 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Software Engineering agent as AI Software Engineer
Jun 17, 2025The growth of Large Language Model (LLM) technology has raised expectations for automated coding. However, software engineering is more than coding and is concerned with activities including maintenance and evolution of a project. In this context, the concept of LLM agents has gained traction, which utilize LLMs as reasoning engines to invoke external tools autonomously. But is an LLM agent the same as an AI software engineer? In this paper, we seek to understand this question by developing a Unified Software Engineering agent or USEagent. Unlike existing work which builds specialized agents for specific software tasks such as testing, debugging, and repair, our goal is to build a unified agent which can orchestrate and handle multiple capabilities. This gives the agent the promise of handling complex scenarios in software development such as fixing an incomplete patch, adding new features, or taking over code written by others. We envision USEagent as the first draft of a future AI Software Engineer which can be a team member in future software development teams involving both AI and humans. To evaluate the efficacy of USEagent, we build a Unified Software Engineering bench (USEbench) comprising of myriad tasks such as coding, testing, and patching. USEbench is a judicious mixture of tasks from existing benchmarks such as SWE-bench, SWT-bench, and REPOCOD. In an evaluation on USEbench consisting of 1,271 repository-level software engineering tasks, USEagent shows improved efficacy compared to existing general agents such as OpenHands CodeActAgent. There exist gaps in the capabilities of USEagent for certain coding tasks, which provides hints on further developing the AI Software Engineer of the future.
SpecRover: Code Intent Extraction via LLMs
Aug 07, 2024



Autonomous program improvement typically involves automatically producing bug fixes and feature additions. Such program improvement can be accomplished by a combination of large language model (LLM) and program analysis capabilities, in the form of an LLM agent. Since program repair or program improvement typically requires a specification of intended behavior - specification inference can be useful for producing high quality program patches. In this work, we examine efficient and low-cost workflows for iterative specification inference within an LLM agent. Given a GitHub issue to be resolved in a software project, our goal is to conduct iterative code search accompanied by specification inference - thereby inferring intent from both the project structure and behavior. The intent thus captured is examined by a reviewer agent with the goal of vetting the patches as well as providing a measure of confidence in the vetted patches. Our approach SpecRover (AutoCodeRover-v2) is built on the open-source LLM agent AutoCodeRover. In an evaluation on the full SWE-Bench consisting of 2294 GitHub issues, it shows more than 50% improvement in efficacy over AutoCodeRover. Compared to the open-source agents available, our work shows modest cost ($0.65 per issue) in resolving an average GitHub issue in SWE-Bench lite. The production of explanation by SpecRover allows for a better "signal" to be given to the developer, on when the suggested patches can be accepted with confidence. SpecRover also seeks to demonstrate the continued importance of specification inference in automated program repair, even as program repair technologies enter the LLM era.
AutoCodeRover: Autonomous Program Improvement
Apr 15, 2024Researchers have made significant progress in automating the software development process in the past decades. Recent progress in Large Language Models (LLMs) has significantly impacted the development process, where developers can use LLM-based programming assistants to achieve automated coding. Nevertheless software engineering involves the process of program improvement apart from coding, specifically to enable software maintenance (e.g. bug fixing) and software evolution (e.g. feature additions). In this paper, we propose an automated approach for solving GitHub issues to autonomously achieve program improvement. In our approach called AutoCodeRover, LLMs are combined with sophisticated code search capabilities, ultimately leading to a program modification or patch. In contrast to recent LLM agent approaches from AI researchers and practitioners, our outlook is more software engineering oriented. We work on a program representation (abstract syntax tree) as opposed to viewing a software project as a mere collection of files. Our code search exploits the program structure in the form of classes/methods to enhance LLM's understanding of the issue's root cause, and effectively retrieve a context via iterative search. The use of spectrum based fault localization using tests, further sharpens the context, as long as a test-suite is available. Experiments on SWE-bench-lite which consists of 300 real-life GitHub issues show increased efficacy in solving GitHub issues (22-23% on SWE-bench-lite). On the full SWE-bench consisting of 2294 GitHub issues, AutoCodeRover solved around 16% of issues, which is higher than the efficacy of the recently reported AI software engineer Devin from Cognition Labs, while taking time comparable to Devin. We posit that our workflow enables autonomous software engineering, where, in future, auto-generated code from LLMs can be autonomously improved.
Data Distribution Dynamics in Real-World WiFi-Based Patient Activity Monitoring for Home Healthcare
Feb 03, 2024This paper examines the application of WiFi signals for real-world monitoring of daily activities in home healthcare scenarios. While the state-of-the-art of WiFi-based activity recognition is promising in lab environments, challenges arise in real-world settings due to environmental, subject, and system configuration variables, affecting accuracy and adaptability. The research involved deploying systems in various settings and analyzing data shifts. It aims to guide realistic development of robust, context-aware WiFi sensing systems for elderly care. The findings suggest a shift in WiFi-based activity sensing, bridging the gap between academic research and practical applications, enhancing life quality through technology.
PPG-based Heart Rate Estimation with Efficient Sensor Sampling and Learning Models
Mar 23, 2023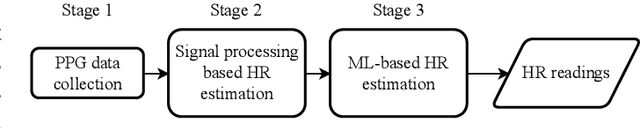



