 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterplay between Federated Learning and Explainable Artificial Intelligence: a Scoping Review
Nov 07, 2024



The joint implementation of Federated learning (FL) and Explainable artificial intelligence (XAI) will allow training models from distributed data and explaining their inner workings while preserving important aspects of privacy. Towards establishing the benefits and tensions associated with their interplay, this scoping review maps those publications that jointly deal with FL and XAI, focusing on publications where an interplay between FL and model interpretability or post-hoc explanations was found. In total, 37 studies met our criteria, with more papers focusing on explanation methods (mainly feature relevance) than on interpretability (mainly algorithmic transparency). Most works used simulated horizontal FL setups involving 10 or fewer data centers. Only one study explicitly and quantitatively analyzed the influence of FL on model explanations, revealing a significant research gap. Aggregation of interpretability metrics across FL nodes created generalized global insights at the expense of node-specific patterns being diluted. 8 papers addressed the benefits of incorporating explanation methods as a component of the FL algorithm. Studies using established FL libraries or following reporting guidelines are a minority. More quantitative research and structured, transparent practices are needed to fully understand their mutual impact and under which conditions it happens.
Reward Systems for Trustworthy Medical Federated Learning
May 01, 2022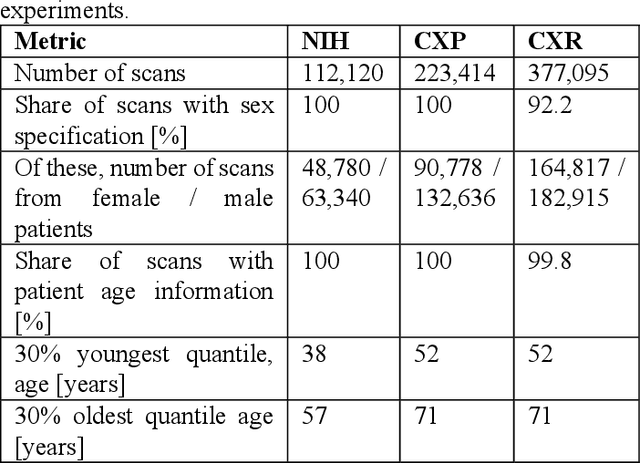
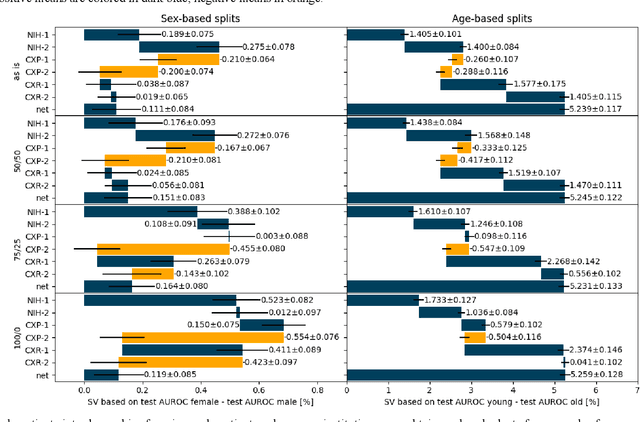
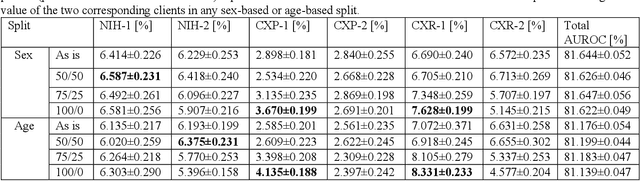
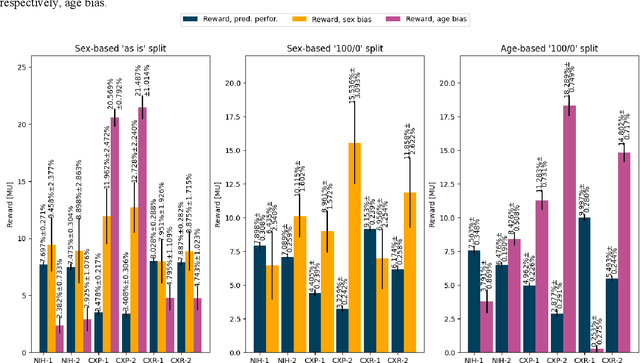
Federated learning (FL) has received high interest from researchers and practitioners to train machine learning (ML) models for healthcare. Ensuring the trustworthiness of these models is essential. Especially bias, defined as a disparity in the model's predictive performance across different subgroups, may cause unfairness against specific subgroups, which is an undesired phenomenon for trustworthy ML models. In this research, we address the question to which extent bias occurs in medical FL and how to prevent excessive bias through reward systems. We first evaluate how to measure the contributions of institutions toward predictive performance and bias in cross-silo medical FL with a Shapley value approximation method. In a second step, we design different reward systems incentivizing contributions toward high predictive performance or low bias. We then propose a combined reward system that incentivizes contributions toward both. We evaluate our work using multiple medical chest X-ray datasets focusing on patient subgroups defined by patient sex and age. Our results show that we can successfully measure contributions toward bias, and an integrated reward system successfully incentivizes contributions toward a well-performing model with low bias. While the partitioning of scans only slightly influences the overall bias, institutions with data predominantly from one subgroup introduce a favorable bias for this subgroup. Our results indicate that reward systems, which focus on predictive performance only, can transfer model bias against patients to an institutional level. Our work helps researchers and practitioners design reward systems for FL with well-aligned incentives for trustworthy ML.