 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative, Deep Synthetic Aperture Sonar Image Segmentation
Mar 28, 2022
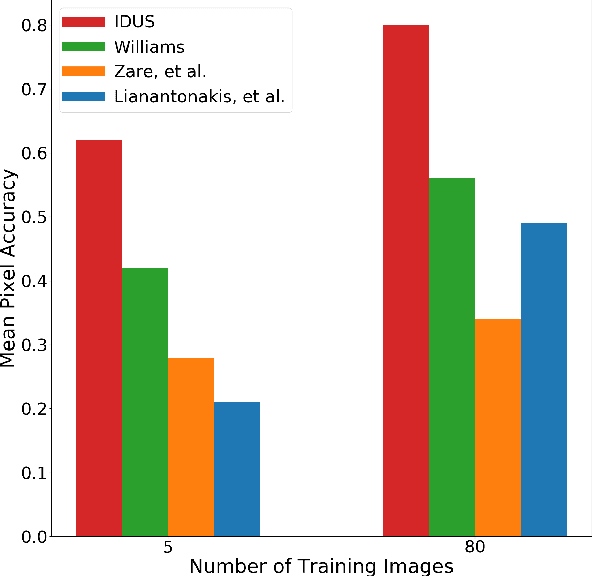
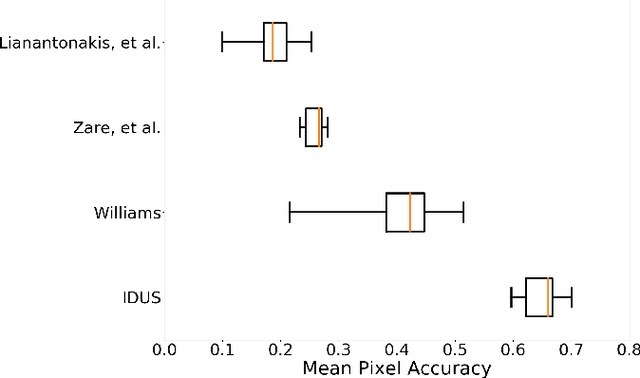
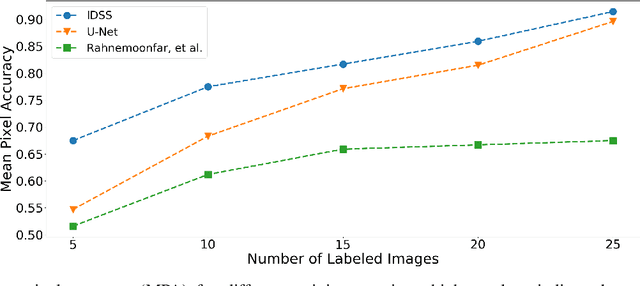
Synthetic aperture sonar (SAS) systems produce high-resolution images of the seabed environment. Moreover, deep learning has demonstrated superior ability in finding robust features for automating imagery analysis. However, the success of deep learning is conditioned on having lots of labeled training data, but obtaining generous pixel-level annotations of SAS imagery is often practically infeasible. This challenge has thus far limited the adoption of deep learning methods for SAS segmentation. Algorithms exist to segment SAS imagery in an unsupervised manner, but they lack the benefit of state-of-the-art learning methods and the results present significant room for improvement. In view of the above, we propose a new iterative algorithm for unsupervised SAS image segmentation combining superpixel formation, deep learning, and traditional clustering methods. We call our method Iterative Deep Unsupervised Segmentation (IDUS). IDUS is an unsupervised learning framework that can be divided into four main steps: 1) A deep network estimates class assignments. 2) Low-level image features from the deep network are clustered into superpixels. 3) Superpixels are clustered into class assignments (which we call pseudo-labels) using $k$-means. 4) Resulting pseudo-labels are used for loss backpropagation of the deep network prediction. These four steps are performed iteratively until convergence. A comparison of IDUS to current state-of-the-art methods on a realistic benchmark dataset for SAS image segmentation demonstrates the benefits of our proposal even as the IDUS incurs a much lower computational burden during inference (actual labeling of a test image). Finally, we also develop a semi-supervised (SS) extension of IDUS called IDSS and demonstrate experimentally that it can further enhance performance while outperforming supervised alternatives that exploit the same labeled training imagery.
