 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysically Inspired Dense Fusion Networks for Relighting
May 05, 2021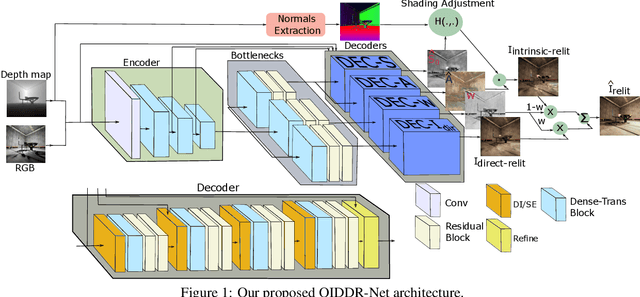

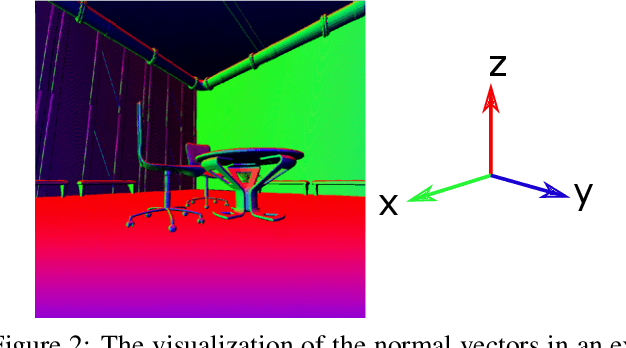

Image relighting has emerged as a problem of significant research interest inspired by augmented reality applications. Physics-based traditional methods, as well as black box deep learning models, have been developed. The existing deep networks have exploited training to achieve a new state of the art; however, they may perform poorly when training is limited or does not represent problem phenomenology, such as the addition or removal of dense shadows. We propose a model which enriches neural networks with physical insight. More precisely, our method generates the relighted image with new illumination settings via two different strategies and subsequently fuses them using a weight map (w). In the first strategy, our model predicts the material reflectance parameters (albedo) and illumination/geometry parameters of the scene (shading) for the relit image (we refer to this strategy as intrinsic image decomposition (IID)). The second strategy is solely based on the black box approach, where the model optimizes its weights based on the ground-truth images and the loss terms in the training stage and generates the relit output directly (we refer to this strategy as direct). While our proposed method applies to both one-to-one and any-to-any relighting problems, for each case we introduce problem-specific components that enrich the model performance: 1) For one-to-one relighting we incorporate normal vectors of the surfaces in the scene to adjust gloss and shadows accordingly in the image. 2) For any-to-any relighting, we propose an additional multiscale block to the architecture to enhance feature extraction. Experimental results on the VIDIT 2020 and the VIDIT 2021 dataset (used in the NTIRE 2021 relighting challenge) reveals that our proposal can outperform many state-of-the-art methods in terms of well-known fidelity metrics and perceptual loss.
