 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttacking Autonomous Driving Agents with Adversarial Machine Learning: A Holistic Evaluation with the CARLA Leaderboard
Nov 18, 2025To autonomously control vehicles, driving agents use outputs from a combination of machine-learning (ML) models, controller logic, and custom modules. Although numerous prior works have shown that adversarial examples can mislead ML models used in autonomous driving contexts, it remains unclear if these attacks are effective at producing harmful driving actions for various agents, environments, and scenarios. To assess the risk of adversarial examples to autonomous driving, we evaluate attacks against a variety of driving agents, rather than against ML models in isolation. To support this evaluation, we leverage CARLA, an urban driving simulator, to create and evaluate adversarial examples. We create adversarial patches designed to stop or steer driving agents, stream them into the CARLA simulator at runtime, and evaluate them against agents from the CARLA Leaderboard, a public repository of best-performing autonomous driving agents from an annual research competition. Unlike prior work, we evaluate attacks against autonomous driving systems without creating or modifying any driving-agent code and against all parts of the agent included with the ML model. We perform a case-study investigation of two attack strategies against three open-source driving agents from the CARLA Leaderboard across multiple driving scenarios, lighting conditions, and locations. Interestingly, we show that, although some attacks can successfully mislead ML models into predicting erroneous stopping or steering commands, some driving agents use modules, such as PID control or GPS-based rules, that can overrule attacker-manipulated predictions from ML models.
Model Selection of Anomaly Detectors in the Absence of Labeled Validation Data
Oct 16, 2023



Anomaly detection requires detecting abnormal samples in large unlabeled datasets. While progress in deep learning and the advent of foundation models has produced powerful unsupervised anomaly detection methods, their deployment in practice is often hindered by the lack of labeled data -- without it, the detection accuracy of an anomaly detector cannot be evaluated reliably. In this work, we propose a general-purpose framework for evaluating image-based anomaly detectors with synthetically generated validation data. Our method assumes access to a small support set of normal images which are processed with a pre-trained diffusion model (our proposed method requires no training or fine-tuning) to produce synthetic anomalies. When mixed with normal samples from the support set, the synthetic anomalies create detection tasks that compose a validation framework for anomaly detection evaluation and model selection. In an extensive empirical study, ranging from natural images to industrial applications, we find that our synthetic validation framework selects the same models and hyper-parameters as selection with a ground-truth validation set. In addition, we find that prompts selected by our method for CLIP-based anomaly detection outperforms all other prompt selection strategies, and leads to the overall best detection accuracy, even on the challenging MVTec-AD dataset.
Biscotti: A Ledger for Private and Secure Peer-to-Peer Machine Learning
Nov 27, 2018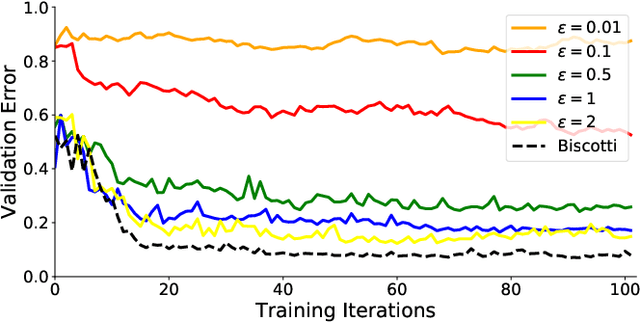

Centralized solutions for privacy-preserving multi-party ML are becoming increasingly infeasible: a variety of attacks have demonstrated their weaknesses. Federated Learning is the current state of the art in supporting secure multi-party ML:data is maintained on the owner's device and is aggregated through a secure protocol. However, this process assumes a trusted centralized infrastructure for coordination and clients must trust that the central service does not maliciously use the byproducts of client data. As a response, we propose Biscotti: a fully decentralized P2P approach to multi-party ML, which leverages blockchain primitives to coordinate a privacy-preserving ML process between peering clients. Our evaluation demonstrates that Biscotti is scalable, fault tolerant, and defends against known attacks. Biscotti is able to protect the performance of the global model at scale even when 48 percent of the adversaries are malicious, and at the same time provides privacy while preventing poisoning attacks.
Dancing in the Dark: Private Multi-Party Machine Learning in an Untrusted Setting
Nov 23, 2018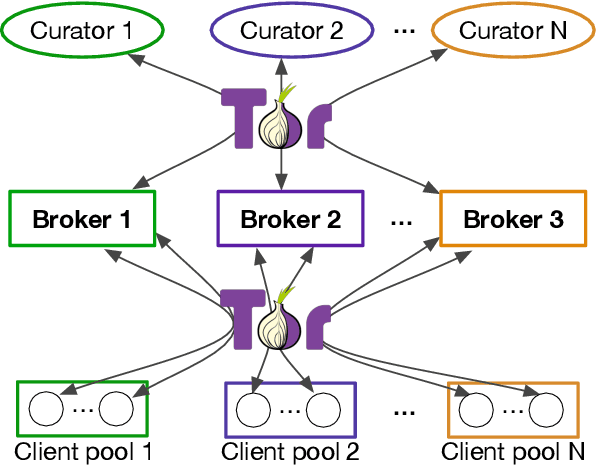

