 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Dense Reward: Understanding the Gap Between Action and Reward Space in Alignment
Paper and Code
Oct 23, 2024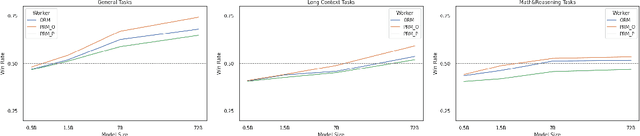
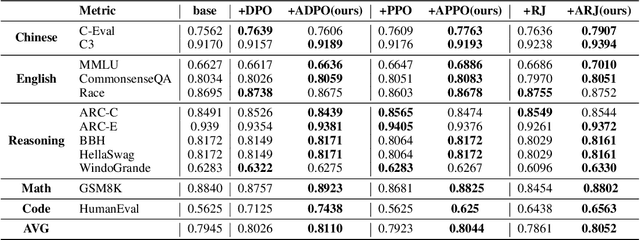
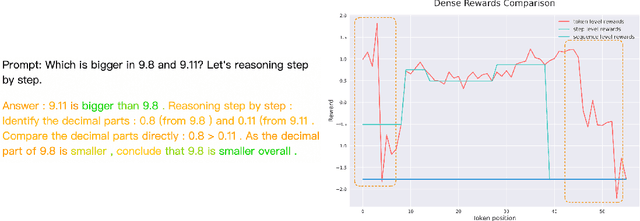
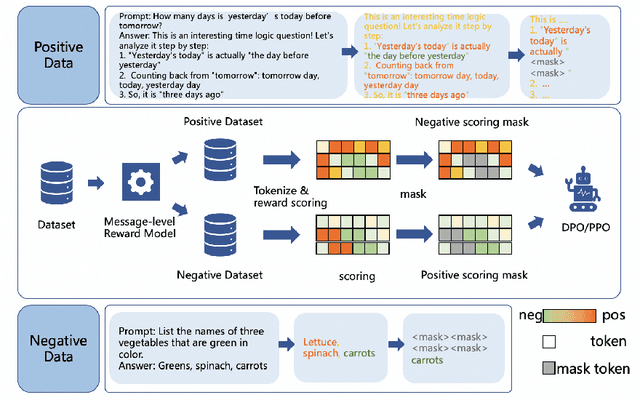
Reinforcement Learning from Human Feedback (RLHF) has proven highly effective in aligning Large Language Models (LLMs) with human preferences. However, the original RLHF typically optimizes under an overall reward, which can lead to a suboptimal learning process. This limitation stems from RLHF's lack of awareness regarding which specific tokens should be reinforced or suppressed. Moreover, conflicts in supervision can arise, for instance, when a chosen response includes erroneous tokens, while a rejected response contains accurate elements. To rectify these shortcomings, increasing dense reward methods, such as step-wise and token-wise RLHF, have been proposed. However, these existing methods are limited to specific tasks (like mathematics). In this paper, we propose the ``Adaptive Message-wise RLHF'' method, which robustly applies to various tasks. By defining pivot tokens as key indicators, our approach adaptively identifies essential information and converts sample-level supervision into fine-grained, subsequence-level supervision. This aligns the density of rewards and action spaces more closely with the information density of the input. Experiments demonstrate that our method can be integrated into various training methods, significantly mitigating hallucinations and catastrophic forgetting problems while outperforming other methods on multiple evaluation metrics. Our method improves the success rate on adversarial samples by 10\% compared to the sample-wise approach and achieves a 1.3\% improvement on evaluation benchmarks such as MMLU, GSM8K, and HumanEval et al.