NTIRE 2020 Challenge on NonHomogeneous Dehazing
May 07, 2020
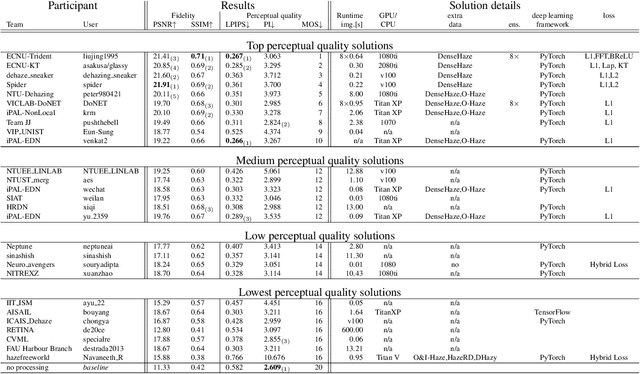
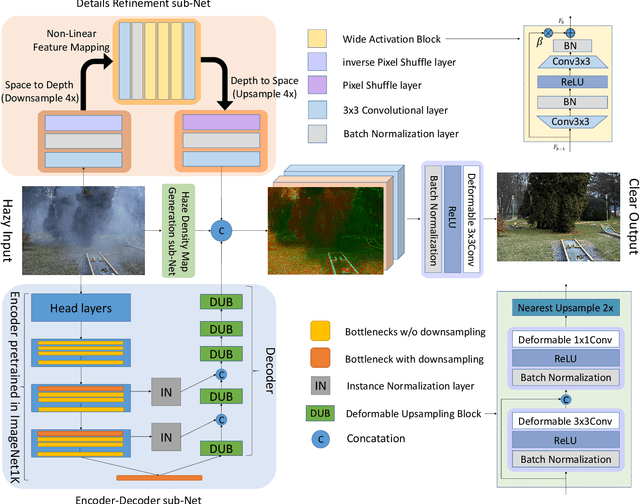
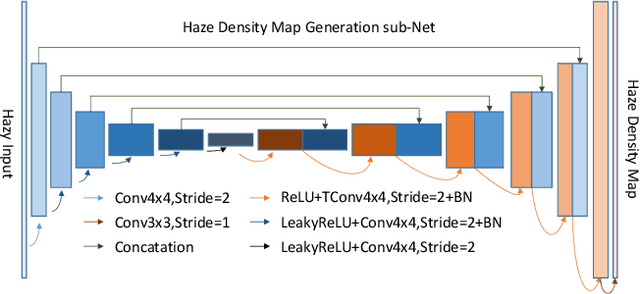
This paper reviews the NTIRE 2020 Challenge on NonHomogeneous Dehazing of images (restoration of rich details in hazy image). We focus on the proposed solutions and their results evaluated on NH-Haze, a novel dataset consisting of 55 pairs of real haze free and nonhomogeneous hazy images recorded outdoor. NH-Haze is the first realistic nonhomogeneous haze dataset that provides ground truth images. The nonhomogeneous haze has been produced using a professional haze generator that imitates the real conditions of haze scenes. 168 participants registered in the challenge and 27 teams competed in the final testing phase. The proposed solutions gauge the state-of-the-art in image dehazing.
Deep MR Brain Image Super-Resolution Using Spatio-Structural Priors
Sep 10, 2019
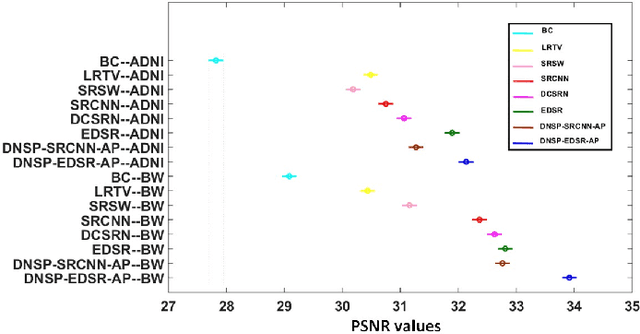


High resolution Magnetic Resonance (MR) images are desired for accurate diagnostics. In practice, image resolution is restricted by factors like hardware and processing constraints. Recently, deep learning methods have been shown to produce compelling state-of-the-art results for image enhancement/super-resolution. Paying particular attention to desired hi-resolution MR image structure, we propose a new regularized network that exploits image priors, namely a low-rank structure and a sharpness prior to enhance deep MR image super-resolution (SR). Our contributions are then incorporating these priors in an analytically tractable fashion \color{black} as well as towards a novel prior guided network architecture that accomplishes the super-resolution task. This is particularly challenging for the low rank prior since the rank is not a differentiable function of the image matrix(and hence the network parameters), an issue we address by pursuing differentiable approximations of the rank. Sharpness is emphasized by the variance of the Laplacian which we show can be implemented by a fixed feedback layer at the output of the network. As a key extension, we modify the fixed feedback (Laplacian) layer by learning a new set of training data driven filters that are optimized for enhanced sharpness. Experiments performed on publicly available MR brain image databases and comparisons against existing state-of-the-art methods show that the proposed prior guided network offers significant practical gains in terms of improved SNR/image quality measures. Because our priors are on output images, the proposed method is versatile and can be combined with a wide variety of existing network architectures to further enhance their performance.
