 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Tasks for Block-based Programming
Jul 01, 2020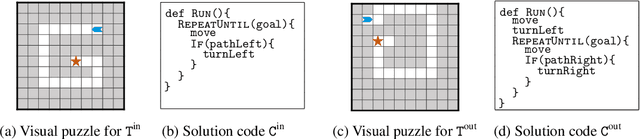
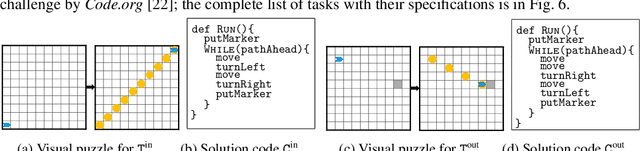
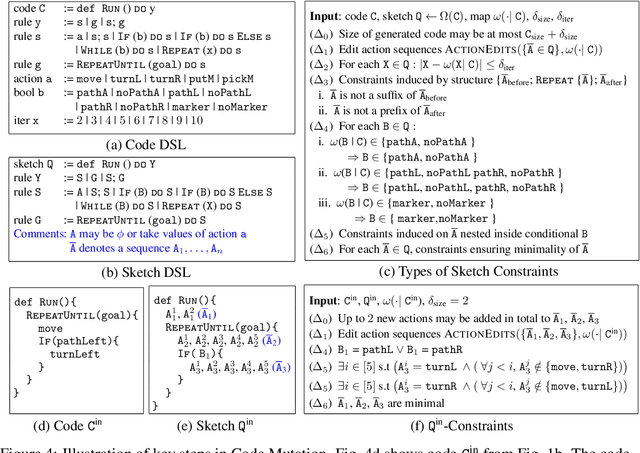

Block-based visual programming environments play a critical role in introducing computing concepts to K-12 students. One of the key pedagogical challenges in these environments is in designing new practice tasks for a student that match a desired level of difficulty and exercise specific programming concepts. In this paper, we formalize the problem of synthesizing visual programming tasks. In particular, given a reference visual task $\rm T^{in}$ and its solution code $\rm C^{in}$, we propose a novel methodology to automatically generate a set $\{(\rm T^{out}, \rm C^{out})\}$ of new tasks along with solution codes such that tasks $\rm T^{in}$ and $\rm T^{out}$ are conceptually similar but visually dissimilar. Our methodology is based on the realization that the mapping from the space of visual tasks to their solution codes is highly discontinuous; hence, directly mutating reference task $\rm T^{in}$ to generate new tasks is futile. Our task synthesis algorithm operates by first mutating code $\rm C^{in}$ to obtain a set of codes $\{\rm C^{out}\}$. Then, the algorithm performs symbolic execution over a code $\rm C^{out}$ to obtain a visual task $\rm T^{out}$; this step uses the Monte Carlo Tree Search (MCTS) procedure to guide the search in the symbolic tree. We demonstrate the effectiveness of our algorithm through an extensive empirical evaluation and user study on reference tasks taken from the \emph{Hour of the Code: Classic Maze} challenge by \emph{Code.org} and the \emph{Intro to Programming with Karel} course by \emph{CodeHS.com}.
MACER: A Modular Framework for Accelerated Compilation Error Repair
May 28, 2020


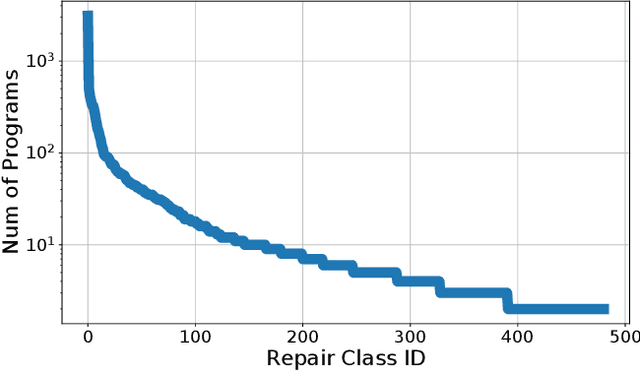
Automated compilation error repair, the problem of suggesting fixes to buggy programs that fail to compile, has generated significant interest in recent years. Apart from being a tool of general convenience, automated code repair has significant pedagogical applications for novice programmers who find compiler error messages cryptic and unhelpful. Existing approaches largely solve this problem using a blackbox-application of a heavy-duty generative learning technique, such as sequence-to-sequence prediction (TRACER) or reinforcement learning (RLAssist). Although convenient, such black-box application of learning techniques makes existing approaches bulky in terms of training time, as well as inefficient at targeting specific error types. We present MACER, a novel technique for accelerated error repair based on a modular segregation of the repair process into repair identification and repair application. MACER uses powerful yet inexpensive discriminative learning techniques such as multi-label classifiers and rankers to first identify the type of repair required and then apply the suggested repair. Experiments indicate that the fine-grained approach adopted by MACER offers not only superior error correction, but also much faster training and prediction. On a benchmark dataset of 4K buggy programs collected from actual student submissions, MACER outperforms existing methods by 20% at suggesting fixes for popular errors that exactly match the fix desired by the student. MACER is also competitive or better than existing methods at all error types -- whether popular or rare. MACER offers a training time speedup of 2x over TRACER and 800x over RLAssist, and a test time speedup of 2-4x over both.
Targeted Example Generation for Compilation Errors
Sep 02, 2019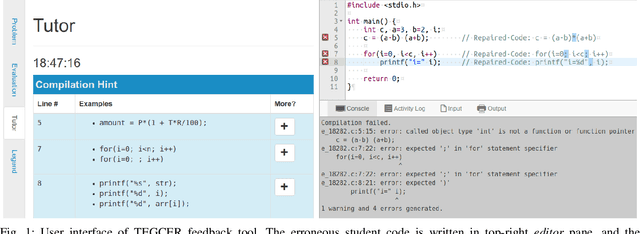
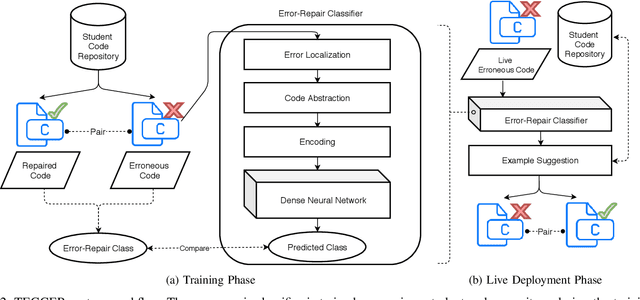

