 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogics-STEM: Empowering LLM Reasoning via Failure-Driven Post-Training and Document Knowledge Enhancement
Jan 08, 2026We present Logics-STEM, a state-of-the-art reasoning model fine-tuned on Logics-STEM-SFT-Dataset, a high-quality and diverse dataset at 10M scale that represents one of the largest-scale open-source long chain-of-thought corpora. Logics-STEM targets reasoning tasks in the domains of Science, Technology, Engineering, and Mathematics (STEM), and exhibits exceptional performance on STEM-related benchmarks with an average improvement of 4.68% over the next-best model at 8B scale. We attribute the gains to our data-algorithm co-design engine, where they are jointly optimized to fit a gold-standard distribution behind reasoning. Data-wise, the Logics-STEM-SFT-Dataset is constructed from a meticulously designed data curation engine with 5 stages to ensure the quality, diversity, and scalability, including annotation, deduplication, decontamination, distillation, and stratified sampling. Algorithm-wise, our failure-driven post-training framework leverages targeted knowledge retrieval and data synthesis around model failure regions in the Supervised Fine-tuning (SFT) stage to effectively guide the second-stage SFT or the reinforcement learning (RL) for better fitting the target distribution. The superior empirical performance of Logics-STEM reveals the vast potential of combining large-scale open-source data with carefully designed synthetic data, underscoring the critical role of data-algorithm co-design in enhancing reasoning capabilities through post-training. We make both the Logics-STEM models (8B and 32B) and the Logics-STEM-SFT-Dataset (10M and downsampled 2.2M versions) publicly available to support future research in the open-source community.
One Sample to Rule Them All: Extreme Data Efficiency in RL Scaling
Jan 06, 2026The reasoning ability of large language models (LLMs) can be unleashed with reinforcement learning (RL) (OpenAI, 2024; DeepSeek-AI et al., 2025a; Zeng et al., 2025). The success of existing RL attempts in LLMs usually relies on high-quality samples of thousands or beyond. In this paper, we challenge fundamental assumptions about data requirements in RL for LLMs by demonstrating the remarkable effectiveness of one-shot learning. Specifically, we introduce polymath learning, a framework for designing one training sample that elicits multidisciplinary impact. We present three key findings: (1) A single, strategically selected math reasoning sample can produce significant performance improvements across multiple domains, including physics, chemistry, and biology with RL; (2) The math skills salient to reasoning suggest the characteristics of the optimal polymath sample; and (3) An engineered synthetic sample that integrates multidiscipline elements outperforms training with individual samples that naturally occur. Our approach achieves superior performance to training with larger datasets across various reasoning benchmarks, demonstrating that sample quality and design, rather than quantity, may be the key to unlock enhanced reasoning capabilities in language models. Our results suggest a shift, dubbed as sample engineering, toward precision engineering of training samples rather than simply increasing data volume.
Reinforcement Learning Optimization for Large-Scale Learning: An Efficient and User-Friendly Scaling Library
Jun 06, 2025We introduce ROLL, an efficient, scalable, and user-friendly library designed for Reinforcement Learning Optimization for Large-scale Learning. ROLL caters to three primary user groups: tech pioneers aiming for cost-effective, fault-tolerant large-scale training, developers requiring flexible control over training workflows, and researchers seeking agile experimentation. ROLL is built upon several key modules to serve these user groups effectively. First, a single-controller architecture combined with an abstraction of the parallel worker simplifies the development of the training pipeline. Second, the parallel strategy and data transfer modules enable efficient and scalable training. Third, the rollout scheduler offers fine-grained management of each sample's lifecycle during the rollout stage. Fourth, the environment worker and reward worker support rapid and flexible experimentation with agentic RL algorithms and reward designs. Finally, AutoDeviceMapping allows users to assign resources to different models flexibly across various stages.