Adaptive Transform Domain Image Super-resolution Via Orthogonally Regularized Deep Networks
Apr 22, 2019

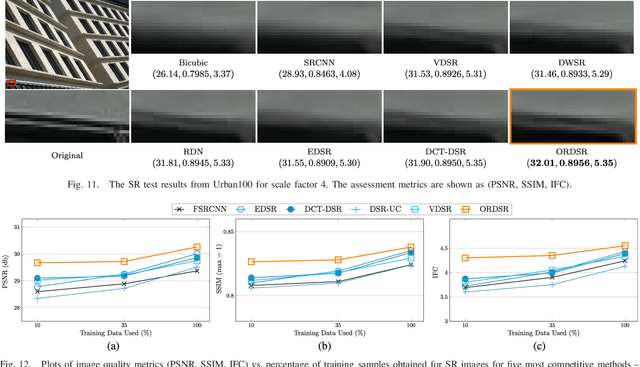

Deep learning methods, in particular, trained Convolutional Neural Networks (CNN) have recently been shown to produce compelling results for single image Super-Resolution (SR). Invariably, a CNN is learned to map the Low Resolution (LR) image to its corresponding High Resolution (HR) version in the spatial domain. We propose a novel network structure for learning the SR mapping function in an image transform domain, specifically the Discrete Cosine Transform (DCT). As the first contribution, we show that DCT can be integrated into the network structure as a Convolutional DCT (CDCT) layer. With the CDCT layer, we construct the DCT Deep SR (DCT-DSR) network. We further extend the DCT-DSR to allow the CDCT layer to become trainable (i.e., optimizable). Because this layer represents an image transform, we enforce pairwise orthogonality constraints and newly formulated complexity order constraints on the individual basis functions/filters. This Orthogonally Regularized Deep SR network (ORDSR) simplifies the SR task by taking advantage of image transform domain while adapting the design of transform basis to the training image set. Experimental results show ORDSR achieves state-of-the-art SR image quality with fewer parameters than most of the deep CNN methods. A particular success of ORDSR is in overcoming the artifacts introduced by bicubic interpolation. A key burden of deep SR has been identified as the requirement of generous training LR and HR image pairs; ORSDR exhibits a much more graceful degradation as training size is reduced with significant benefits in the regime of limited training. Analysis of memory and computation requirements confirms that ORDSR can allow for a more efficient network with faster inference.
