 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Transform Domain Image Super-resolution Via Orthogonally Regularized Deep Networks
Apr 22, 2019

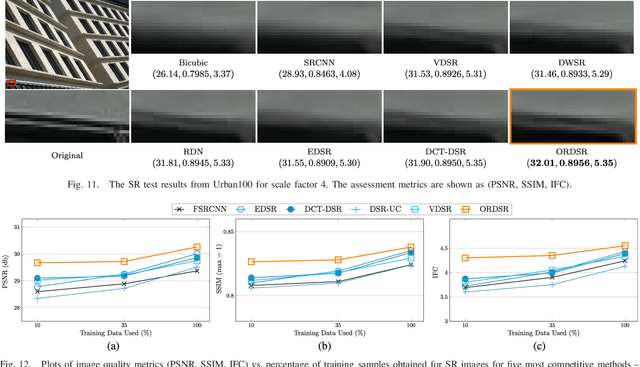

Deep learning methods, in particular, trained Convolutional Neural Networks (CNN) have recently been shown to produce compelling results for single image Super-Resolution (SR). Invariably, a CNN is learned to map the Low Resolution (LR) image to its corresponding High Resolution (HR) version in the spatial domain. We propose a novel network structure for learning the SR mapping function in an image transform domain, specifically the Discrete Cosine Transform (DCT). As the first contribution, we show that DCT can be integrated into the network structure as a Convolutional DCT (CDCT) layer. With the CDCT layer, we construct the DCT Deep SR (DCT-DSR) network. We further extend the DCT-DSR to allow the CDCT layer to become trainable (i.e., optimizable). Because this layer represents an image transform, we enforce pairwise orthogonality constraints and newly formulated complexity order constraints on the individual basis functions/filters. This Orthogonally Regularized Deep SR network (ORDSR) simplifies the SR task by taking advantage of image transform domain while adapting the design of transform basis to the training image set. Experimental results show ORDSR achieves state-of-the-art SR image quality with fewer parameters than most of the deep CNN methods. A particular success of ORDSR is in overcoming the artifacts introduced by bicubic interpolation. A key burden of deep SR has been identified as the requirement of generous training LR and HR image pairs; ORSDR exhibits a much more graceful degradation as training size is reduced with significant benefits in the regime of limited training. Analysis of memory and computation requirements confirms that ORDSR can allow for a more efficient network with faster inference.
Deep Image Super Resolution via Natural Image Priors
Feb 08, 2018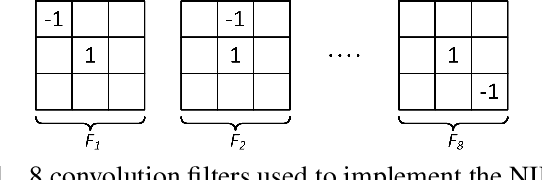

