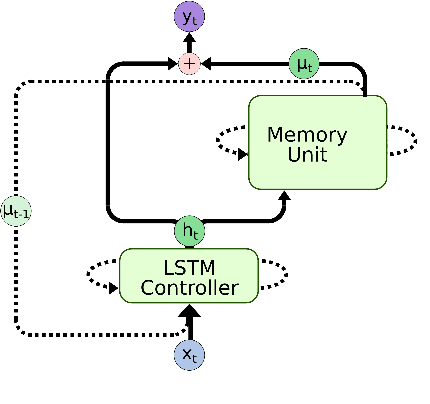
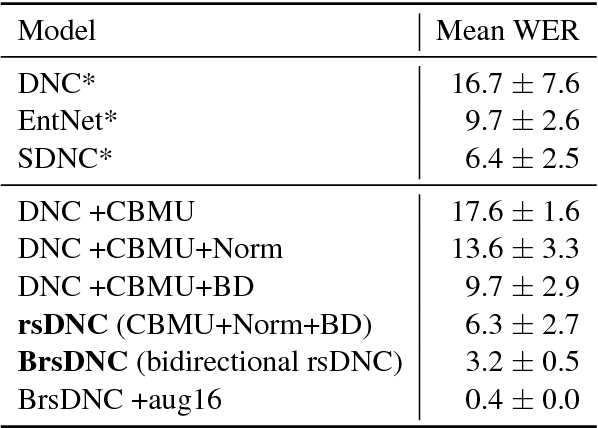
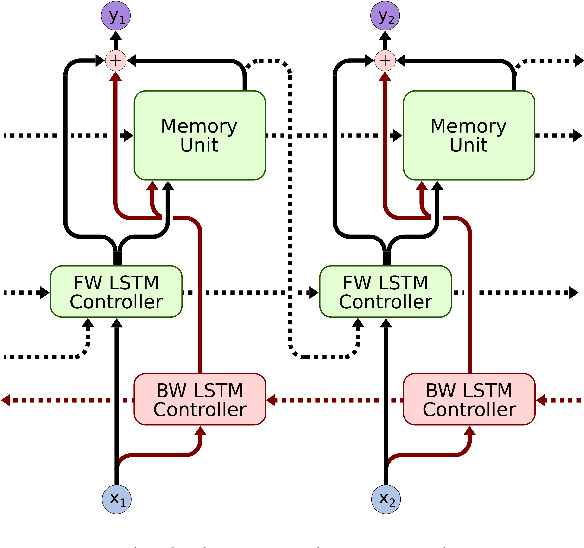
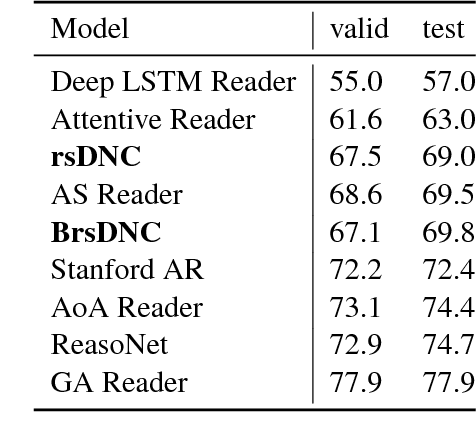
Deep learning models are often not easily adaptable to new tasks and require task-specific adjustments. The differentiable neural computer (DNC), a memory-augmented neural network, is designed as a general problem solver which can be used in a wide range of tasks. But in reality, it is hard to apply this model to new tasks. We analyze the DNC and identify possible improvements within the application of question answering. This motivates a more robust and scalable DNC (rsDNC). The objective precondition is to keep the general character of this model intact while making its application more reliable and speeding up its required training time. The rsDNC is distinguished by a more robust training, a slim memory unit and a bidirectional architecture. We not only achieve new state-of-the-art performance on the bAbI task, but also minimize the performance variance between different initializations. Furthermore, we demonstrate the simplified applicability of the rsDNC to new tasks with passable results on the CNN RC task without adaptions.