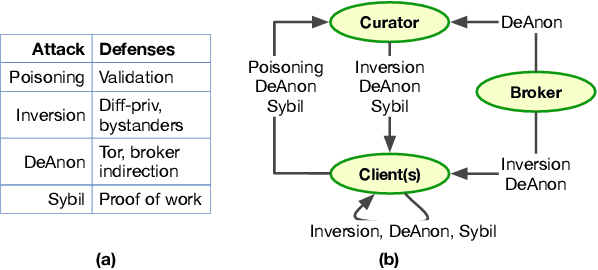
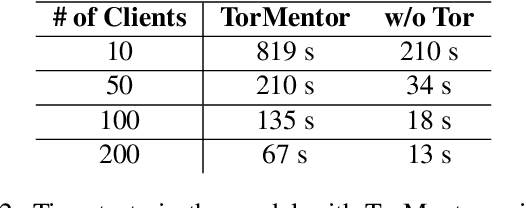
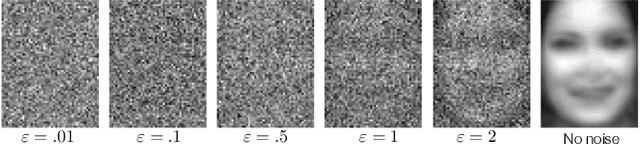
Distributed machine learning (ML) systems today use an unsophisticated threat model: data sources must trust a central ML process. We propose a brokered learning abstraction that allows data sources to contribute towards a globally-shared model with provable privacy guarantees in an untrusted setting. We realize this abstraction by building on federated learning, the state of the art in multi-party ML, to construct TorMentor: an anonymous hidden service that supports private multi-party ML. We define a new threat model by characterizing, developing and evaluating new attacks in the brokered learning setting, along with new defenses for these attacks. We show that TorMentor effectively protects data providers against known ML attacks while providing them with a tunable trade-off between model accuracy and privacy. We evaluate TorMentor with local and geo-distributed deployments on Azure/Tor. In an experiment with 200 clients and 14 MB of data per client, our prototype trained a logistic regression model using stochastic gradient descent in 65s.
Mitigating Sybils in Federated Learning Poisoning
Aug 14, 2018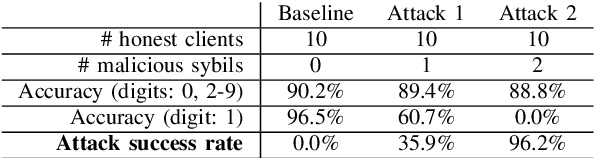
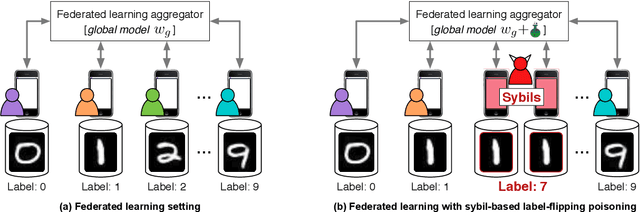
Machine learning (ML) over distributed data is relevant to a variety of domains. Existing approaches, such as federated learning, compose the outputs computed by a group of devices at a central aggregator and run multi-round algorithms to generate a globally shared model. Unfortunately, such approaches are susceptible to a variety of attacks, including model poisoning, which is made substantially worse in the presence of sybils. In this paper we first evaluate the vulnerability of federated learning to sybil-based poisoning attacks. We then describe FoolsGold, a novel defense to this problem that identifies poisoning sybils based on the diversity of client contributions in the distributed learning process. Unlike prior work, our system does not assume that the attackers are in the minority, requires no auxiliary information outside of the learning process, and makes fewer assumptions about clients and their data. In our evaluation we show that FoolsGold exceeds the capabilities of existing state of the art approaches to countering ML poisoning attacks. Our results hold for a variety of conditions, including different distributions of data, varying poisoning targets, and various attack strategies.