Deconstructing Long Chain-of-Thought: A Structured Reasoning Optimization Framework for Long CoT Distillation
Mar 20, 2025Recent advancements in large language models (LLMs) have demonstrated remarkable reasoning capabilities through long chain-of-thought (CoT) reasoning. The R1 distillation scheme has emerged as a promising approach for training cost-effective models with enhanced reasoning abilities. However, the underlying mechanisms driving its effectiveness remain unclear. This study examines the universality of distillation data and identifies key components that enable the efficient transfer of long-chain reasoning capabilities in LLM distillation. Our findings reveal that the effectiveness of long CoT reasoning distillation from teacher models like Qwen-QwQ degrades significantly on nonhomologous models, challenging the assumed universality of current distillation methods. To gain deeper insights into the structure and patterns of long CoT reasoning, we propose DLCoT (Deconstructing Long Chain-of-Thought), a distillation data enhancement framework. DLCoT consists of three key steps: (1) data segmentation to decompose complex long CoT structures, (2) simplification by eliminating unsolvable and redundant solutions, and (3) optimization of intermediate error states. Our approach significantly improves model performance and token efficiency, facilitating the development of high-performance LLMs.
Adaptive Dense Reward: Understanding the Gap Between Action and Reward Space in Alignment
Oct 23, 2024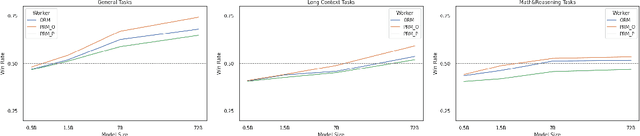
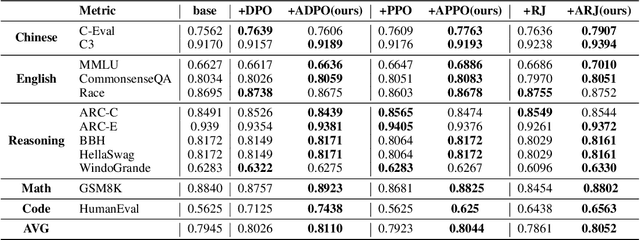
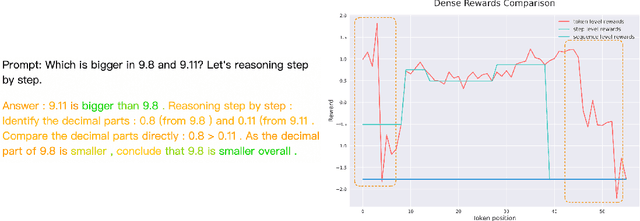
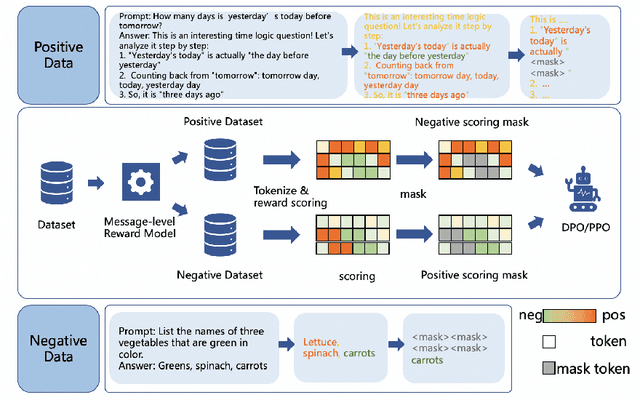
Reinforcement Learning from Human Feedback (RLHF) has proven highly effective in aligning Large Language Models (LLMs) with human preferences. However, the original RLHF typically optimizes under an overall reward, which can lead to a suboptimal learning process. This limitation stems from RLHF's lack of awareness regarding which specific tokens should be reinforced or suppressed. Moreover, conflicts in supervision can arise, for instance, when a chosen response includes erroneous tokens, while a rejected response contains accurate elements. To rectify these shortcomings, increasing dense reward methods, such as step-wise and token-wise RLHF, have been proposed. However, these existing methods are limited to specific tasks (like mathematics). In this paper, we propose the ``Adaptive Message-wise RLHF'' method, which robustly applies to various tasks. By defining pivot tokens as key indicators, our approach adaptively identifies essential information and converts sample-level supervision into fine-grained, subsequence-level supervision. This aligns the density of rewards and action spaces more closely with the information density of the input. Experiments demonstrate that our method can be integrated into various training methods, significantly mitigating hallucinations and catastrophic forgetting problems while outperforming other methods on multiple evaluation metrics. Our method improves the success rate on adversarial samples by 10\% compared to the sample-wise approach and achieves a 1.3\% improvement on evaluation benchmarks such as MMLU, GSM8K, and HumanEval et al.