 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Review Agent Benchmark
Mar 24, 2026Software engineering agents have shown significant promise in writing code. As AI agents permeate code writing, and generate huge volumes of code automatically -- the matter of code quality comes front and centre. As the automatically generated code gets integrated into huge code-bases -- the issue of code review and broadly quality assurance becomes important. In this paper, we take a fresh look at the problem and curate a code review dataset for AI agents to work with. Our dataset called c-CRAB (pronounced see-crab) can evaluate agents for code review tasks. Specifically given a pull-request (which could be coming from code generation agents or humans), if a code review agent produces a review, our evaluation framework can asses the reviewing capability of the code review agents. Our evaluation framework is used to evaluate the state of the art today -- the open-source PR-agent, as well as commercial code review agents from Devin, Claude Code, and Codex. Our c-CRAB dataset is systematically constructed from human reviews -- given a human review of a pull request instance we generate corresponding tests to evaluate the code review agent generated reviews. Such a benchmark construction gives us several insights. Firstly, the existing review agents taken together can solve only around 40% of the c-CRAB tasks, indicating the potential to close this gap by future research. Secondly, we observe that the agent reviews often consider different aspects from the human reviews -- indicating the potential for human-agent collaboration for code review that could be deployed in future software teams. Last but not the least, the agent generated tests from our data-set act as a held out test-suite and hence quality gate for agent generated reviews. What this will mean for future collaboration of code generation agents, test generation agents and code review agents -- remains to be investigated.
VeriGrey: Greybox Agent Validation
Mar 18, 2026Agentic AI has been a topic of great interest recently. A Large Language Model (LLM) agent involves one or more LLMs in the back-end. In the front end, it conducts autonomous decision-making by combining the LLM outputs with results obtained by invoking several external tools. The autonomous interactions with the external environment introduce critical security risks. In this paper, we present a grey-box approach to explore diverse behaviors and uncover security risks in LLM agents. Our approach VeriGrey uses the sequence of tools invoked as a feedback function to drive the testing process. This helps uncover infrequent but dangerous tool invocations that cause unexpected agent behavior. As mutation operators in the testing process, we mutate prompts to design pernicious injection prompts. This is carefully accomplished by linking the task of the agent to an injection task, so that the injection task becomes a necessary step of completing the agent functionality. Comparing our approach with a black-box baseline on the well-known AgentDojo benchmark, VeriGrey achieves 33% additional efficacy in finding indirect prompt injection vulnerabilities with a GPT-4.1 back-end. We also conduct real-world case studies with the widely used coding agent Gemini CLI, and the well-known OpenClaw personal assistant. VeriGrey finds prompts inducing several attack scenarios that could not be identified by black-box approaches. In OpenClaw, by constructing a conversation agent which employs mutational fuzz testing as needed, VeriGrey is able to discover malicious skill variants from 10 malicious skills (with 10/10= 100% success rate on the Kimi-K2.5 LLM backend, and 9/10= 90% success rate on Opus 4.6 LLM backend). This demonstrates the value of a dynamic approach like VeriGrey to test agents, and to eventually lead to an agent assurance framework.