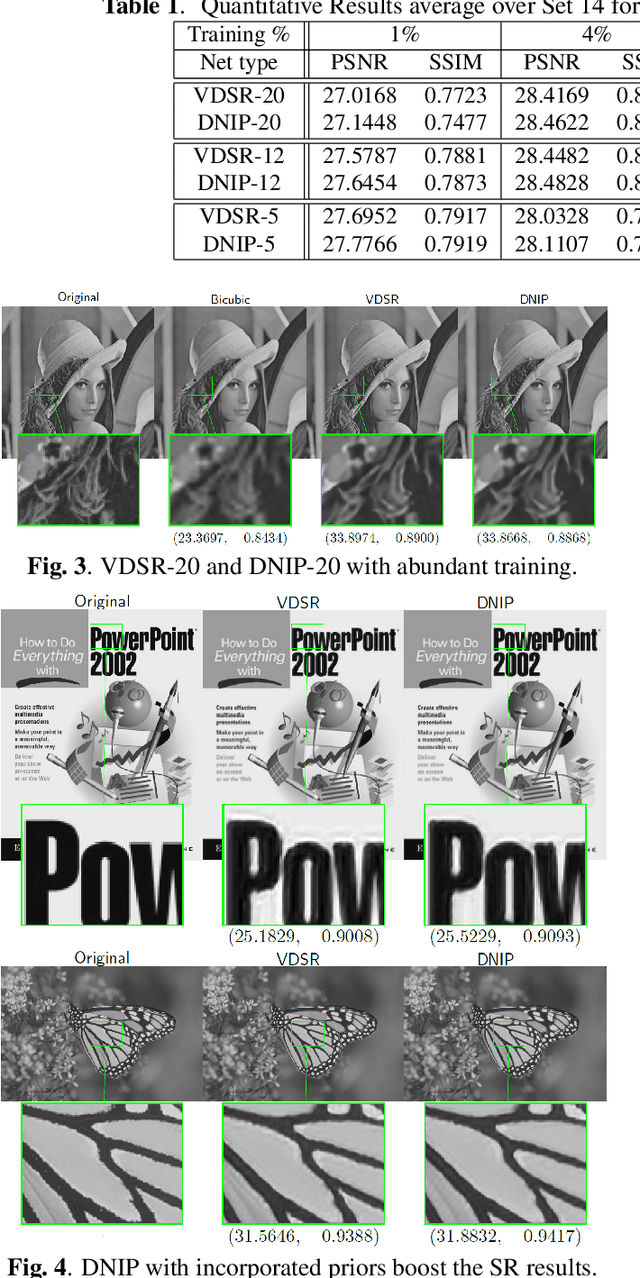

Single image super-resolution (SR) via deep learning has recently gained significant attention in the literature. Convolutional neural networks (CNNs) are typically learned to represent the mapping between low-resolution (LR) and high-resolution (HR) images/patches with the help of training examples. Most existing deep networks for SR produce high quality results when training data is abundant. However, their performance degrades sharply when training is limited. We propose to regularize deep structures with prior knowledge about the images so that they can capture more structural information from the same limited data. In particular, we incorporate in a tractable fashion within the CNN framework, natural image priors which have shown to have much recent success in imaging and vision inverse problems. Experimental results show that the proposed deep network with natural image priors is particularly effective in training starved regimes.
Orthogonally Regularized Deep Networks For Image Super-resolution
Feb 06, 2018