Prior Information Guided Regularized Deep Learning for Cell Nucleus Detection
Jan 21, 2019
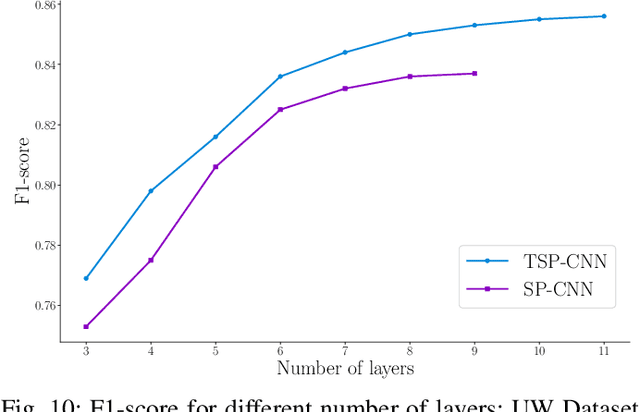
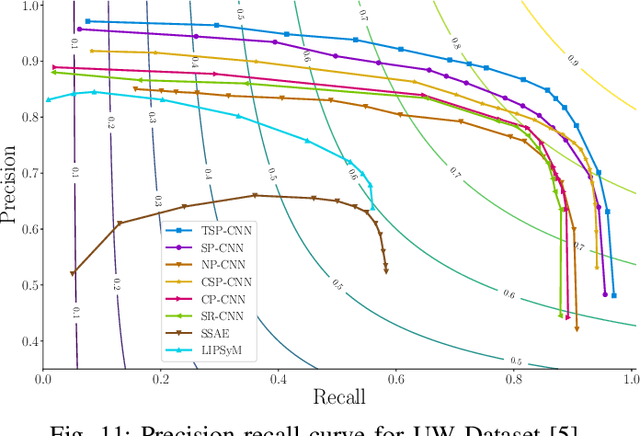
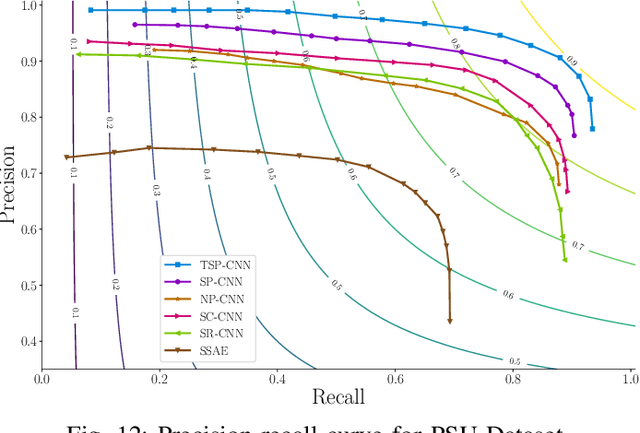
Cell nuclei detection is a challenging research topic because of limitations in cellular image quality and diversity of nuclear morphology, i.e. varying nuclei shapes, sizes, and overlaps between multiple cell nuclei. This has been a topic of enduring interest with promising recent success shown by deep learning methods. These methods train Convolutional Neural Networks (CNNs) with a training set of input images and known, labeled nuclei locations. Many such methods are supplemented by spatial or morphological processing. Using a set of canonical cell nuclei shapes, prepared with the help of a domain expert, we develop a new approach that we call Shape Priors with Convolutional Neural Networks (SP-CNN). We further extend the network to introduce a shape prior (SP) layer and then allowing it to become trainable (i.e. optimizable). We call this network tunable SP-CNN (TSP-CNN). In summary, we present new network structures that can incorporate 'expected behavior' of nucleus shapes via two components: learnable layers that perform the nucleus detection and a fixed processing part that guides the learning with prior information. Analytically, we formulate two new regularization terms that are targeted at: 1) learning the shapes, 2) reducing false positives while simultaneously encouraging detection inside the cell nucleus boundary. Experimental results on two challenging datasets reveal that the proposed SP-CNN and TSP-CNN can outperform state-of-the-art alternatives.
