 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Compression for Distributed Learning without Control Variates
Dec 05, 2024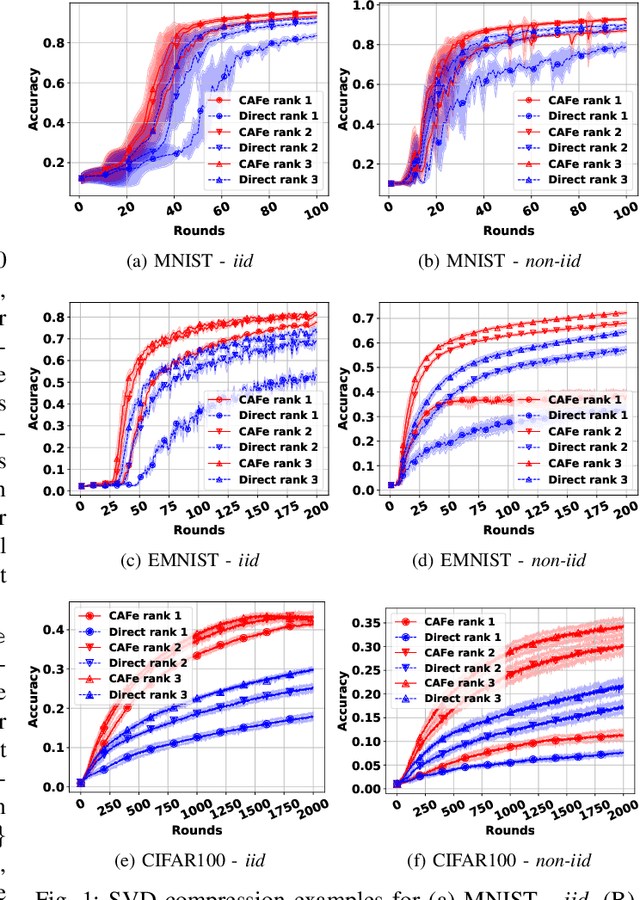
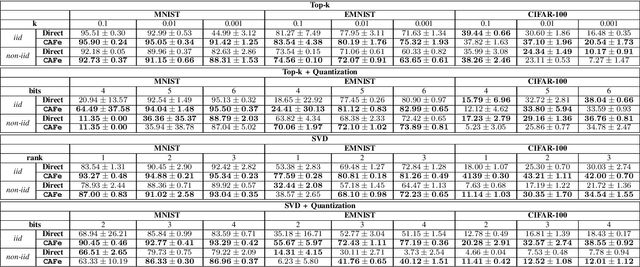
Distributed learning algorithms, such as the ones employed in Federated Learning (FL), require communication compression to reduce the cost of client uploads. The compression methods used in practice are often biased, which require error feedback to achieve convergence when the compression is aggressive. In turn, error feedback requires client-specific control variates, which directly contradicts privacy-preserving principles and requires stateful clients. In this paper, we propose Compressed Aggregate Feedback (CAFe), a novel distributed learning framework that allows highly compressible client updates by exploiting past aggregated updates, and does not require control variates. We consider Distributed Gradient Descent (DGD) as a representative algorithm and provide a theoretical proof of CAFe's superiority to Distributed Compressed Gradient Descent (DCGD) with biased compression in the non-smooth regime with bounded gradient dissimilarity. Experimental results confirm that CAFe consistently outperforms distributed learning with direct compression and highlight the compressibility of the client updates with CAFe.
Overcoming Data and Model Heterogeneities in Decentralized Federated Learning via Synthetic Anchors
May 19, 2024



Conventional Federated Learning (FL) involves collaborative training of a global model while maintaining user data privacy. One of its branches, decentralized FL, is a serverless network that allows clients to own and optimize different local models separately, which results in saving management and communication resources. Despite the promising advancements in decentralized FL, it may reduce model generalizability due to lacking a global model. In this scenario, managing data and model heterogeneity among clients becomes a crucial problem, which poses a unique challenge that must be overcome: How can every client's local model learn generalizable representation in a decentralized manner? To address this challenge, we propose a novel Decentralized FL technique by introducing Synthetic Anchors, dubbed as DeSA. Based on the theory of domain adaptation and Knowledge Distillation (KD), we theoretically and empirically show that synthesizing global anchors based on raw data distribution facilitates mutual knowledge transfer. We further design two effective regularization terms for local training: 1) REG loss that regularizes the distribution of the client's latent embedding with the anchors and 2) KD loss that enables clients to learn from others. Through extensive experiments on diverse client data distributions, we showcase the effectiveness of DeSA in enhancing both inter- and intra-domain accuracy of each client.
Backdoor Attack on Unpaired Medical Image-Text Foundation Models: A Pilot Study on MedCLIP
Jan 01, 2024
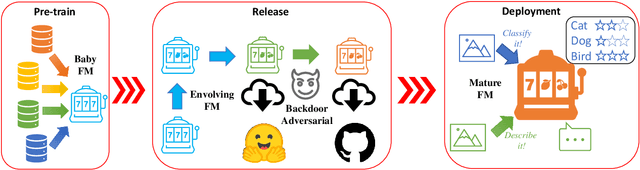


