 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Classify New Foods Incrementally Via Compressed Exemplars
Apr 11, 2024Food image classification systems play a crucial role in health monitoring and diet tracking through image-based dietary assessment techniques. However, existing food recognition systems rely on static datasets characterized by a pre-defined fixed number of food classes. This contrasts drastically with the reality of food consumption, which features constantly changing data. Therefore, food image classification systems should adapt to and manage data that continuously evolves. This is where continual learning plays an important role. A challenge in continual learning is catastrophic forgetting, where ML models tend to discard old knowledge upon learning new information. While memory-replay algorithms have shown promise in mitigating this problem by storing old data as exemplars, they are hampered by the limited capacity of memory buffers, leading to an imbalance between new and previously learned data. To address this, our work explores the use of neural image compression to extend buffer size and enhance data diversity. We introduced the concept of continuously learning a neural compression model to adaptively improve the quality of compressed data and optimize the bitrates per pixel (bpp) to store more exemplars. Our extensive experiments, including evaluations on food-specific datasets including Food-101 and VFN-74, as well as the general dataset ImageNet-100, demonstrate improvements in classification accuracy. This progress is pivotal in advancing more realistic food recognition systems that are capable of adapting to continually evolving data. Moreover, the principles and methodologies we've developed hold promise for broader applications, extending their benefits to other domains of continual machine learning systems.
Probing Image Compression For Class-Incremental Learning
Mar 10, 2024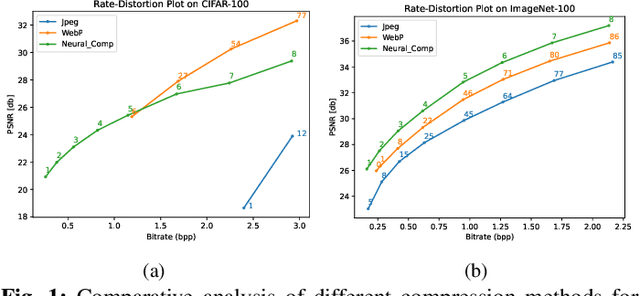
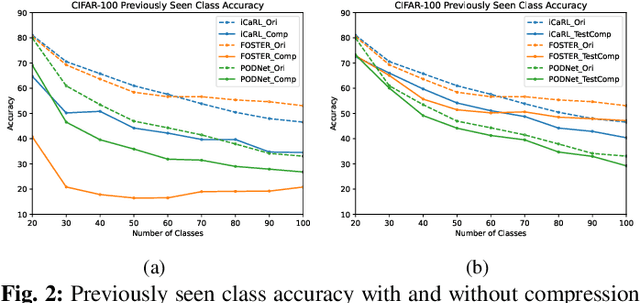
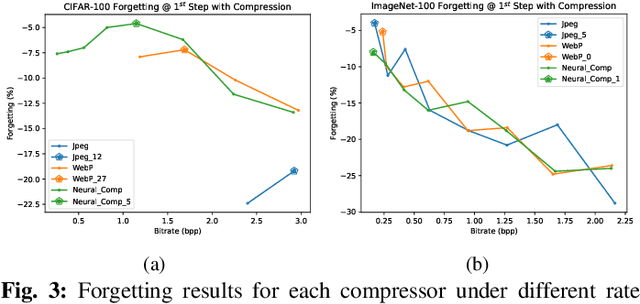
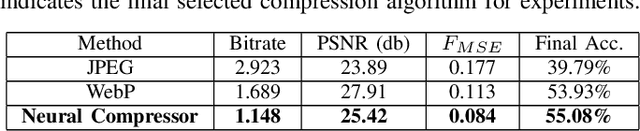
Image compression emerges as a pivotal tool in the efficient handling and transmission of digital images. Its ability to substantially reduce file size not only facilitates enhanced data storage capacity but also potentially brings advantages to the development of continual machine learning (ML) systems, which learn new knowledge incrementally from sequential data. Continual ML systems often rely on storing representative samples, also known as exemplars, within a limited memory constraint to maintain the performance on previously learned data. These methods are known as memory replay-based algorithms and have proven effective at mitigating the detrimental effects of catastrophic forgetting. Nonetheless, the limited memory buffer size often falls short of adequately representing the entire data distribution. In this paper, we explore the use of image compression as a strategy to enhance the buffer's capacity, thereby increasing exemplar diversity. However, directly using compressed exemplars introduces domain shift during continual ML, marked by a discrepancy between compressed training data and uncompressed testing data. Additionally, it is essential to determine the appropriate compression algorithm and select the most effective rate for continual ML systems to balance the trade-off between exemplar quality and quantity. To this end, we introduce a new framework to incorporate image compression for continual ML including a pre-processing data compression step and an efficient compression rate/algorithm selection method. We conduct extensive experiments on CIFAR-100 and ImageNet datasets and show that our method significantly improves image classification accuracy in continual ML settings.