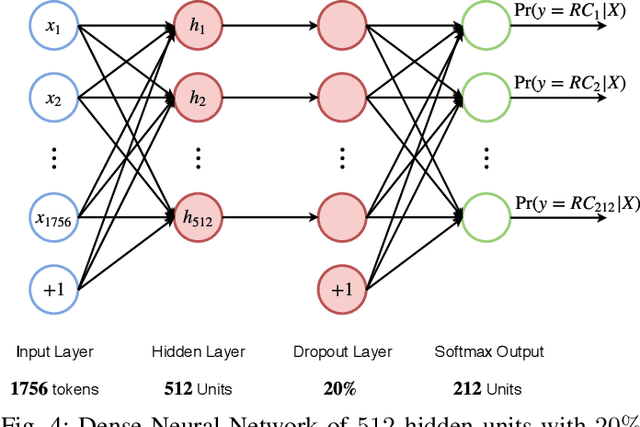
We present TEGCER, an automated feedback tool for novice programmers. TEGCER uses supervised classification to match compilation errors in new code submissions with relevant pre-existing errors, submitted by other students before. The dense neural network used to perform this classification task is trained on 15000+ error-repair code examples. The proposed model yields a test set classification Pred@3 accuracy of 97.7% across 212 error category labels. Using this model as its base, TEGCER presents students with the closest relevant examples of solutions for their specific error on demand.
Automatic Generation of Alternative Starting Positions for Simple Traditional Board Games
Nov 14, 2014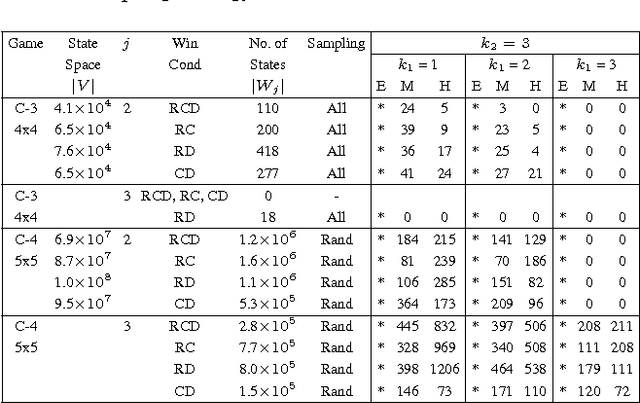

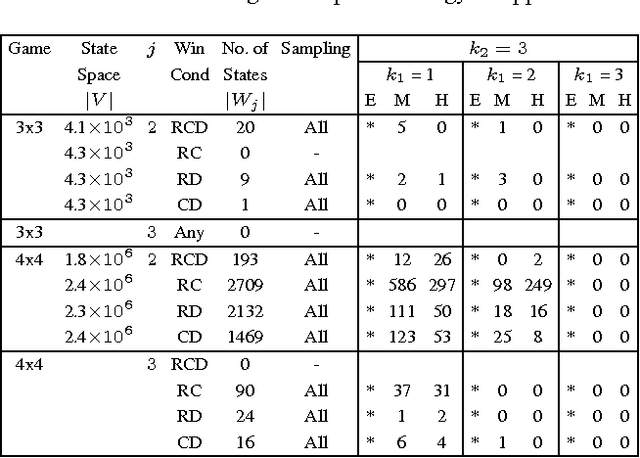
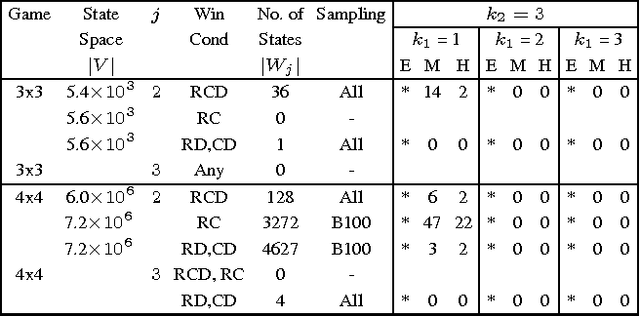
Simple board games, like Tic-Tac-Toe and CONNECT-4, play an important role not only in the development of mathematical and logical skills, but also in the emotional and social development. In this paper, we address the problem of generating targeted starting positions for such games. This can facilitate new approaches for bringing novice players to mastery, and also leads to discovery of interesting game variants. We present an approach that generates starting states of varying hardness levels for player~$1$ in a two-player board game, given rules of the board game, the desired number of steps required for player~$1$ to win, and the expertise levels of the two players. Our approach leverages symbolic methods and iterative simulation to efficiently search the extremely large state space. We present experimental results that include discovery of states of varying hardness levels for several simple grid-based board games. The presence of such states for standard game variants like $4 \times 4$ Tic-Tac-Toe opens up new games to be played that have never been played as the default start state is heavily biased.