* Accepted for Publication
Deep MR Image Super-Resolution Using Structural Priors
Sep 10, 2018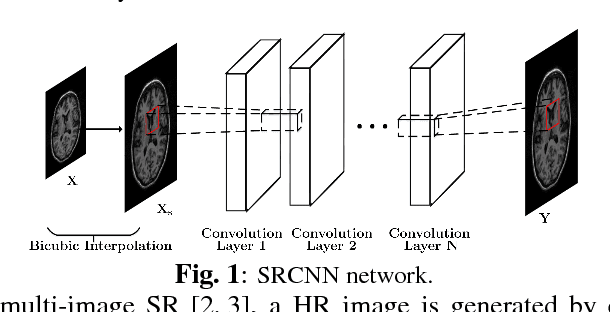
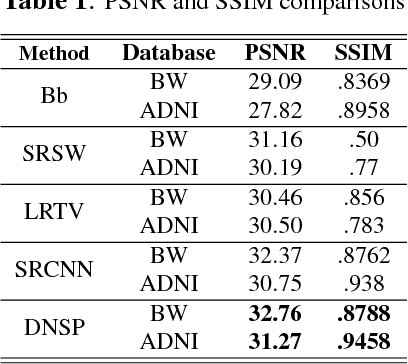


High resolution magnetic resonance (MR) images are desired for accurate diagnostics. In practice, image resolution is restricted by factors like hardware, cost and processing constraints. Recently, deep learning methods have been shown to produce compelling state of the art results for image super-resolution. Paying particular attention to desired hi-resolution MR image structure, we propose a new regularized network that exploits image priors, namely a low-rank structure and a sharpness prior to enhance deep MR image superresolution. Our contributions are then incorporating these priors in an analytically tractable fashion in the learning of a convolutional neural network (CNN) that accomplishes the super-resolution task. This is particularly challenging for the low rank prior, since the rank is not a differentiable function of the image matrix (and hence the network parameters), an issue we address by pursuing differentiable approximations of the rank. Sharpness is emphasized by the variance of the Laplacian which we show can be implemented by a fixed {\em feedback} layer at the output of the network. Experiments performed on two publicly available MR brain image databases exhibit promising results particularly when training imagery is limited.
Deep Networks with Shape Priors for Nucleus Detection
Jun 29, 2018
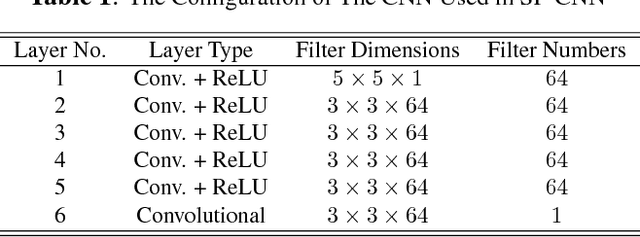

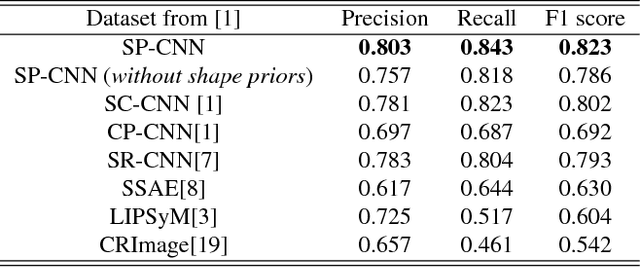
Detection of cell nuclei in microscopic images is a challenging research topic, because of limitations in cellular image quality and diversity of nuclear morphology, i.e. varying nuclei shapes, sizes, and overlaps between multiple cell nuclei. This has been a topic of enduring interest with promising recent success shown by deep learning methods. These methods train for example convolutional neural networks (CNNs) with a training set of input images and known, labeled nuclei locations. Many of these methods are supplemented by spatial or morphological processing. We develop a new approach that we call Shape Priors with Convolutional Neural Networks (SP-CNN) to perform significantly enhanced nuclei detection. A set of canonical shapes is prepared with the help of a domain expert. Subsequently, we present a new network structure that can incorporate `expected behavior' of nucleus shapes via two components: {\em learnable} layers that perform the nucleus detection and a {\em fixed} processing part that guides the learning with prior information. Analytically, we formulate a new regularization term that is targeted at penalizing false positives while simultaneously encouraging detection inside cell nucleus boundary. Experimental results on a challenging dataset reveal that SP-CNN is competitive with or outperforms several state-of-the-art methods.