Iterative, Deep, and Unsupervised Synthetic Aperture Sonar Image Segmentation
Jul 30, 2021
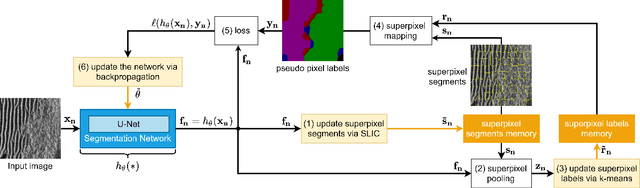

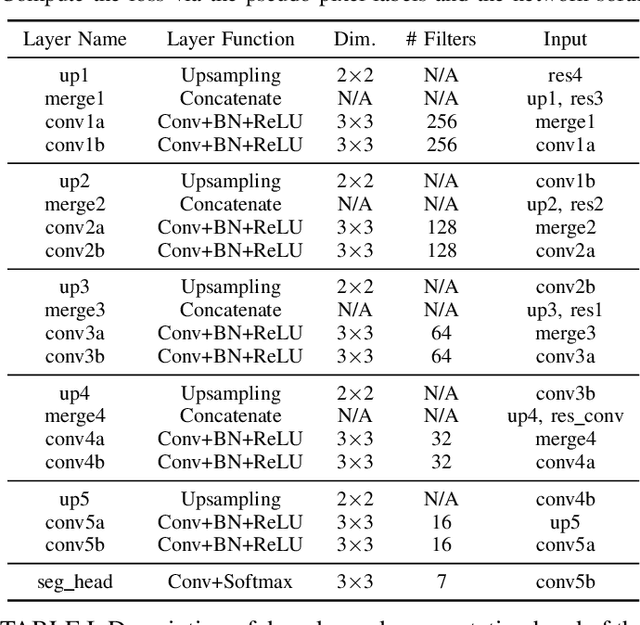
Deep learning has not been routinely employed for semantic segmentation of seabed environment for synthetic aperture sonar (SAS) imagery due to the implicit need of abundant training data such methods necessitate. Abundant training data, specifically pixel-level labels for all images, is usually not available for SAS imagery due to the complex logistics (e.g., diver survey, chase boat, precision position information) needed for obtaining accurate ground-truth. Many hand-crafted feature based algorithms have been proposed to segment SAS in an unsupervised fashion. However, there is still room for improvement as the feature extraction step of these methods is fixed. In this work, we present a new iterative unsupervised algorithm for learning deep features for SAS image segmentation. Our proposed algorithm alternates between clustering superpixels and updating the parameters of a convolutional neural network (CNN) so that the feature extraction for image segmentation can be optimized. We demonstrate the efficacy of our method on a realistic benchmark dataset. Our results show that the performance of our proposed method is considerably better than current state-of-the-art methods in SAS image segmentation.