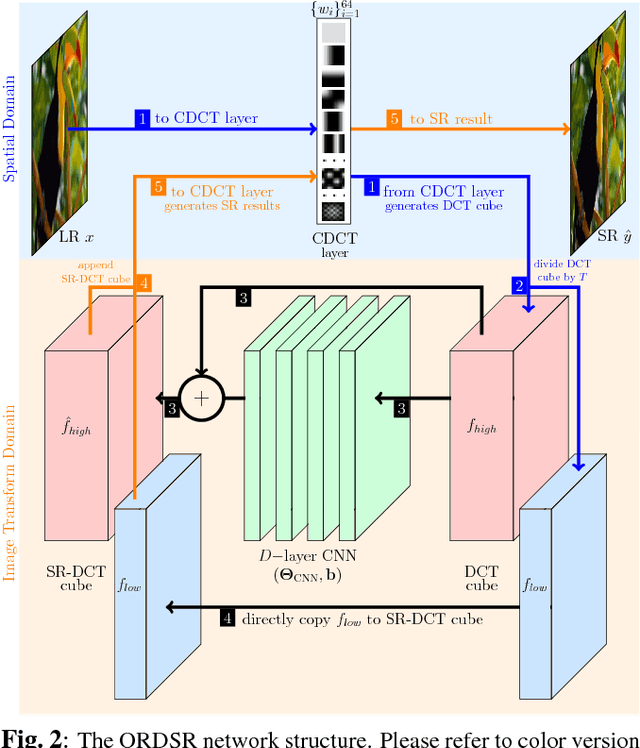

Deep learning methods, in particular trained Convolutional Neural Networks (CNNs) have recently been shown to produce compelling state-of-the-art results for single image Super-Resolution (SR). Invariably, a CNN is learned to map the low resolution (LR) image to its corresponding high resolution (HR) version in the spatial domain. Aiming for faster inference and more efficient solutions than solving the SR problem in the spatial domain, we propose a novel network structure for learning the SR mapping function in an image transform domain, specifically the Discrete Cosine Transform (DCT). As a first contribution, we show that DCT can be integrated into the network structure as a Convolutional DCT (CDCT) layer. We further extend the network to allow the CDCT layer to become trainable (i.e. optimizable). Because this layer represents an image transform, we enforce pairwise orthogonality constraints on the individual basis functions/filters. This Orthogonally Regularized Deep SR network (ORDSR) simplifies the SR task by taking advantage of image transform domain while adapting the design of transform basis to the training image set.
Sparsity-based Color Image Super Resolution via Exploiting Cross Channel Constraints
Oct 04, 2016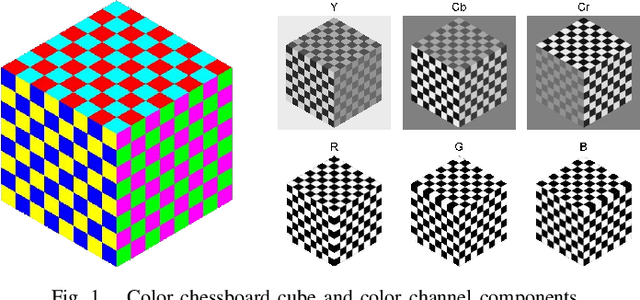
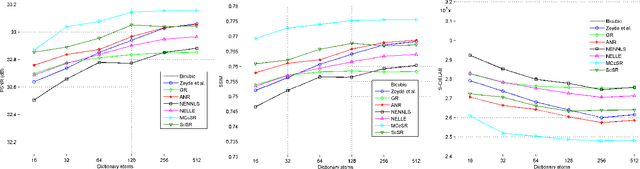


Sparsity constrained single image super-resolution (SR) has been of much recent interest. A typical approach involves sparsely representing patches in a low-resolution (LR) input image via a dictionary of example LR patches, and then using the coefficients of this representation to generate the high-resolution (HR) output via an analogous HR dictionary. However, most existing sparse representation methods for super resolution focus on the luminance channel information and do not capture interactions between color channels. In this work, we extend sparsity based super-resolution to multiple color channels by taking color information into account. Edge similarities amongst RGB color bands are exploited as cross channel correlation constraints. These additional constraints lead to a new optimization problem which is not easily solvable; however, a tractable solution is proposed to solve it efficiently. Moreover, to fully exploit the complementary information among color channels, a dictionary learning method is also proposed specifically to learn color dictionaries that encourage edge similarities. Merits of the proposed method over state of the art are demonstrated both visually and quantitatively using image quality metrics.
Adaptive matching pursuit for sparse signal recovery
Sep 12, 2016


Spike and Slab priors have been of much recent interest in signal processing as a means of inducing sparsity in Bayesian inference. Applications domains that benefit from the use of these priors include sparse recovery, regression and classification. It is well-known that solving for the sparse coefficient vector to maximize these priors results in a hard non-convex and mixed integer programming problem. Most existing solutions to this optimization problem either involve simplifying assumptions/relaxations or are computationally expensive. We propose a new greedy and adaptive matching pursuit (AMP) algorithm to directly solve this hard problem. Essentially, in each step of the algorithm, the set of active elements would be updated by either adding or removing one index, whichever results in better improvement. In addition, the intermediate steps of the algorithm are calculated via an inexpensive Cholesky decomposition which makes the algorithm much faster. Results on simulated data sets as well as real-world image recovery challenges confirm the benefits of the proposed AMP, particularly in providing a superior cost-quality trade-off over existing alternatives.
ICR: Iterative Convex Refinement for Sparse Signal Recovery Using Spike and Slab Priors
Feb 16, 2015