Deep Network for Simultaneous Decomposition and Classification in UWB-SAR Imagery
Feb 22, 2018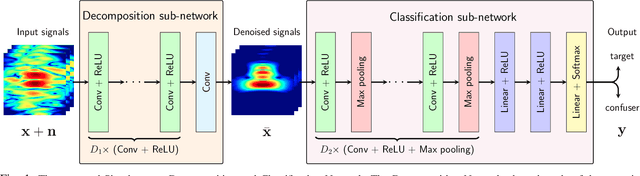
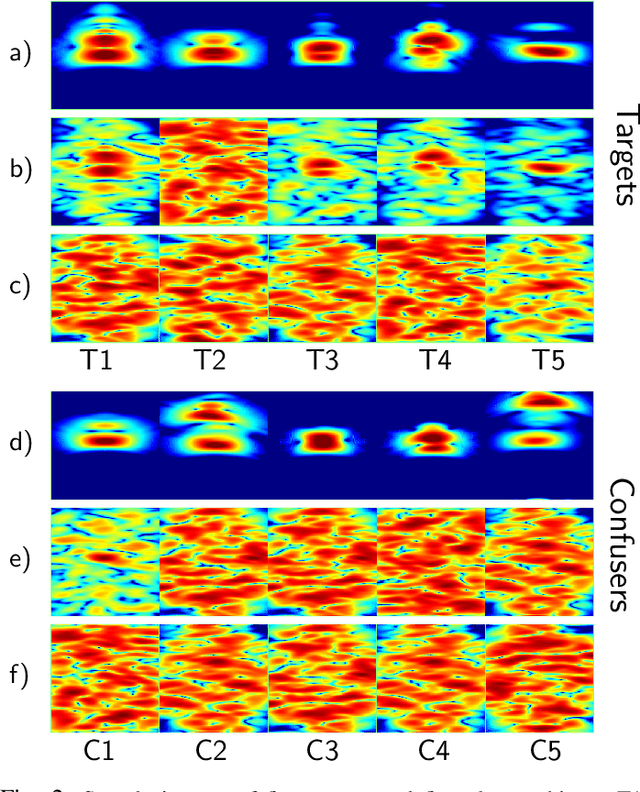
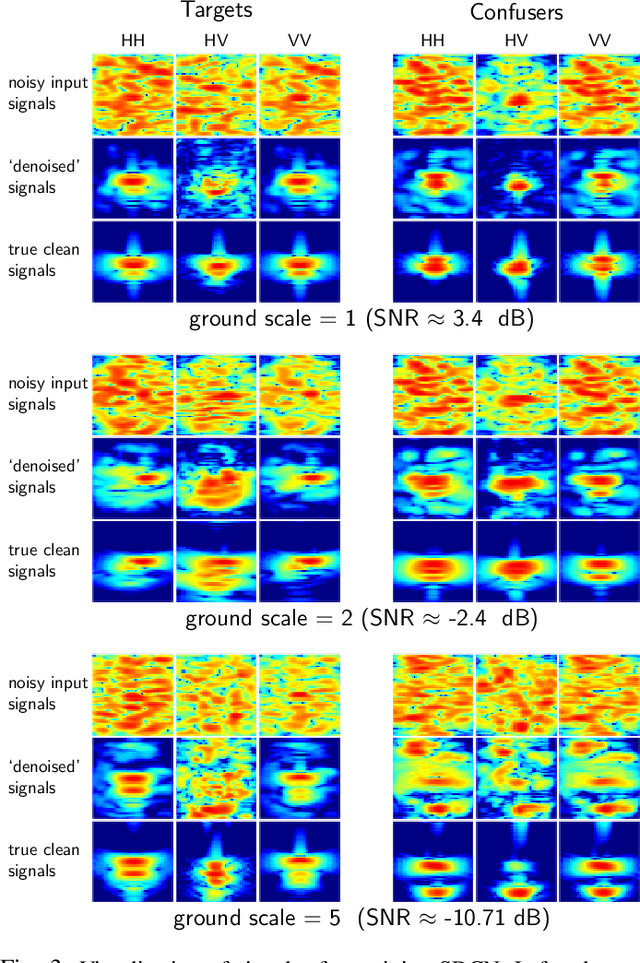
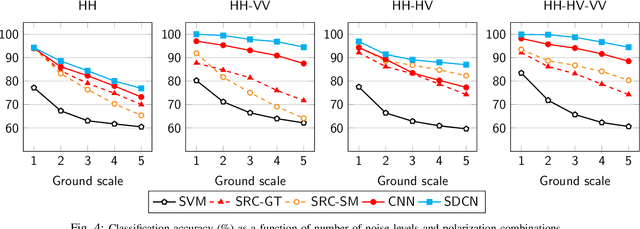
Classifying buried and obscured targets of interest from other natural and manmade clutter objects in the scene is an important problem for the U.S. Army. Targets of interest are often represented by signals captured using low-frequency (UHF to L-band) ultra-wideband (UWB) synthetic aperture radar (SAR) technology. This technology has been used in various applications, including ground penetration and sensing-through-the-wall. However, the technology still faces a significant issues regarding low-resolution SAR imagery in this particular frequency band, low radar cross sections (RCS), small objects compared to radar signal wavelengths, and heavy interference. The classification problem has been firstly, and partially, addressed by sparse representation-based classification (SRC) method which can extract noise from signals and exploit the cross-channel information. Despite providing potential results, SRC-related methods have drawbacks in representing nonlinear relations and dealing with larger training sets. In this paper, we propose a Simultaneous Decomposition and Classification Network (SDCN) to alleviate noise inferences and enhance classification accuracy. The network contains two jointly trained sub-networks: the decomposition sub-network handles denoising, while the classification sub-network discriminates targets from confusers. Experimental results show significant improvements over a network without decomposition and SRC-related methods.
Deep Image Super Resolution via Natural Image Priors
Feb 08, 2018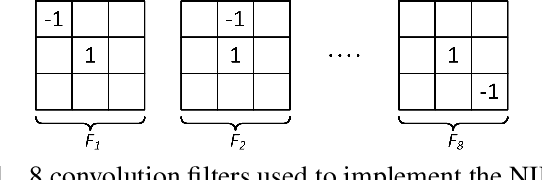

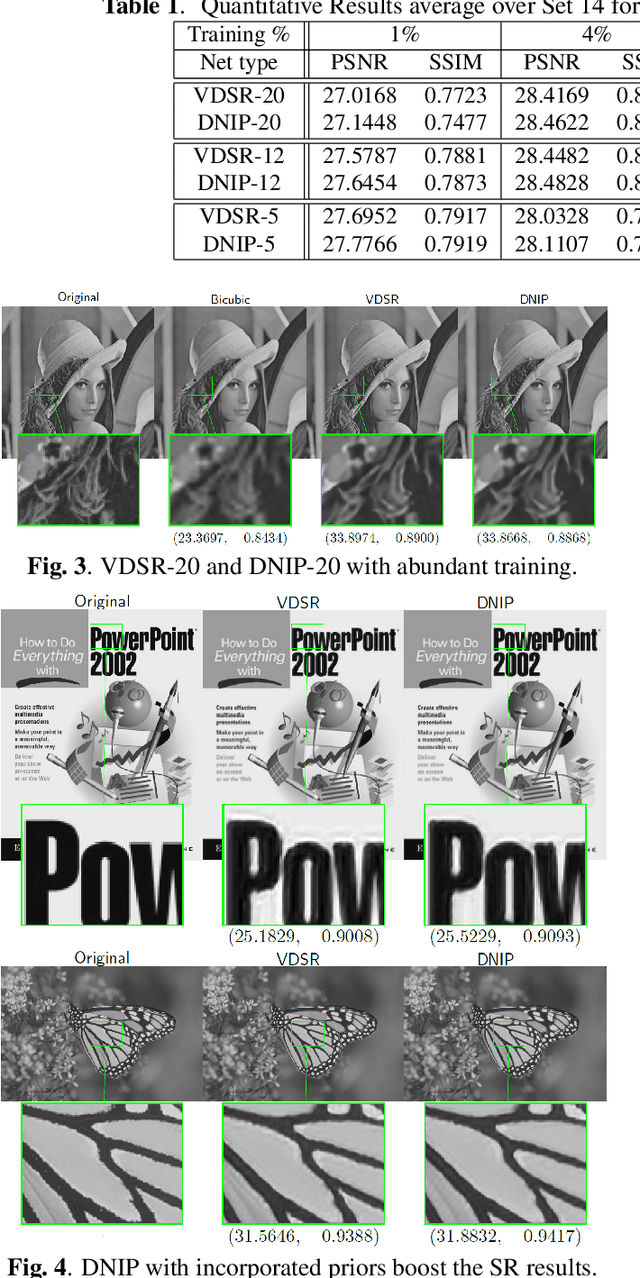

Single image super-resolution (SR) via deep learning has recently gained significant attention in the literature. Convolutional neural networks (CNNs) are typically learned to represent the mapping between low-resolution (LR) and high-resolution (HR) images/patches with the help of training examples. Most existing deep networks for SR produce high quality results when training data is abundant. However, their performance degrades sharply when training is limited. We propose to regularize deep structures with prior knowledge about the images so that they can capture more structural information from the same limited data. In particular, we incorporate in a tractable fashion within the CNN framework, natural image priors which have shown to have much recent success in imaging and vision inverse problems. Experimental results show that the proposed deep network with natural image priors is particularly effective in training starved regimes.
