 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Data Point Valuation in Decentralized Learning
May 01, 2023Existing research on data valuation in federated and swarm learning focuses on valuing client contributions and works best when data across clients is independent and identically distributed (IID). In practice, data is rarely distributed IID. We develop an approach called DDVal for decentralized data valuation, capable of valuing individual data points in federated and swarm learning. DDVal is based on sharing deep features and approximating Shapley values through a k-nearest neighbor approximation method. This allows for novel applications, for example, to simultaneously reward institutions and individuals for providing data to a decentralized machine learning task. The valuation of data points through DDVal allows to also draw hierarchical conclusions on the contribution of institutions, and we empirically show that the accuracy of DDVal in estimating institutional contributions is higher than existing Shapley value approximation methods for federated learning. Specifically, it reaches a cosine similarity in approximating Shapley values of 99.969 % in both, IID and non-IID data distributions across institutions, compared with 99.301 % and 97.250 % for the best state of the art methods. DDVal scales with the number of data points instead of the number of clients, and has a loglinear complexity. This scales more favorably than existing approaches with an exponential complexity. We show that DDVal is especially efficient in data distribution scenarios with many clients that have few data points - for example, more than 16 clients with 8,000 data points each. By integrating DDVal into a decentralized system, we show that it is not only suitable for centralized federated learning, but also decentralized swarm learning, which aligns well with the research on emerging internet technologies such as web3 to reward users for providing data to algorithms.
Reward Systems for Trustworthy Medical Federated Learning
May 01, 2022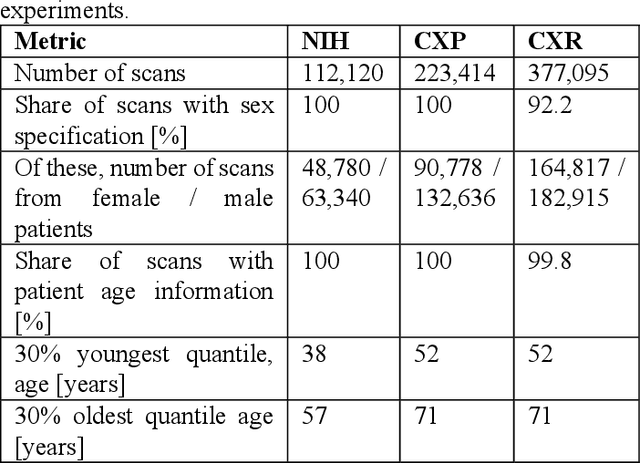
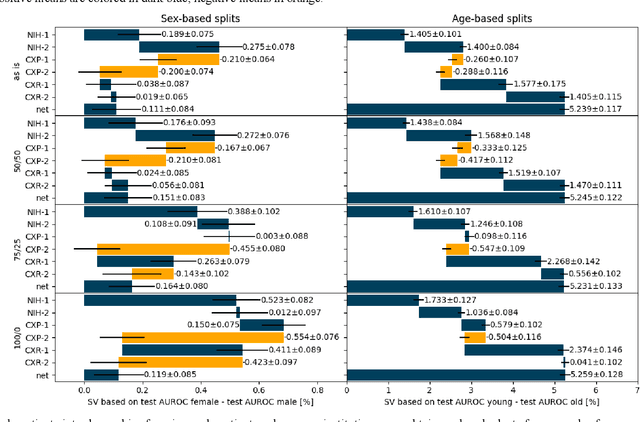
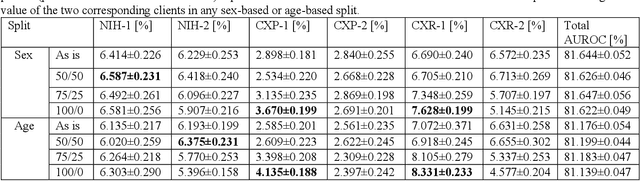
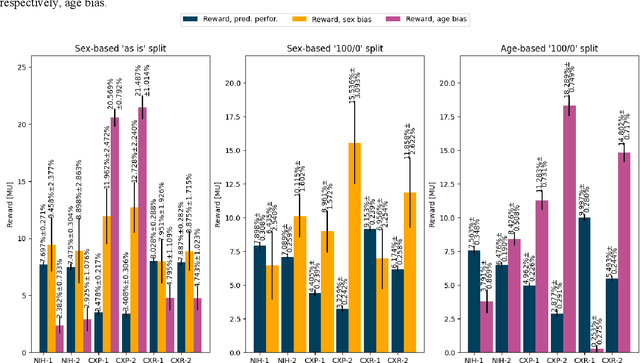
Federated learning (FL) has received high interest from researchers and practitioners to train machine learning (ML) models for healthcare. Ensuring the trustworthiness of these models is essential. Especially bias, defined as a disparity in the model's predictive performance across different subgroups, may cause unfairness against specific subgroups, which is an undesired phenomenon for trustworthy ML models. In this research, we address the question