In this letter, we address sparse signal recovery using spike and slab priors. In particular, we focus on a Bayesian framework where sparsity is enforced on reconstruction coefficients via probabilistic priors. The optimization resulting from spike and slab prior maximization is known to be a hard non-convex problem, and existing solutions involve simplifying assumptions and/or relaxations. We propose an approach called Iterative Convex Refinement (ICR) that aims to solve the aforementioned optimization problem directly allowing for greater generality in the sparse structure. Essentially, ICR solves a sequence of convex optimization problems such that sequence of solutions converges to a sub-optimal solution of the original hard optimization problem. We propose two versions of our algorithm: a.) an unconstrained version, and b.) with a non-negativity constraint on sparse coefficients, which may be required in some real-world problems. Experimental validation is performed on both synthetic data and for a real-world image recovery problem, which illustrates merits of ICR over state of the art alternatives.
DFDL: Discriminative Feature-oriented Dictionary Learning for Histopathological Image Classification
Feb 03, 2015
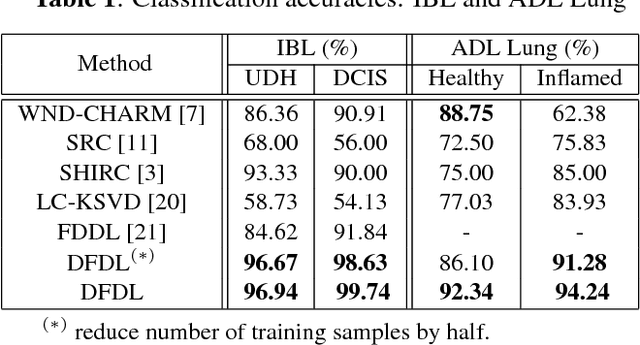
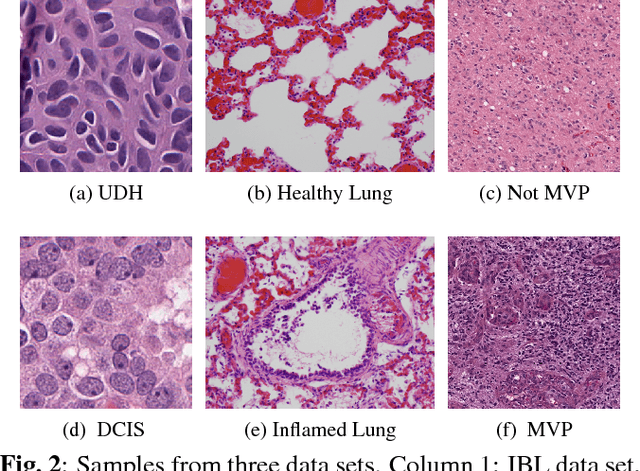
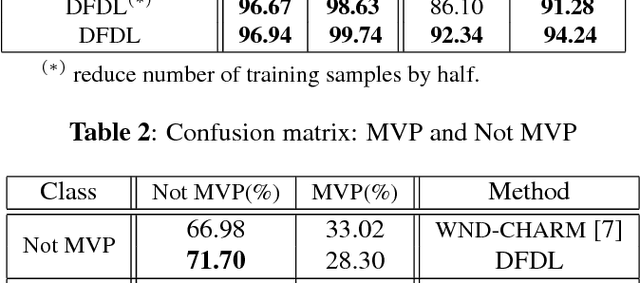
In histopathological image analysis, feature extraction for classification is a challenging task due to the diversity of histology features suitable for each problem as well as presence of rich geometrical structure. In this paper, we propose an automatic feature discovery framework for extracting discriminative class-specific features and present a low-complexity method for classification and disease grading in histopathology. Essentially, our Discriminative Feature-oriented Dictionary Learning (DFDL) method learns class-specific features which are suitable for representing samples from the same class while are poorly capable of representing samples from other classes. Experiments on three challenging real-world image databases: 1) histopathological images of intraductal breast lesions, 2) mammalian lung images provided by the Animal Diagnostics Lab (ADL) at Pennsylvania State University, and 3) brain tumor images from The Cancer Genome Atlas (TCGA) database, show the significance of DFDL model in a variety problems over state-of-the-art methods