Real-Time, Deep Synthetic Aperture Sonar (SAS) Autofocus
Mar 18, 2021
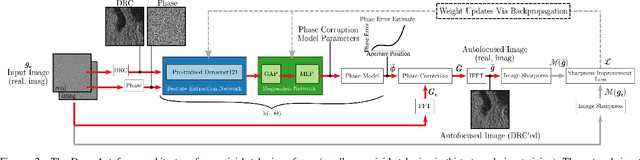
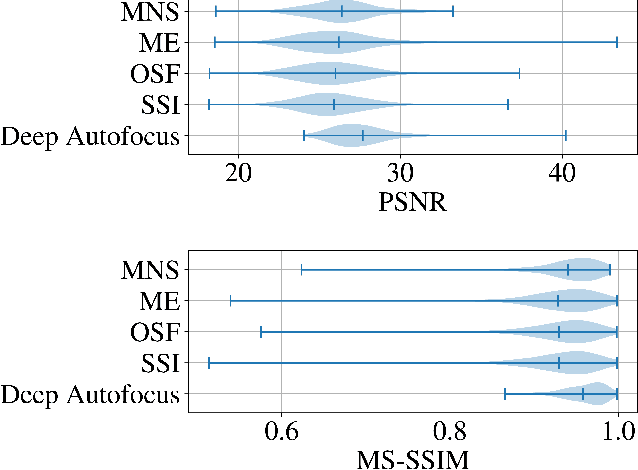

Synthetic aperture sonar (SAS) requires precise time-of-flight measurements of the transmitted/received waveform to produce well-focused imagery. It is not uncommon for errors in these measurements to be present resulting in image defocusing. To overcome this, an \emph{autofocus} algorithm is employed as a post-processing step after image reconstruction to improve image focus. A particular class of these algorithms can be framed as a sharpness/contrast metric-based optimization. To improve convergence, a hand-crafted weighting function to remove "bad" areas of the image is sometimes applied to the image-under-test before the optimization procedure. Additionally, dozens of iterations are necessary for convergence which is a large compute burden for low size, weight, and power (SWaP) systems. We propose a deep learning technique to overcome these limitations and implicitly learn the weighting function in a data-driven manner. Our proposed method, which we call Deep Autofocus, uses features from the single-look-complex (SLC) to estimate the phase correction which is applied in $k$-space. Furthermore, we train our algorithm on batches of training imagery so that during deployment, only a single iteration of our method is sufficient to autofocus. We show results demonstrating the robustness of our technique by comparing our results to four commonly used image sharpness metrics. Our results demonstrate Deep Autofocus can produce imagery perceptually better than common iterative techniques but at a lower computational cost. We conclude that Deep Autofocus can provide a more favorable cost-quality trade-off than alternatives with significant potential of future research.
GPU Acceleration for Synthetic Aperture Sonar Image Reconstruction
Jan 14, 2021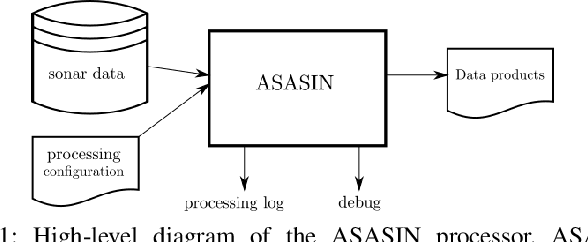
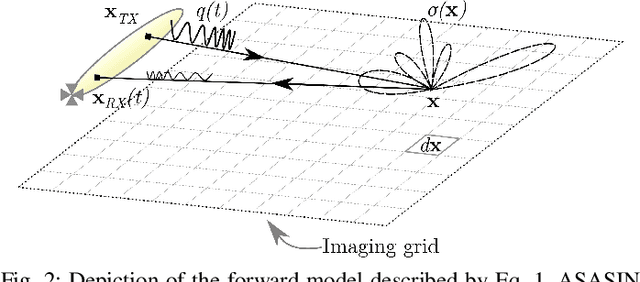
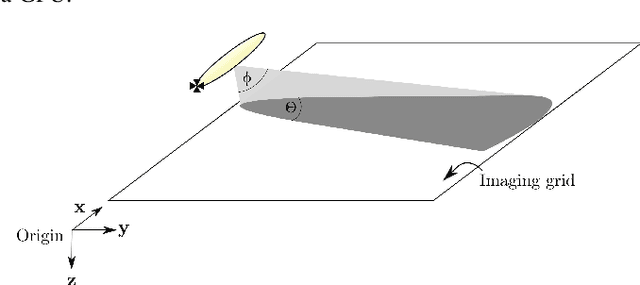
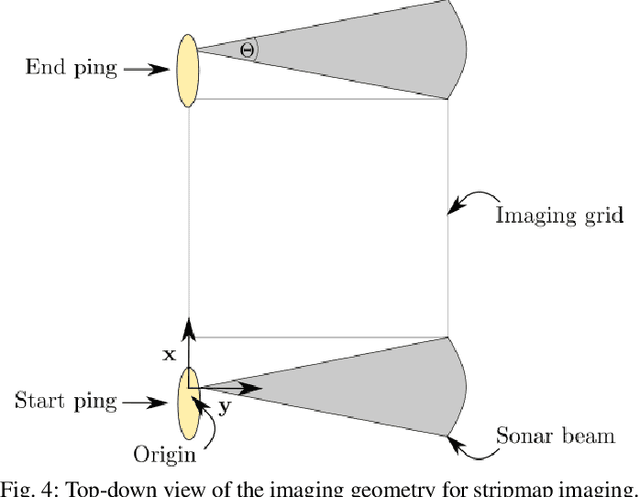
Synthetic aperture sonar (SAS) image reconstruction, or beamforming as it is often referred to within the SAS community, comprises a class of computationally intensive algorithms for creating coherent high-resolution imagery from successive spatially varying sonar pings. Image reconstruction is usually performed topside because of the large compute burden necessitated by the procedure. Historically, image reconstruction required significant assumptions in order to produce real-time imagery within an unmanned underwater vehicle's (UUV's) size, weight, and power (SWaP) constraints. However, these assumptions result in reduced image quality. In this work, we