 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentSM: Semantic Memory for Agentic Text-to-SQL
Jan 22, 2026Recent advances in LLM-based Text-to-SQL have achieved remarkable gains on public benchmarks such as BIRD and Spider. Yet, these systems struggle to scale in realistic enterprise settings with large, complex schemas, diverse SQL dialects, and expensive multi-step reasoning. Emerging agentic approaches show potential for adaptive reasoning but often suffer from inefficiency and instability-repeating interactions with databases, producing inconsistent outputs, and occasionally failing to generate valid answers. To address these challenges, we introduce Agent Semantic Memory (AgentSM), an agentic framework for Text-to-SQL that builds and leverages interpretable semantic memory. Instead of relying on raw scratchpads or vector retrieval, AgentSM captures prior execution traces-or synthesizes curated ones-as structured programs that directly guide future reasoning. This design enables systematic reuse of reasoning paths, which allows agents to scale to larger schemas, more complex questions, and longer trajectories efficiently and reliably. Compared to state-of-the-art systems, AgentSM achieves higher efficiency by reducing average token usage and trajectory length by 25% and 35%, respectively, on the Spider 2.0 benchmark. It also improves execution accuracy, reaching a state-of-the-art accuracy of 44.8% on the Spider 2.0 Lite benchmark.
Anomaly Detection of Tabular Data Using LLMs
Jun 24, 2024Large language models (LLMs) have shown their potential in long-context understanding and mathematical reasoning. In this paper, we study the problem of using LLMs to detect tabular anomalies and show that pre-trained LLMs are zero-shot batch-level anomaly detectors. That is, without extra distribution-specific model fitting, they can discover hidden outliers in a batch of data, demonstrating their ability to identify low-density data regions. For LLMs that are not well aligned with anomaly detection and frequently output factual errors, we apply simple yet effective data-generating processes to simulate synthetic batch-level anomaly detection datasets and propose an end-to-end fine-tuning strategy to bring out the potential of LLMs in detecting real anomalies. Experiments on a large anomaly detection benchmark (ODDS) showcase i) GPT-4 has on-par performance with the state-of-the-art transductive learning-based anomaly detection methods and ii) the efficacy of our synthetic dataset and fine-tuning strategy in aligning LLMs to this task.
Model Selection of Anomaly Detectors in the Absence of Labeled Validation Data
Oct 16, 2023



Anomaly detection requires detecting abnormal samples in large unlabeled datasets. While progress in deep learning and the advent of foundation models has produced powerful unsupervised anomaly detection methods, their deployment in practice is often hindered by the lack of labeled data -- without it, the detection accuracy of an anomaly detector cannot be evaluated reliably. In this work, we propose a general-purpose framework for evaluating image-based anomaly detectors with synthetically generated validation data. Our method assumes access to a small support set of normal images which are processed with a pre-trained diffusion model (our proposed method requires no training or fine-tuning) to produce synthetic anomalies. When mixed with normal samples from the support set, the synthetic anomalies create detection tasks that compose a validation framework for anomaly detection evaluation and model selection. In an extensive empirical study, ranging from natural images to industrial applications, we find that our synthetic validation framework selects the same models and hyper-parameters as selection with a ground-truth validation set. In addition, we find that prompts selected by our method for CLIP-based anomaly detection outperforms all other prompt selection strategies, and leads to the overall best detection accuracy, even on the challenging MVTec-AD dataset.
Zero-Shot Anomaly Detection without Foundation Models
Feb 15, 2023



Anomaly detection (AD) tries to identify data instances that deviate from the norm in a given data set. Since data distributions are subject to distribution shifts, our concept of ``normality" may also drift, raising the need for zero-shot adaptation approaches for anomaly detection. However, the fact that current zero-shot AD methods rely on foundation models that are restricted in their domain (natural language and natural images), are costly, and oftentimes proprietary, asks for alternative approaches. In this paper, we propose a simple and highly effective zero-shot AD approach compatible with a variety of established AD methods. Our solution relies on training an off-the-shelf anomaly detector (such as a deep SVDD) on a set of inter-related data distributions in combination with batch normalization. This simple recipe--batch normalization plus meta-training--is a highly effective and versatile tool. Our results demonstrate the first zero-shot anomaly detection results for tabular data and SOTA zero-shot AD results for image data from specialized domains.
Deep Anomaly Detection under Labeling Budget Constraints
Feb 15, 2023