Orthogonally Regularized Deep Networks For Image Super-resolution
Feb 06, 2018

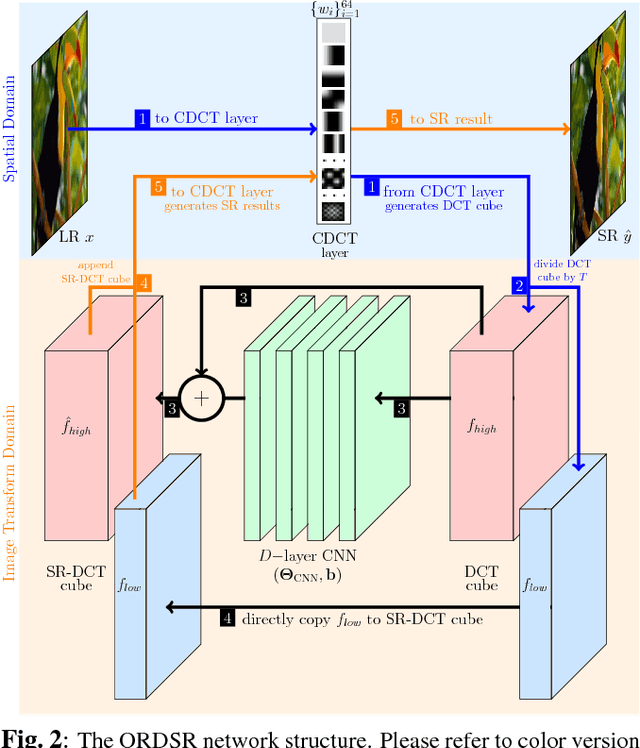

Deep learning methods, in particular trained Convolutional Neural Networks (CNNs) have recently been shown to produce compelling state-of-the-art results for single image Super-Resolution (SR). Invariably, a CNN is learned to map the low resolution (LR) image to its corresponding high resolution (HR) version in the spatial domain. Aiming for faster inference and more efficient solutions than solving the SR problem in the spatial domain, we propose a novel network structure for learning the SR mapping function in an image transform domain, specifically the Discrete Cosine Transform (DCT). As a first contribution, we show that DCT can be integrated into the network structure as a Convolutional DCT (CDCT) layer. We further extend the network to allow the CDCT layer to become trainable (i.e. optimizable). Because this layer represents an image transform, we enforce pairwise orthogonality constraints on the individual basis functions/filters. This Orthogonally Regularized Deep SR network (ORDSR) simplifies the SR task by taking advantage of image transform domain while adapting the design of transform basis to the training image set.