Agentic AI for Software: thoughts from Software Engineering community
Aug 24, 2025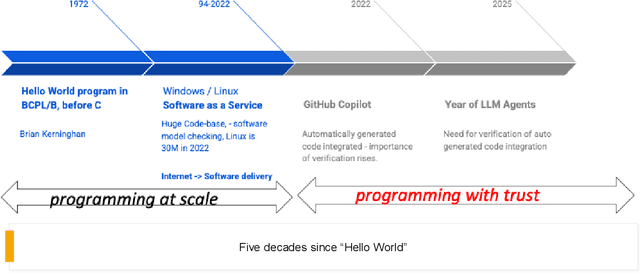
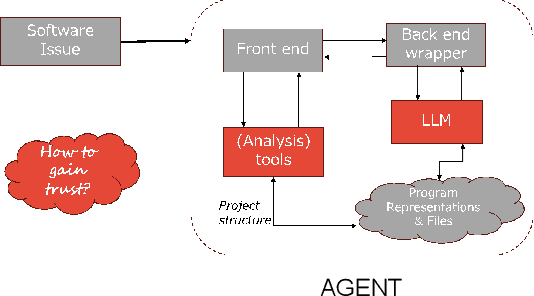
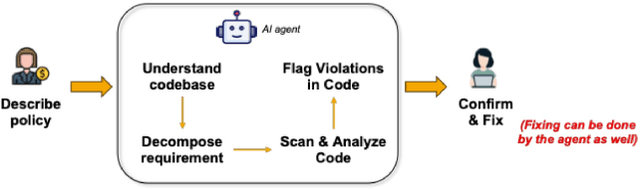
AI agents have recently shown significant promise in software engineering. Much public attention has been transfixed on the topic of code generation from Large Language Models (LLMs) via a prompt. However, software engineering is much more than programming, and AI agents go far beyond instructions given by a prompt. At the code level, common software tasks include code generation, testing, and program repair. Design level software tasks may include architecture exploration, requirements understanding, and requirements enforcement at the code level. Each of these software tasks involves micro-decisions which can be taken autonomously by an AI agent, aided by program analysis tools. This creates the vision of an AI software engineer, where the AI agent can be seen as a member of a development team. Conceptually, the key to successfully developing trustworthy agentic AI-based software workflows will be to resolve the core difficulty in software engineering - the deciphering and clarification of developer intent. Specification inference, or deciphering the intent, thus lies at the heart of many software tasks, including software maintenance and program repair. A successful deployment of agentic technology into software engineering would involve making conceptual progress in such intent inference via agents. Trusting the AI agent becomes a key aspect, as software engineering becomes more automated. Higher automation also leads to higher volume of code being automatically generated, and then integrated into code-bases. Thus to deal with this explosion, an emerging direction is AI-based verification and validation (V & V) of AI generated code. We posit that agentic software workflows in future will include such AIbased V&V.
Unified Software Engineering agent as AI Software Engineer
Jun 17, 2025The growth of Large Language Model (LLM) technology has raised expectations for automated coding. However, software engineering is more than coding and is concerned with activities including maintenance and evolution of a project. In this context, the concept of LLM agents has gained traction, which utilize LLMs as reasoning engines to invoke external tools autonomously. But is an LLM agent the same as an AI software engineer? In this paper, we seek to understand this question by developing a Unified Software Engineering agent or USEagent. Unlike existing work which builds specialized agents for specific software tasks such as testing, debugging, and repair, our goal is to build a unified agent which can orchestrate and handle multiple capabilities. This gives the agent the promise of handling complex scenarios in software development such as fixing an incomplete patch, adding new features, or taking over code written by others. We envision USEagent as the first draft of a future AI Software Engineer which can be a team member in future software development teams involving both AI and humans. To evaluate the efficacy of USEagent, we build a Unified Software Engineering bench (USEbench) comprising of myriad tasks such as coding, testing, and patching. USEbench is a judicious mixture of tasks from existing benchmarks such as SWE-bench, SWT-bench, and REPOCOD. In an evaluation on USEbench consisting of 1,271 repository-level software engineering tasks, USEagent shows improved efficacy compared to existing general agents such as OpenHands CodeActAgent. There exist gaps in the capabilities of USEagent for certain coding tasks, which provides hints on further developing the AI Software Engineer of the future.
Will AI replace Software Engineers? Hold your Breath
Feb 27, 2025Artificial Intelligence (AI) technology such as Large Language Models (LLMs) have become extremely popular in creating code. This has led to the conjecture that future software jobs will be exclusively conducted by LLMs, and the software industry will cease to exist. But software engineering is much more than producing code -- notably, \emph{maintaining} large software and keeping it reliable is a major part of software engineering, which LLMs are not yet capable of.