Towards Backward-Compatible Continual Learning of Image Compression
Feb 29, 2024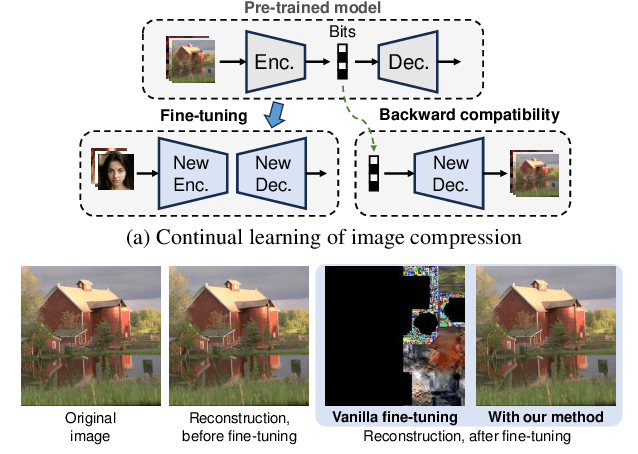
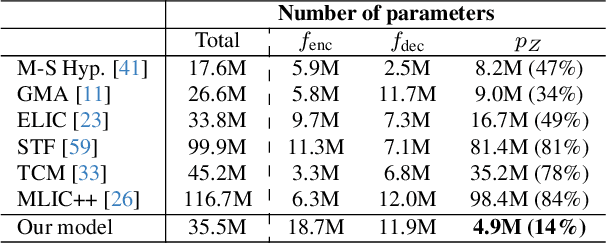
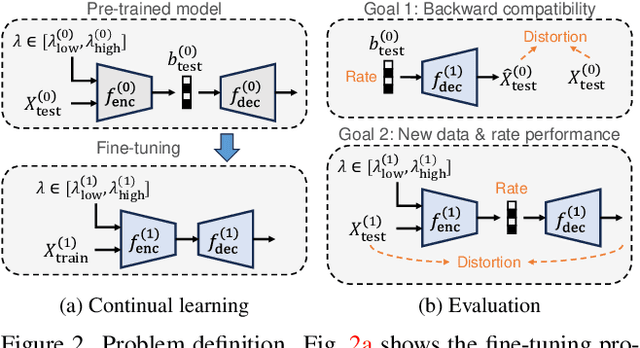
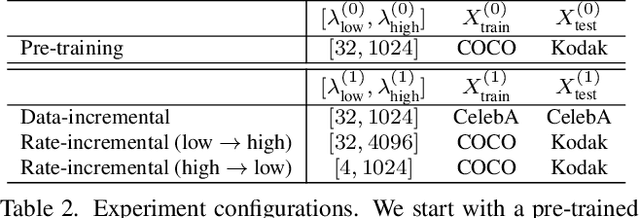
This paper explores the possibility of extending the capability of pre-trained neural image compressors (e.g., adapting to new data or target bitrates) without breaking backward compatibility, the ability to decode bitstreams encoded by the original model. We refer to this problem as continual learning of image compression. Our initial findings show that baseline solutions, such as end-to-end fine-tuning, do not preserve the desired backward compatibility. To tackle this, we propose a knowledge replay training strategy that effectively addresses this issue. We also design a new model architecture that enables more effective continual learning than existing baselines. Experiments are conducted for two scenarios: data-incremental learning and rate-incremental learning. The main conclusion of this paper is that neural image compressors can be fine-tuned to achieve better performance (compared to their pre-trained version) on new data and rates without compromising backward compatibility. Our code is available at https://gitlab.com/viper-purdue/continual-compression
A Visual Quality Assessment Method for Raster Images in Scanned Document
Jul 25, 2023



Image quality assessment (IQA) is an active research area in the field of image processing. Most prior works focus on visual quality of natural images captured by cameras. In this paper, we explore visual quality of scanned documents, focusing on raster image areas. Different from many existing works which aim to estimate a visual quality score, we propose a machine learning based classification method to determine whether the visual quality of a scanned raster image at a given resolution setting is acceptable. We conduct a psychophysical study to determine the acceptability at different image resolutions based on human subject ratings and use them as the ground truth to train our machine learning model. However, this dataset is unbalanced as most images were rated as visually acceptable. To address the data imbalance problem, we introduce several noise models to simulate the degradation of image quality during the scanning process. Our results show that by including augmented data in training, we can significantly improve the performance of the classifier to determine whether the visual quality of raster images in a scanned document is acceptable or not for a given resolution setting.