Recent studies showed that Photoplethysmography (PPG) sensors embedded in wearable devices can estimate heart rate (HR) with high accuracy. However, despite of prior research efforts, applying PPG sensor based HR estimation to embedded devices still faces challenges due to the energy-intensive high-frequency PPG sampling and the resource-intensive machine-learning models. In this work, we aim to explore HR estimation techniques that are more suitable for lower-power and resource-constrained embedded devices. More specifically, we seek to design techniques that could provide high-accuracy HR estimation with low-frequency PPG sampling, small model size, and fast inference time. First, we show that by combining signal processing and ML, it is possible to reduce the PPG sampling frequency from 125 Hz to only 25 Hz while providing higher HR estimation accuracy. This combination also helps to reduce the ML model feature size, leading to smaller models. Additionally, we present a comprehensive analysis on different ML models and feature sizes to compare their accuracy, model size, and inference time. The models explored include Decision Tree (DT), Random Forest (RF), K-nearest neighbor (KNN), Support vector machines (SVM), and Multi-layer perceptron (MLP). Experiments were conducted using both a widely-utilized dataset and our self-collected dataset. The experimental results show that our method by combining signal processing and ML had only 5% error for HR estimation using low-frequency PPG data. Moreover, our analysis showed that DT models with 10 to 20 input features usually have good accuracy, while are several magnitude smaller in model sizes and faster in inference time.
Efficient and Direct Inference of Heart Rate Variability using Both Signal Processing and Machine Learning
Mar 23, 2023



Heart Rate Variability (HRV) measures the variation of the time between consecutive heartbeats and is a major indicator of physical and mental health. Recent research has demonstrated that photoplethysmography (PPG) sensors can be used to infer HRV. However, many prior studies had high errors because they only employed signal processing or machine learning (ML), or because they indirectly inferred HRV, or because there lacks large training datasets. Many prior studies may also require large ML models. The low accuracy and large model sizes limit their applications to small embedded devices and potential future use in healthcare. To address the above issues, we first collected a large dataset of PPG signals and HRV ground truth. With this dataset, we developed HRV models that combine signal processing and ML to directly infer HRV. Evaluation results show that our method had errors between 3.5% to 25.7% and outperformed signal-processing-only and ML-only methods. We also explored different ML models, which showed that Decision Trees and Multi-level Perceptrons have 13.0% and 9.1% errors on average with models at most hundreds of KB and inference time less than 1ms. Hence, they are more suitable for small embedded devices and potentially enable the future use of PPG-based HRV monitoring in healthcare.