AI Software Engineer: Programming with Trust
Feb 19, 2025
Large Language Models (LLMs) have shown surprising proficiency in generating code snippets, promising to automate large parts of software engineering via artificial intelligence (AI). We argue that successfully deploying AI software engineers requires a level of trust equal to or even greater than the trust established by human-driven software engineering practices. The recent trend toward LLM agents offers a path toward integrating the power of LLMs to create new code with the power of analysis tools to increase trust in the code. This opinion piece comments on whether LLM agents could dominate software engineering workflows in the future and whether the focus of programming will shift from programming at scale to programming with trust.
Assured Automatic Programming via Large Language Models
Oct 24, 2024



With the advent of AI-based coding engines, it is possible to convert natural language requirements to executable code in standard programming languages. However, AI-generated code can be unreliable, and the natural language requirements driving this code may be ambiguous. In other words, the intent may not be accurately captured in the code generated from AI-coding engines like Copilot. The goal of our work is to discover the programmer intent, while generating code which conforms to the intent and a proof of this conformance. Our approach to intent discovery is powered by a novel repair engine called program-proof co-evolution, where the object of repair is a tuple (code, logical specification, test) generated by an LLM from the same natural language description. The program and the specification capture the initial operational and declarative description of intent, while the test represents a concrete, albeit partial, understanding of the intent. Our objective is to achieve consistency between the program, the specification, and the test by incrementally refining our understanding of the user intent. Reaching consistency through this repair process provides us with a formal, logical description of the intent, which is then translated back into natural language for the developer's inspection. The resultant intent description is now unambiguous, though expressed in natural language. We demonstrate how the unambiguous intent discovered through our approach increases the percentage of verifiable auto-generated programs on a recently proposed dataset in the Dafny programming language.
SpecRover: Code Intent Extraction via LLMs
Aug 07, 2024



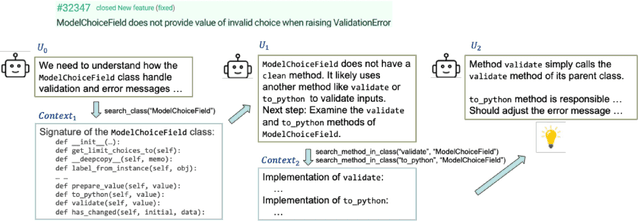
Autonomous program improvement typically involves automatically producing bug fixes and feature additions. Such program improvement can be accomplished by a combination of large language model (LLM) and program analysis capabilities, in the form of an LLM agent. Since program repair or program improvement typically requires a specification of intended behavior - specification inference can be useful for producing high quality program patches. In this work, we examine efficient and low-cost workflows for iterative specification inference within an LLM agent. Given a GitHub issue to be resolved in a software project, our goal is to conduct iterative code search accompanied by specification inference - thereby inferring intent from both the project structure and behavior. The intent thus captured is examined by a reviewer agent with the goal of vetting the patches as well as providing a measure of confidence in the vetted patches. Our approach SpecRover (AutoCodeRover-v2) is built on the open-source LLM agent AutoCodeRover. In an evaluation on the full SWE-Bench consisting of 2294 GitHub issues, it shows more than 50% improvement in efficacy over AutoCodeRover. Compared to the open-source agents available, our work shows modest cost ($0.65 per issue) in resolving an average GitHub issue in SWE-Bench lite. The production of explanation by SpecRover allows for a better "signal" to be given to the developer, on when the suggested patches can be accepted with confidence. SpecRover also seeks to demonstrate the continued importance of specification inference in automated program repair, even as program repair technologies enter the LLM era.
