 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive matching pursuit for sparse signal recovery
Sep 12, 2016


Spike and Slab priors have been of much recent interest in signal processing as a means of inducing sparsity in Bayesian inference. Applications domains that benefit from the use of these priors include sparse recovery, regression and classification. It is well-known that solving for the sparse coefficient vector to maximize these priors results in a hard non-convex and mixed integer programming problem. Most existing solutions to this optimization problem either involve simplifying assumptions/relaxations or are computationally expensive. We propose a new greedy and adaptive matching pursuit (AMP) algorithm to directly solve this hard problem. Essentially, in each step of the algorithm, the set of active elements would be updated by either adding or removing one index, whichever results in better improvement. In addition, the intermediate steps of the algorithm are calculated via an inexpensive Cholesky decomposition which makes the algorithm much faster. Results on simulated data sets as well as real-world image recovery challenges confirm the benefits of the proposed AMP, particularly in providing a superior cost-quality trade-off over existing alternatives.
Learning a low-rank shared dictionary for object classification
May 18, 2016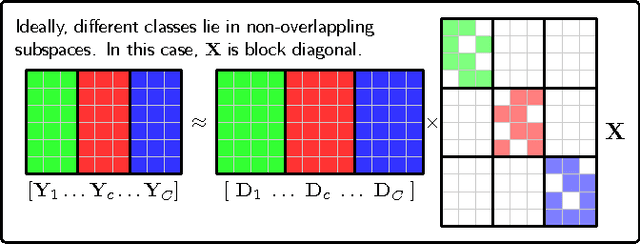



Despite the fact that different objects possess distinct class-specific features, they also usually share common patterns. Inspired by this observation, we propose a novel method to explicitly and simultaneously learn a set of common patterns as well as class-specific features for classification. Our dictionary learning framework is hence characterized by both a shared dictionary and particular (class-specific) dictionaries. For the shared dictionary, we enforce a low-rank constraint, i.e. claim that its spanning subspace should have low dimension and the coefficients corresponding to this dictionary should be similar. For the particular dictionaries, we impose on them the well-known constraints stated in the Fisher discrimination dictionary learning (FDDL). Further, we propose a new fast and accurate algorithm to solve the sparse coding problems in the learning step, accelerating its convergence. The said algorithm could also be applied to FDDL and its extensions. Experimental results on widely used image databases establish the advantages of our method over state-of-the-art dictionary learning methods.
DFDL: Discriminative Feature-oriented Dictionary Learning for Histopathological Image Classification
Feb 03, 2015
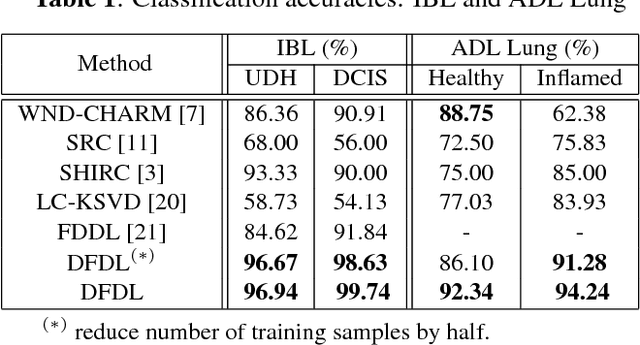
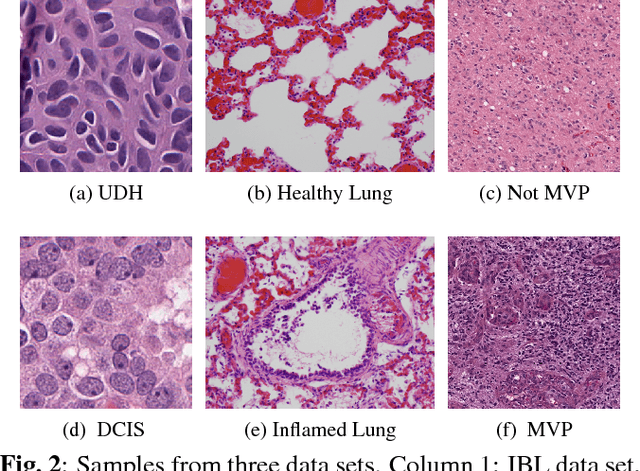
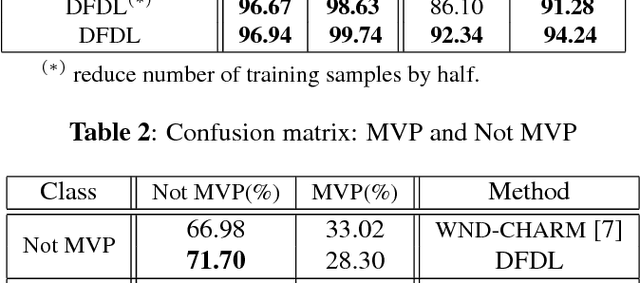
In histopathological image analysis, feature extraction for classification is a challenging task due to the diversity of histology features suitable for each problem as well as presence of rich geometrical structure. In this paper, we propose an automatic feature discovery framework for extracting discriminative class-specific features and present a low-complexity method for classification and disease grading in histopathology. Essentially, our Discriminative Feature-oriented Dictionary Learning (DFDL) method learns class-specific features which are suitable for representing samples from the same class while are poorly capable of representing samples from other classes. Experiments on three challenging real-world image databases: 1) histopathological images of intraductal breast lesions, 2) mammalian lung images provided by the Animal Diagnostics Lab (ADL) at Pennsylvania State University, and 3) brain tumor images from The Cancer Genome Atlas (TCGA) database, show the significance of DFDL model in a variety problems over state-of-the-art methods