In recent years, foundation models (FMs) have solidified their role as cornerstone advancements in the deep learning domain. By extracting intricate patterns from vast datasets, these models consistently achieve state-of-the-art results across a spectrum of downstream tasks, all without necessitating extensive computational resources. Notably, MedCLIP, a vision-language contrastive learning-based medical FM, has been designed using unpaired image-text training. While the medical domain has often adopted unpaired training to amplify data, the exploration of potential security concerns linked to this approach hasn't kept pace with its practical usage. Notably, the augmentation capabilities inherent in unpaired training also indicate that minor label discrepancies can result in significant model deviations. In this study, we frame this label discrepancy as a backdoor attack problem. We further analyze its impact on medical FMs throughout the FM supply chain. Our evaluation primarily revolves around MedCLIP, emblematic of medical FM employing the unpaired strategy. We begin with an exploration of vulnerabilities in MedCLIP stemming from unpaired image-text matching, termed BadMatch. BadMatch is achieved using a modest set of wrongly labeled data. Subsequently, we disrupt MedCLIP's contrastive learning through BadDist-assisted BadMatch by introducing a Bad-Distance between the embeddings of clean and poisoned data. Additionally, combined with BadMatch and BadDist, the attacking pipeline consistently fends off backdoor assaults across diverse model designs, datasets, and triggers. Also, our findings reveal that current defense strategies are insufficient in detecting these latent threats in medical FMs' supply chains.
Scalable Data Point Valuation in Decentralized Learning
May 01, 2023Existing research on data valuation in federated and swarm learning focuses on valuing client contributions and works best when data across clients is independent and identically distributed (IID). In practice, data is rarely distributed IID. We develop an approach called DDVal for decentralized data valuation, capable of valuing individual data points in federated and swarm learning. DDVal is based on sharing deep features and approximating Shapley values through a k-nearest neighbor approximation method. This allows for novel applications, for example, to simultaneously reward institutions and individuals for providing data to a decentralized machine learning task. The valuation of data points through DDVal allows to also draw hierarchical conclusions on the contribution of institutions, and we empirically show that the accuracy of DDVal in estimating institutional contributions is higher than existing Shapley value approximation methods for federated learning. Specifically, it reaches a cosine similarity in approximating Shapley values of 99.969 % in both, IID and non-IID data distributions across institutions, compared with 99.301 % and 97.250 % for the best state of the art methods. DDVal scales with the number of data points instead of the number of clients, and has a loglinear complexity. This scales more favorably than existing approaches with an exponential complexity. We show that DDVal is especially efficient in data distribution scenarios with many clients that have few data points - for example, more than 16 clients with 8,000 data points each. By integrating DDVal into a decentralized system, we show that it is not only suitable for centralized federated learning, but also decentralized swarm learning, which aligns well with the research on emerging internet technologies such as web3 to reward users for providing data to algorithms.
Federated Virtual Learning on Heterogeneous Data with Local-global Distillation
Mar 04, 2023



Despite Federated Learning (FL)'s trend for learning machine learning models in a distributed manner, it is susceptible to performance drops when training on heterogeneous data. Recently, dataset distillation has been explored in order to improve the efficiency and scalability of FL by creating a smaller, synthetic dataset that retains the performance of a model trained on the local private datasets. We discover that using distilled local datasets can amplify the heterogeneity issue in FL. To address this, we propose a new method, called Federated Virtual Learning on Heterogeneous Data with Local-Global Distillation (FEDLGD), which trains FL using a smaller synthetic dataset (referred as virtual data) created through a combination of local and global distillation. Specifically, to handle synchronization and class imbalance, we propose iterative distribution matching to allow clients to have the same amount of balanced local virtual data; to harmonize the domain shifts, we use federated gradient matching to distill global virtual data that are shared with clients without hindering data privacy to rectify heterogeneous local training via enforcing local-global feature similarity. We experiment on both benchmark and real-world datasets that contain heterogeneous data from different sources. Our method outperforms state-of-the-art heterogeneous FL algorithms under the setting with a very limited amount of distilled virtual data.
Efficient Medical Image Assessment via Self-supervised Learning
Sep 28, 2022High-performance deep learning methods typically rely on large annotated training datasets, which are difficult to obtain in many clinical applications due to the high cost of medical image labeling. Existing data assessment methods commonly require knowing the labels in advance, which are not feasible to achieve our goal of 'knowing which data to label.' To this end, we formulate and propose a novel and efficient data assessment strategy, EXponentiAl Marginal sINgular valuE (EXAMINE) score, to rank the quality of unlabeled medical image data based on their useful latent representations extracted via Self-supervised Learning (SSL) networks. Motivated by theoretical implication of SSL embedding space, we leverage a Masked Autoencoder for feature extraction. Furthermore, we evaluate data quality based on the marginal change of the largest singular value after excluding the data point in the dataset. We conduct extensive experiments on a pathology dataset. Our results indicate the effectiveness and efficiency of our proposed methods for selecting the most valuable data to label.