Automatic Programming: Large Language Models and Beyond
May 03, 2024



Automatic programming has seen increasing popularity due to the emergence of tools like GitHub Copilot which rely on Large Language Models (LLMs). At the same time, automatically generated code faces challenges during deployment due to concerns around quality and trust. In this article, we study automated coding in a general sense and study the concerns around code quality, security and related issues of programmer responsibility. These are key issues for organizations while deciding on the usage of automatically generated code. We discuss how advances in software engineering such as program repair and analysis can enable automatic programming. We conclude with a forward looking view, focusing on the programming environment of the near future, where programmers may need to switch to different roles to fully utilize the power of automatic programming. Automated repair of automatically generated programs from LLMs, can help produce higher assurance code from LLMs, along with evidence of assurance
AutoCodeRover: Autonomous Program Improvement
Apr 15, 2024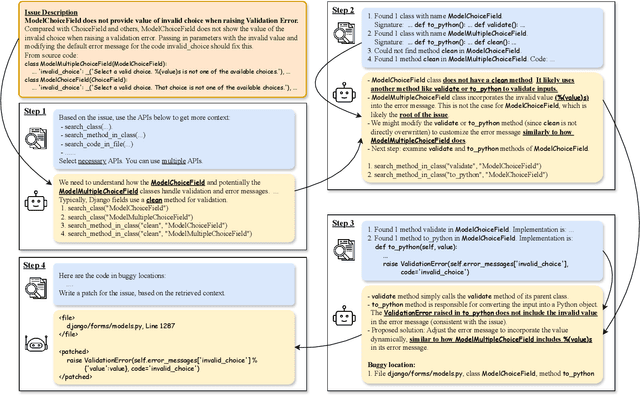


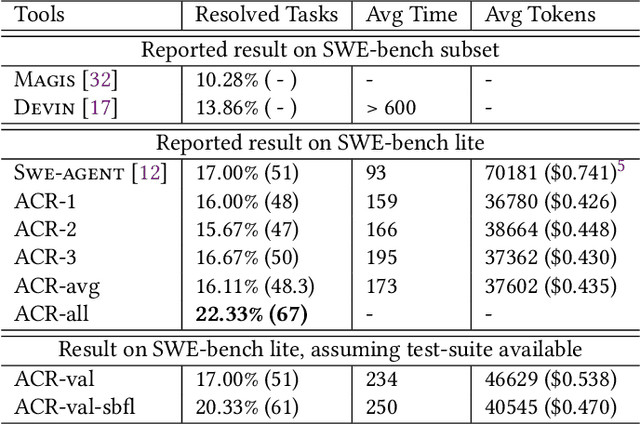
Researchers have made significant progress in automating the software development process in the past decades. Recent progress in Large Language Models (LLMs) has significantly impacted the development process, where developers can use LLM-based programming assistants to achieve automated coding. Nevertheless software engineering involves the process of program improvement apart from coding, specifically to enable software maintenance (e.g. bug fixing) and software evolution (e.g. feature additions). In this paper, we propose an automated approach for solving GitHub issues to autonomously achieve program improvement. In our approach called AutoCodeRover, LLMs are combined with sophisticated code search capabilities, ultimately leading to a program modification or patch. In contrast to recent LLM agent approaches from AI researchers and practitioners, our outlook is more software engineering oriented. We work on a program representation (abstract syntax tree) as opposed to viewing a software project as a mere collection of files. Our code search exploits the program structure in the form of classes/methods to enhance LLM's understanding of the issue's root cause, and effectively retrieve a context via iterative search. The use of spectrum based fault localization using tests, further sharpens the context, as long as a test-suite is available. Experiments on SWE-bench-lite which consists of 300 real-life GitHub issues show increased efficacy in solving GitHub issues (22-23% on SWE-bench-lite). On the full SWE-bench consisting of 2294 GitHub issues, AutoCodeRover solved around 16% of issues, which is higher than the efficacy of the recently reported AI software engineer Devin from Cognition Labs, while taking time comparable to Devin. We posit that our workflow enables autonomous software engineering, where, in future, auto-generated code from LLMs can be autonomously improved.