 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogics-STEM: Empowering LLM Reasoning via Failure-Driven Post-Training and Document Knowledge Enhancement
Jan 08, 2026We present Logics-STEM, a state-of-the-art reasoning model fine-tuned on Logics-STEM-SFT-Dataset, a high-quality and diverse dataset at 10M scale that represents one of the largest-scale open-source long chain-of-thought corpora. Logics-STEM targets reasoning tasks in the domains of Science, Technology, Engineering, and Mathematics (STEM), and exhibits exceptional performance on STEM-related benchmarks with an average improvement of 4.68% over the next-best model at 8B scale. We attribute the gains to our data-algorithm co-design engine, where they are jointly optimized to fit a gold-standard distribution behind reasoning. Data-wise, the Logics-STEM-SFT-Dataset is constructed from a meticulously designed data curation engine with 5 stages to ensure the quality, diversity, and scalability, including annotation, deduplication, decontamination, distillation, and stratified sampling. Algorithm-wise, our failure-driven post-training framework leverages targeted knowledge retrieval and data synthesis around model failure regions in the Supervised Fine-tuning (SFT) stage to effectively guide the second-stage SFT or the reinforcement learning (RL) for better fitting the target distribution. The superior empirical performance of Logics-STEM reveals the vast potential of combining large-scale open-source data with carefully designed synthetic data, underscoring the critical role of data-algorithm co-design in enhancing reasoning capabilities through post-training. We make both the Logics-STEM models (8B and 32B) and the Logics-STEM-SFT-Dataset (10M and downsampled 2.2M versions) publicly available to support future research in the open-source community.
DDK: Distilling Domain Knowledge for Efficient Large Language Models
Jul 23, 2024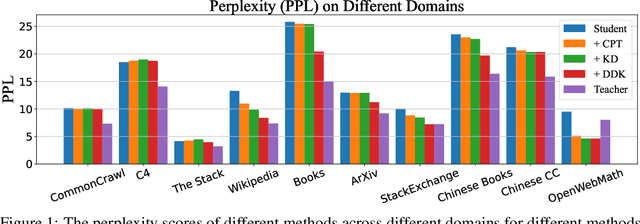
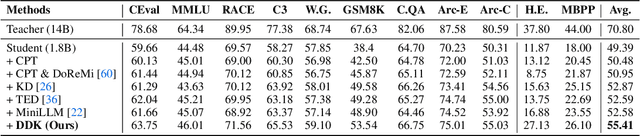
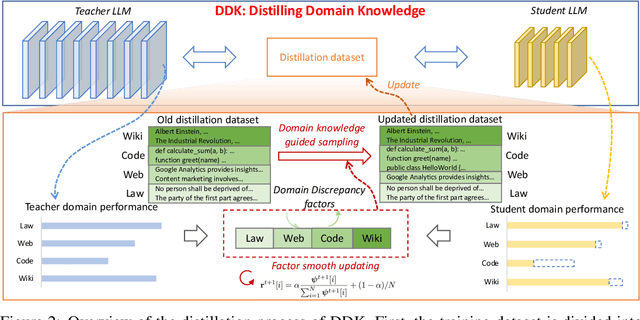
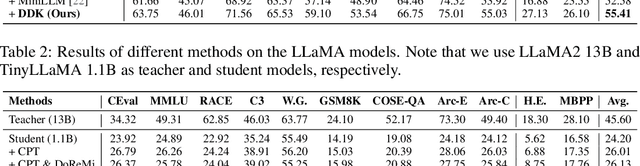
Despite the advanced intelligence abilities of large language models (LLMs) in various applications, they still face significant computational and storage demands. Knowledge Distillation (KD) has emerged as an effective strategy to improve the performance of a smaller LLM (i.e., the student model) by transferring knowledge from a high-performing LLM (i.e., the teacher model). Prevailing techniques in LLM distillation typically use a black-box model API to generate high-quality pretrained and aligned datasets, or utilize white-box distillation by altering the loss function to better transfer knowledge from the teacher LLM. However, these methods ignore the knowledge differences between the student and teacher LLMs across domains. This results in excessive focus on domains with minimal performance gaps and insufficient attention to domains with large gaps, reducing overall performance. In this paper, we introduce a new LLM distillation framework called DDK, which dynamically adjusts the composition of the distillation dataset in a smooth manner according to the domain performance differences between the teacher and student models, making the distillation process more stable and effective. Extensive evaluations show that DDK significantly improves the performance of student models, outperforming both continuously pretrained baselines and existing knowledge distillation methods by a large margin.
