 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiscotti: A Ledger for Private and Secure Peer-to-Peer Machine Learning
Nov 27, 2018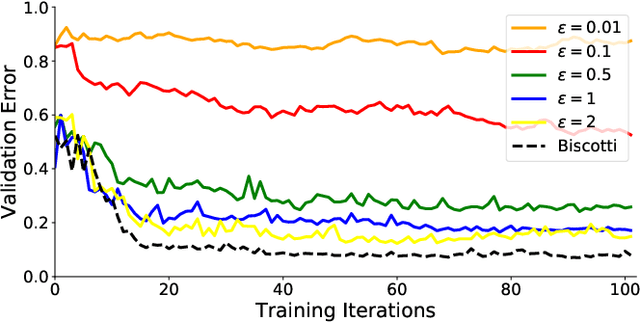
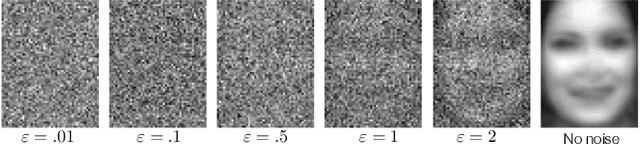

Centralized solutions for privacy-preserving multi-party ML are becoming increasingly infeasible: a variety of attacks have demonstrated their weaknesses. Federated Learning is the current state of the art in supporting secure multi-party ML:data is maintained on the owner's device and is aggregated through a secure protocol. However, this process assumes a trusted centralized infrastructure for coordination and clients must trust that the central service does not maliciously use the byproducts of client data. As a response, we propose Biscotti: a fully decentralized P2P approach to multi-party ML, which leverages blockchain primitives to coordinate a privacy-preserving ML process between peering clients. Our evaluation demonstrates that Biscotti is scalable, fault tolerant, and defends against known attacks. Biscotti is able to protect the performance of the global model at scale even when 48 percent of the adversaries are malicious, and at the same time provides privacy while preventing poisoning attacks.
Mitigating Sybils in Federated Learning Poisoning
Aug 14, 2018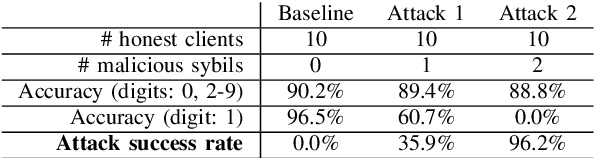
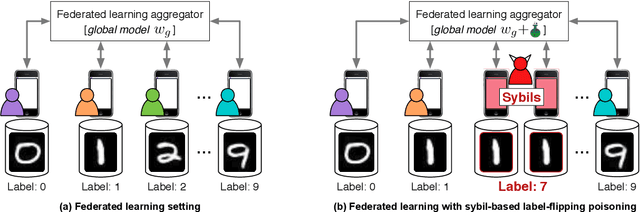
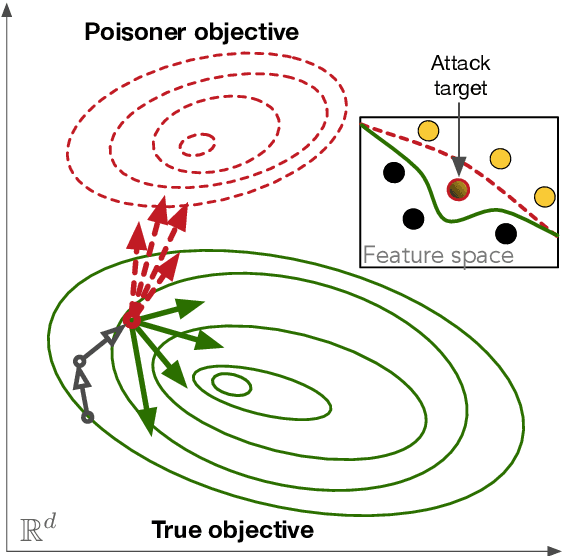
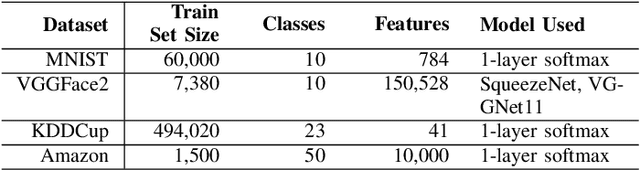
Machine learning (ML) over distributed data is relevant to a variety of domains. Existing approaches, such as federated learning, compose the outputs computed by a group of devices at a central aggregator and run multi-round algorithms to generate a globally shared model. Unfortunately, such approaches are susceptible to a variety of attacks, including model poisoning, which is made substantially worse in the presence of sybils. In this paper we first evaluate the vulnerability of federated learning to sybil-based poisoning attacks. We then describe FoolsGold, a novel defense to this problem that identifies poisoning sybils based on the diversity of client contributions in the distributed learning process. Unlike prior work, our system does not assume that the attackers are in the minority, requires no auxiliary information outside of the learning process, and makes fewer assumptions about clients and their data. In our evaluation we show that FoolsGold exceeds the capabilities of existing state of the art approaches to countering ML poisoning attacks. Our results hold for a variety of conditions, including different distributions of data, varying poisoning targets, and various attack strategies.