describe ASASIN, the Advanced Synthetic Aperture Sonar Imagining eNgine. ASASIN is a time domain backprojection image reconstruction suite utilizing graphics processing units (GPUs) allowing real-time operation on UUVs without sacrificing image quality. We describe several speedups employed in ASASIN allowing us to achieve this objective. Furthermore, ASASIN's signal processing chain is capable of producing 2D and 3D SAS imagery as we will demonstrate. Finally, we measure ASASIN's performance on a variety of GPUs and create a model capable of predicting performance. We demonstrate our model's usefulness in predicting run-time performance on desktop and embedded GPU hardware.
Structural Prior Driven Regularized Deep Learning for Sonar Image Classification
Oct 26, 2020
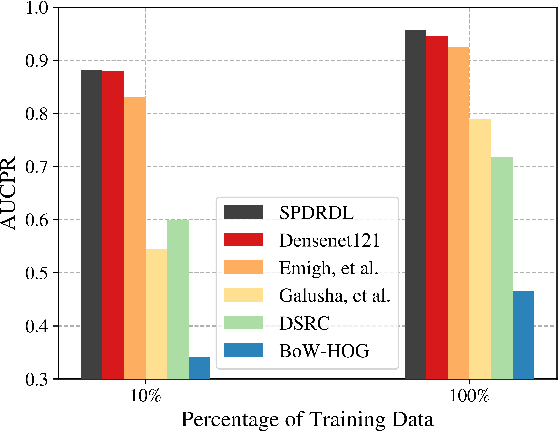
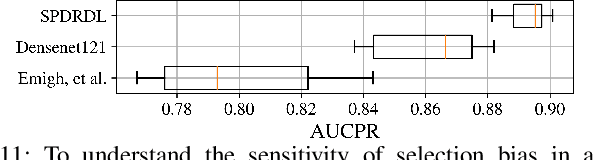

Deep learning has been recently shown to improve performance in the domain of synthetic aperture sonar (SAS) image classification. Given the constant resolution with range of a SAS, it is no surprise that deep learning techniques perform so well. Despite deep learning's recent success, there are still compelling open challenges in reducing the high false alarm rate and enabling success when training imagery is limited, which is a practical challenge that distinguishes the SAS classification problem from standard image classification set-ups where training imagery may be abundant. We address these challenges by exploiting prior knowledge that humans use to grasp the scene. These include unconscious elimination of the image speckle and localization of objects in the scene. We introduce a new deep learning architecture which incorporates these priors with the goal of improving automatic target recognition (ATR) from SAS imagery. Our proposal -- called SPDRDL, Structural Prior Driven Regularized Deep Learning -- incorporates the previously mentioned priors in a multi-task convolutional neural network (CNN) and requires no additional training data when compared to traditional SAS ATR methods. Two structural priors are enforced via regularization terms in the learning of the network: (1) structural similarity prior -- enhanced imagery (often through despeckling) aids human interpretation and is semantically similar to the original imagery and (2) structural scene context priors -- learned features ideally encapsulate target centering information; hence learning may be enhanced via a regularization that encourages fidelity against known ground truth target shifts (relative target position from scene center). Experiments on a challenging real-world dataset reveal that SPDRDL outperforms state-of-the-art deep learning and other competing methods for SAS image classification.