 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexSim2Real$^{2}$: Building Explicit World Model for Precise Articulated Object Dexterous Manipulation
Sep 13, 2024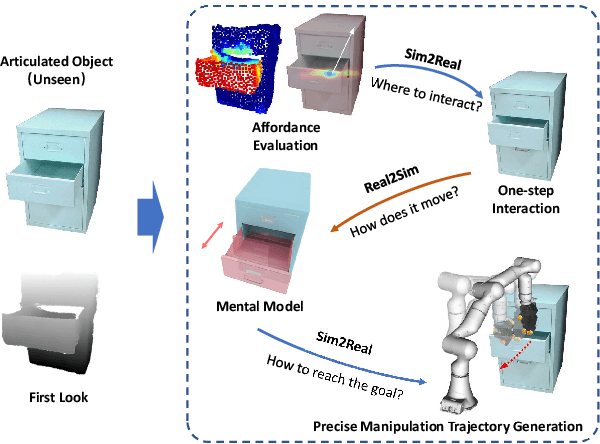

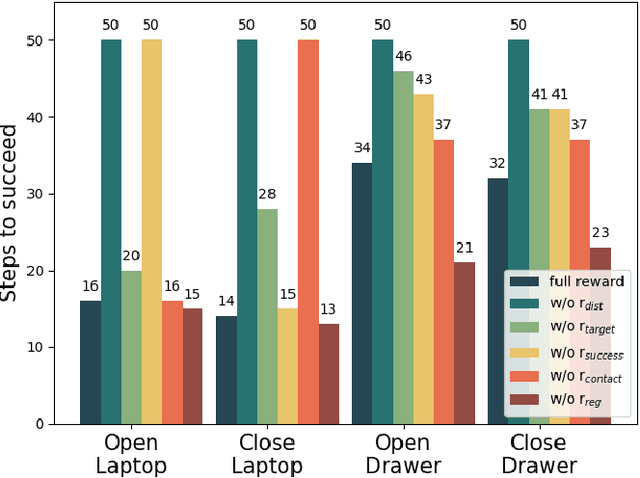
Articulated object manipulation is ubiquitous in daily life. In this paper, we present DexSim2Real$^{2}$, a novel robot learning framework for goal-conditioned articulated object manipulation using both two-finger grippers and multi-finger dexterous hands. The key of our framework is constructing an explicit world model of unseen articulated objects through active one-step interactions. This explicit world model enables sampling-based model predictive control to plan trajectories achieving different manipulation goals without needing human demonstrations or reinforcement learning. It first predicts an interaction motion using an affordance estimation network trained on self-supervised interaction data or videos of human manipulation from the internet. After executing this interaction on the real robot, the framework constructs a digital twin of the articulated object in simulation based on the two point clouds before and after the interaction. For dexterous multi-finger manipulation, we propose to utilize eigengrasp to reduce the high-dimensional action space, enabling more efficient trajectory searching. Extensive experiments validate the framework's effectiveness for precise articulated object manipulation in both simulation and the real world using a two-finger gripper and a 16-DoF dexterous hand. The robust generalizability of the explicit world model also enables advanced manipulation strategies, such as manipulating with different tools.
Sim2Real$^2$: Actively Building Explicit Physics Model for Precise Articulated Object Manipulation
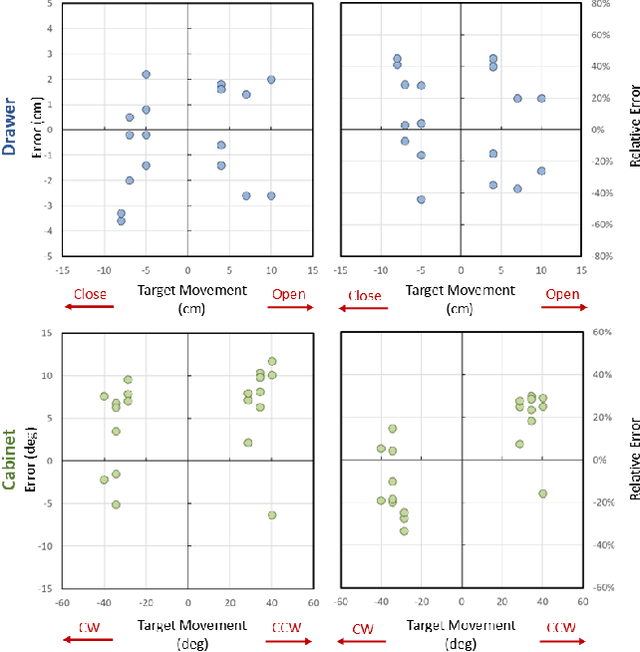
Feb 21, 2023Accurately manipulating articulated objects is a challenging yet important task for real robot applications. In this paper, we present a novel framework called Sim2Real$^2$ to enable the robot to manipulate an unseen articulated object to the desired state precisely in the real world with no human demonstrations. We leverage recent advances in physics simulation and learning-based perception to build the interactive explicit physics model of the object and use it to plan a long-horizon manipulation trajectory to accomplish the task. However, the interactive model cannot be correctly estimated from a static observation. Therefore, we learn to predict the object affordance from a single-frame point cloud, control the robot to actively interact with the object with a one-step action, and capture another point cloud. Further, the physics model is constructed from the two point clouds. Experimental results show that our framework achieves about 70% manipulations with <30% relative error for common articulated objects, and 30% manipulations for difficult objects. Our proposed framework also enables advanced manipulation strategies, such as manipulating with different tools. Code and videos are available on our project webpage: https://ttimelord.github.io/Sim2Real2-site/