Visual communication of object concepts at different levels of abstraction
Jun 05, 2021


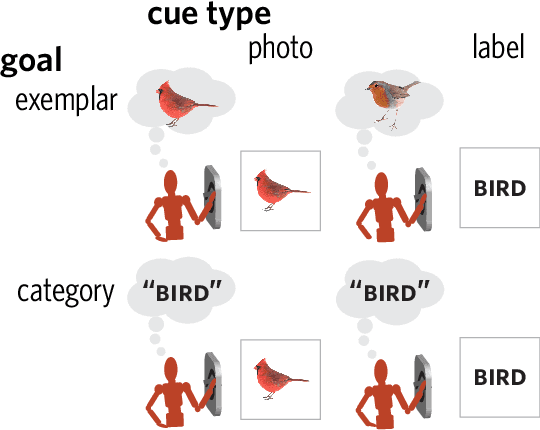
People can produce drawings of specific entities (e.g., Garfield), as well as general categories (e.g., "cat"). What explains this ability to produce such varied drawings of even highly familiar object concepts? We hypothesized that drawing objects at different levels of abstraction depends on both sensory information and representational goals, such that drawings intended to portray a recently seen object preserve more detail than those intended to represent a category. Participants drew objects cued either with a photo or a category label. For each cue type, half the participants aimed to draw a specific exemplar; the other half aimed to draw the category. We found that label-cued category drawings were the most recognizable at the basic level, whereas photo-cued exemplar drawings were the least recognizable. Together, these findings highlight the importance of task context for explaining how people use drawings to communicate visual concepts in different ways.
Deepfakes Detection with Automatic Face Weighting
May 04, 2020

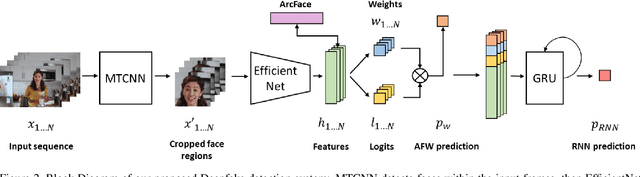

Altered and manipulated multimedia is increasingly present and widely distributed via social media platforms. Advanced video manipulation tools enable the generation of highly realistic-looking altered multimedia. While many methods have been presented to detect manipulations, most of them fail when evaluated with data outside of the datasets used in research environments. In order to address this problem, the Deepfake Detection Challenge (DFDC) provides a large dataset of videos containing realistic manipulations and an evaluation system that ensures that methods work quickly and accurately, even when faced with challenging data. In this paper, we introduce a method based on convolutional neural networks (CNNs) and recurrent neural networks (RNNs) that extracts visual and temporal features from faces present in videos to accurately detect manipulations. The method is evaluated with the DFDC dataset, providing competitive results compared to other techniques.