to which extent bias occurs in medical FL and how to prevent excessive bias through reward systems. We first evaluate how to measure the contributions of institutions toward predictive performance and bias in cross-silo medical FL with a Shapley value approximation method. In a second step, we design different reward systems incentivizing contributions toward high predictive performance or low bias. We then propose a combined reward system that incentivizes contributions toward both. We evaluate our work using multiple medical chest X-ray datasets focusing on patient subgroups defined by patient sex and age. Our results show that we can successfully measure contributions toward bias, and an integrated reward system successfully incentivizes contributions toward a well-performing model with low bias. While the partitioning of scans only slightly influences the overall bias, institutions with data predominantly from one subgroup introduce a favorable bias for this subgroup. Our results indicate that reward systems, which focus on predictive performance only, can transfer model bias against patients to an institutional level. Our work helps researchers and practitioners design reward systems for FL with well-aligned incentives for trustworthy ML.
On the Convergence of Artificial Intelligence and Distributed Ledger Technology: A Scoping Review and Future Research Agenda
Feb 05, 2020


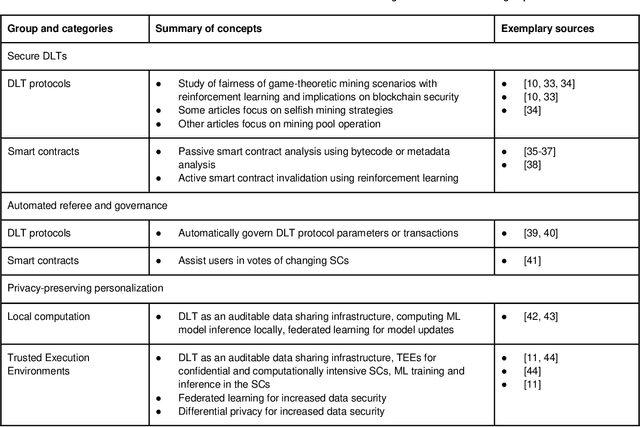
Developments in Artificial Intelligence (AI) and Distributed Ledger Technology (DLT) currently lead to lively debates in academia and practice. AI processes data to perform tasks that were previously thought possible only for humans. DLT has the potential to create consensus over data among a group of participants in uncertain environments. In recent research, both technologies are used in similar and even the same systems. Examples include the design of secure distributed ledgers or the creation of allied learning systems distributed across multiple nodes. This can lead to technological convergence, which in the past, has paved the way for major innovations in information technology. Previous work highlights several potential benefits of the convergence of AI and DLT but only provides a limited theoretical framework to describe upcoming real-world integration cases of both technologies. We aim to contribute by conducting a systematic literature review on previous work and providing rigorously derived future research opportunities. This work helps researchers active in AI or DLT to overcome current limitations in their field, and practitioners to develop systems along with the convergence of both technologies.