D-CPT Law: Domain-specific Continual Pre-Training Scaling Law for Large Language Models
Jun 03, 2024



Continual Pre-Training (CPT) on Large Language Models (LLMs) has been widely used to expand the model's fundamental understanding of specific downstream domains (e.g., math and code). For the CPT on domain-specific LLMs, one important question is how to choose the optimal mixture ratio between the general-corpus (e.g., Dolma, Slim-pajama) and the downstream domain-corpus. Existing methods usually adopt laborious human efforts by grid-searching on a set of mixture ratios, which require high GPU training consumption costs. Besides, we cannot guarantee the selected ratio is optimal for the specific domain. To address the limitations of existing methods, inspired by the Scaling Law for performance prediction, we propose to investigate the Scaling Law of the Domain-specific Continual Pre-Training (D-CPT Law) to decide the optimal mixture ratio with acceptable training costs for LLMs of different sizes. Specifically, by fitting the D-CPT Law, we can easily predict the general and downstream performance of arbitrary mixture ratios, model sizes, and dataset sizes using small-scale training costs on limited experiments. Moreover, we also extend our standard D-CPT Law on cross-domain settings and propose the Cross-Domain D-CPT Law to predict the D-CPT law of target domains, where very small training costs (about 1% of the normal training costs) are needed for the target domains. Comprehensive experimental results on six downstream domains demonstrate the effectiveness and generalizability of our proposed D-CPT Law and Cross-Domain D-CPT Law.
ConceptMath: A Bilingual Concept-wise Benchmark for Measuring Mathematical Reasoning of Large Language Models
Feb 23, 2024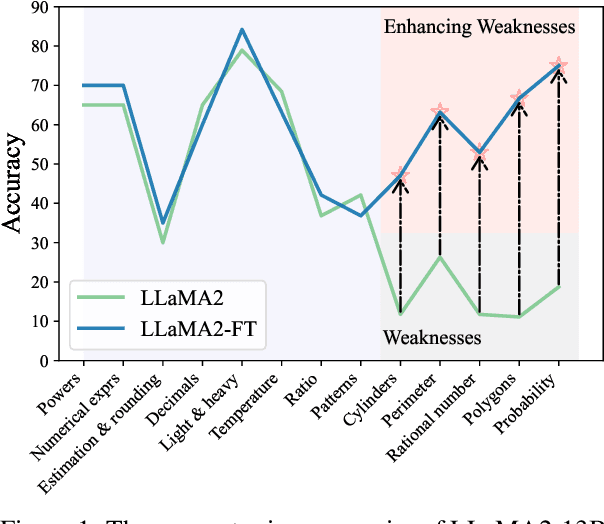
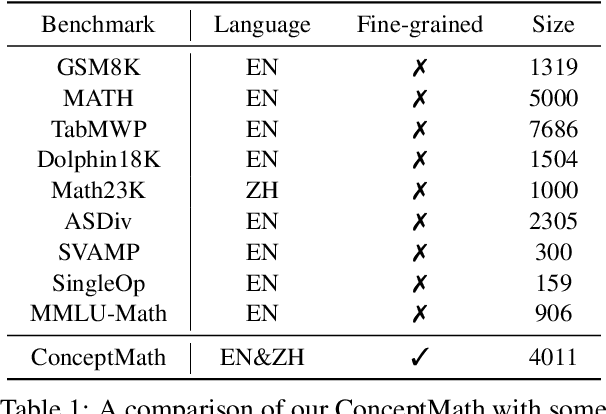
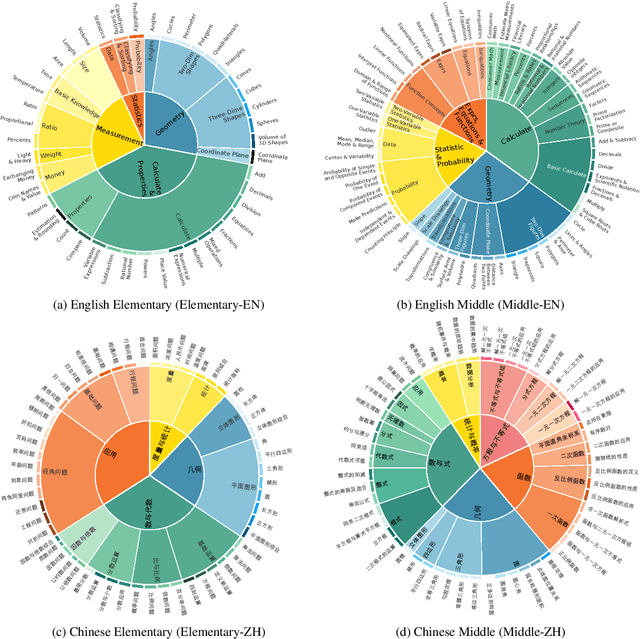
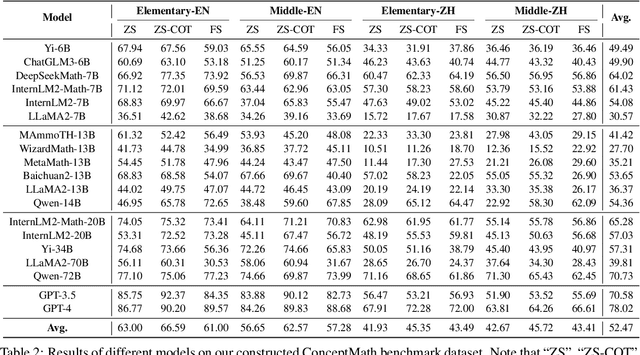