Selecting informative data points for expert feedback can significantly improve the performance of anomaly detection (AD) in various contexts, such as medical diagnostics or fraud detection. In this paper, we determine a set of theoretical conditions under which anomaly scores generalize from labeled queries to unlabeled data. Motivated by these results, we propose a data labeling strategy with optimal data coverage under labeling budget constraints. In addition, we propose a new learning framework for semi-supervised AD. Extensive experiments on image, tabular, and video data sets show that our approach results in state-of-the-art semi-supervised AD performance under labeling budget constraints.
Latent Outlier Exposure for Anomaly Detection with Contaminated Data
Feb 20, 2022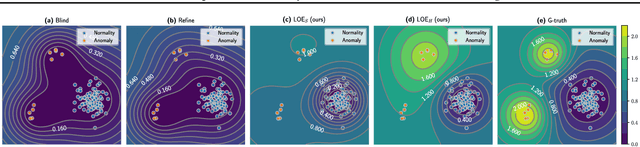



Anomaly detection aims at identifying data points that show systematic deviations from the majority of data in an unlabeled dataset. A common assumption is that clean training data (free of anomalies) is available, which is often violated in practice. We propose a strategy for training an anomaly detector in the presence of unlabeled anomalies that is compatible with a broad class of models. The idea is to jointly infer binary labels to each datum (normal vs. anomalous) while updating the model parameters. Inspired by outlier exposure (Hendrycks et al., 2018) that considers synthetically created, labeled anomalies, we thereby use a combination of two losses that share parameters: one for the normal and one for the anomalous data. We then iteratively proceed with block coordinate updates on the parameters and the most likely (latent) labels. Our experiments with several backbone models on three image datasets, 30 tabular data sets, and a video anomaly detection benchmark showed consistent and significant improvements over the baselines.
Variational Beam Search for Online Learning with Distribution Shifts
Dec 15, 2020

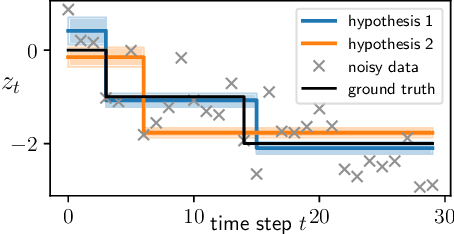
We consider the problem of online learning in the presence of sudden distribution shifts as frequently encountered in applications such as autonomous navigation. Distribution shifts require constant performance monitoring and re-training. They may also be hard to detect and can lead to a slow but steady degradation in model performance. To address this problem we propose a new Bayesian meta-algorithm that can both (i) make inferences about subtle distribution shifts based on minimal sequential observations and (ii) accordingly adapt a model in an online fashion. The approach uses beam search over multiple change point hypotheses to perform inference on a hierarchical sequential latent variable modeling framework. Our proposed approach is model-agnostic, applicable to both supervised and unsupervised learning, and yields significant improvements over state-of-the-art Bayesian online learning approaches.
Enhanced Neural Machine Translation by Learning from Draft
Oct 04, 2017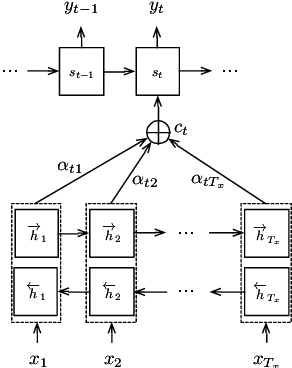


Neural machine translation (NMT) has recently achieved impressive results. A potential problem of the existing NMT algorithm, however, is that the decoding is conducted from left to right, without considering the right context. This paper proposes an two-stage approach to solve the problem. In the first stage, a conventional attention-based NMT system is used to produce a draft translation, and in the second stage, a novel double-attention NMT system is used to refine the translation, by looking at the original input as well as the draft translation. This drafting-and-refinement can obtain the right-context information from the draft, hence producing more consistent translations. We evaluated this approach using two Chinese-English translation tasks, one with 44k pairs and 1M pairs respectively. The experiments showed that our approach achieved positive improvements over the conventional NMT system: the improvements are 2.4 and 0.9 BLEU points on the small-scale and large-scale tasks, respectively.