 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Sequential Ensemble Kalman Filtering using Distributed Arrays
Nov 21, 2023



This work introduces a new, distributed implementation of the Ensemble Kalman Filter (EnKF) that allows for non-sequential assimilation of large datasets in high-dimensional problems. The traditional EnKF algorithm is computationally intensive and exhibits difficulties in applications requiring interaction with the background covariance matrix, prompting the use of methods like sequential assimilation which can introduce unwanted consequences, such as dependency on observation ordering. Our implementation leverages recent advancements in distributed computing to enable the construction and use of the full model error covariance matrix in distributed memory, allowing for single-batch assimilation of all observations and eliminating order dependencies. Comparative performance assessments, involving both synthetic and real-world paleoclimatic reconstruction applications, indicate that the new, non-sequential implementation outperforms the traditional, sequential one.
Uncertainty Quantification and Experimental Design for large-scale linear Inverse Problems under Gaussian Process Priors
Sep 08, 2021
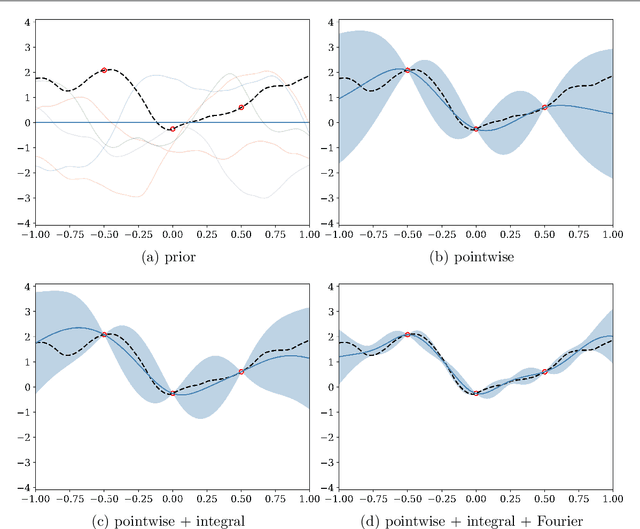
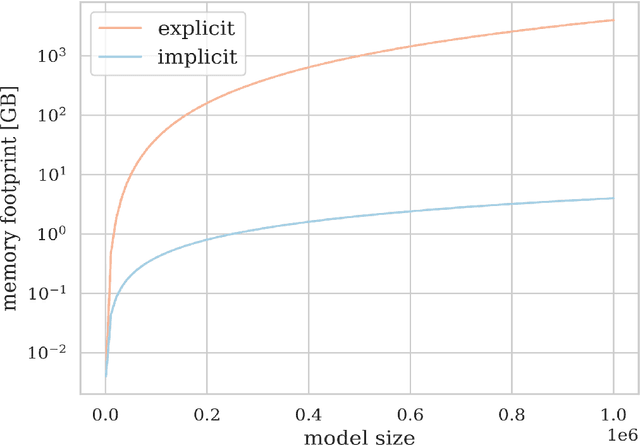
We consider the use of Gaussian process (GP) priors for solving inverse problems in a Bayesian framework. As is well known, the computational complexity of GPs scales cubically in the number of datapoints. We here show that in the context of inverse problems involving integral operators, one faces additional difficulties that hinder inversion on large grids. Furthermore, in that context, covariance matrices can become too large to be stored. By leveraging results about sequential disintegrations of Gaussian measures, we are able to introduce an implicit representation of posterior covariance matrices that reduces the memory footprint by only storing low rank intermediate matrices, while allowing individual elements to be accessed on-the-fly without needing to build full posterior covariance matrices. Moreover, it allows for fast sequential inclusion of new observations. These features are crucial when considering sequential experimental design tasks. We demonstrate our approach by computing sequential data collection plans for excursion set recovery for a gravimetric inverse problem, where the goal is to provide fine resolution estimates of high density regions inside the Stromboli volcano, Italy. Sequential data collection plans are computed by extending the weighted integrated variance reduction (wIVR) criterion to inverse problems. Our results show that this criterion is able to significantly reduce the uncertainty on the excursion volume, reaching close to minimal levels of residual uncertainty. Overall, our techniques allow the advantages of probabilistic models to be brought to bear on large-scale inverse problems arising in the natural sciences.
Learning excursion sets of vector-valued Gaussian random fields for autonomous ocean sampling
Jul 07, 2020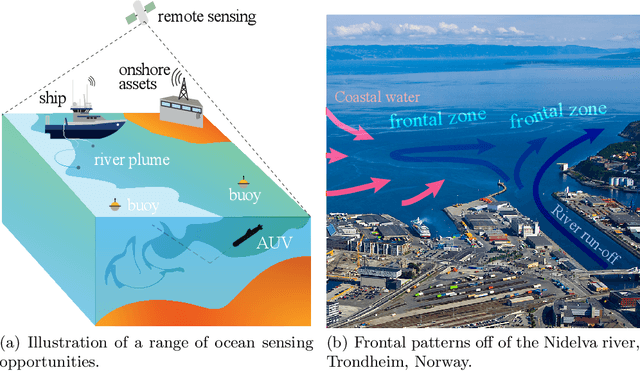

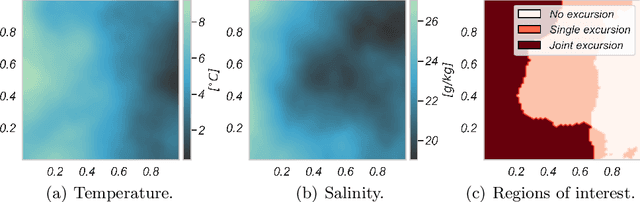
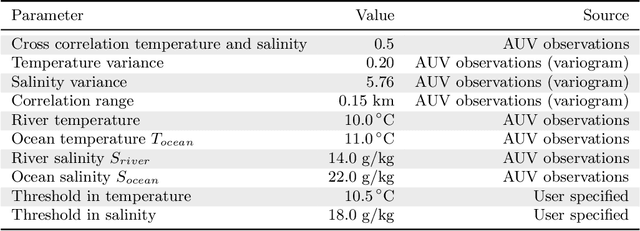
Improving and optimizing oceanographic sampling is a crucial task for marine science and maritime resource management. Faced with limited resources in understanding processes in the water-column, the combination of statistics and autonomous systems provide new opportunities for experimental design. In this work we develop efficient spatial sampling methods for characterizing regions defined by simultaneous exceedances above prescribed thresholds of several responses, with an application focus on mapping coastal ocean phenomena based on temperature and salinity measurements. Specifically, we define a design criterion based on uncertainty in the excursions of vector-valued Gaussian random fields, and derive tractable expressions for the expected integrated Bernoulli variance reduction in such a framework. We demonstrate how this criterion can be used to prioritize sampling efforts at locations that are ambiguous, making exploration more effective. We use simulations to study and compare properties of the considered approaches, followed by results from field deployments with an autonomous underwater vehicle as part of a study mapping the boundary of a river plume. The results demonstrate the potential of combining statistical methods and robotic platforms to effectively inform and execute data-driven environmental sampling.