This paper introduces ConceptMath, a bilingual (English and Chinese), fine-grained benchmark that evaluates concept-wise mathematical reasoning of Large Language Models (LLMs). Unlike traditional benchmarks that evaluate general mathematical reasoning with an average accuracy, ConceptMath systematically organizes math problems under a hierarchy of math concepts, so that mathematical reasoning can be evaluated at different granularity with concept-wise accuracies. Based on our ConcepthMath, we evaluate a broad range of LLMs, and we observe existing LLMs, though achieving high average accuracies on traditional benchmarks, exhibit significant performance variations across different math concepts and may even fail catastrophically on the most basic ones. Besides, we also introduce an efficient fine-tuning strategy to enhance the weaknesses of existing LLMs. Finally, we hope ConceptMath could guide the developers to understand the fine-grained mathematical abilities of their models and facilitate the growth of foundation models.
E^2-LLM: Efficient and Extreme Length Extension of Large Language Models
Jan 18, 2024



Typically, training LLMs with long context sizes is computationally expensive, requiring extensive training hours and GPU resources. Existing long-context extension methods usually need additional training procedures to support corresponding long-context windows, where the long-context training data (e.g., 32k) is needed, and high GPU training costs are assumed. To address the aforementioned issues, we propose an Efficient and Extreme length extension method for Large Language Models, called E 2 -LLM, with only one training procedure and dramatically reduced computation cost, which also removes the need to collect long-context data. Concretely, first, the training data of our E 2 -LLM only requires a short length (e.g., 4k), which reduces the tuning cost greatly. Second, the training procedure on the short training context window is performed only once time, and we can support different evaluation context windows at inference. Third, in E 2 - LLM, based on RoPE position embeddings, we introduce two different augmentation methods on the scale and position index parameters for different samples in training. It aims to make the model more robust to the different relative differences when directly interpolating the arbitrary context length at inference. Comprehensive experimental results on multiple benchmark datasets demonstrate the effectiveness of our E 2 -LLM on challenging long-context tasks.