 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogics-STEM: Empowering LLM Reasoning via Failure-Driven Post-Training and Document Knowledge Enhancement
Jan 08, 2026We present Logics-STEM, a state-of-the-art reasoning model fine-tuned on Logics-STEM-SFT-Dataset, a high-quality and diverse dataset at 10M scale that represents one of the largest-scale open-source long chain-of-thought corpora. Logics-STEM targets reasoning tasks in the domains of Science, Technology, Engineering, and Mathematics (STEM), and exhibits exceptional performance on STEM-related benchmarks with an average improvement of 4.68% over the next-best model at 8B scale. We attribute the gains to our data-algorithm co-design engine, where they are jointly optimized to fit a gold-standard distribution behind reasoning. Data-wise, the Logics-STEM-SFT-Dataset is constructed from a meticulously designed data curation engine with 5 stages to ensure the quality, diversity, and scalability, including annotation, deduplication, decontamination, distillation, and stratified sampling. Algorithm-wise, our failure-driven post-training framework leverages targeted knowledge retrieval and data synthesis around model failure regions in the Supervised Fine-tuning (SFT) stage to effectively guide the second-stage SFT or the reinforcement learning (RL) for better fitting the target distribution. The superior empirical performance of Logics-STEM reveals the vast potential of combining large-scale open-source data with carefully designed synthetic data, underscoring the critical role of data-algorithm co-design in enhancing reasoning capabilities through post-training. We make both the Logics-STEM models (8B and 32B) and the Logics-STEM-SFT-Dataset (10M and downsampled 2.2M versions) publicly available to support future research in the open-source community.
AVC-DPO: Aligned Video Captioning via Direct Preference Optimization
Jul 02, 2025Although video multimodal large language models (video MLLMs) have achieved substantial progress in video captioning tasks, it remains challenging to adjust the focal emphasis of video captions according to human preferences. To address this limitation, we propose Aligned Video Captioning via Direct Preference Optimization (AVC-DPO), a post-training framework designed to enhance captioning capabilities in video MLLMs through preference alignment. Our approach designs enhanced prompts that specifically target temporal dynamics and spatial information-two key factors that humans care about when watching a video-thereby incorporating human-centric preferences. AVC-DPO leverages the same foundation model's caption generation responses under varied prompt conditions to conduct preference-aware training and caption alignment. Using this framework, we have achieved exceptional performance in the LOVE@CVPR'25 Workshop Track 1A: Video Detailed Captioning Challenge, achieving first place on the Video Detailed Captioning (VDC) benchmark according to the VDCSCORE evaluation metric.
Improving ASR Contextual Biasing with Guided Attention
Jan 16, 2024



In this paper, we propose a Guided Attention (GA) auxiliary training loss, which improves the effectiveness and robustness of automatic speech recognition (ASR) contextual biasing without introducing additional parameters. A common challenge in previous literature is that the word error rate (WER) reduction brought by contextual biasing diminishes as the number of bias phrases increases. To address this challenge, we employ a GA loss as an additional training objective besides the Transducer loss. The proposed GA loss aims to teach the cross attention how to align bias phrases with text tokens or audio frames. Compared to studies with similar motivations, the proposed loss operates directly on the cross attention weights and is easier to implement. Through extensive experiments based on Conformer Transducer with Contextual Adapter, we demonstrate that the proposed method not only leads to a lower WER but also retains its effectiveness as the number of bias phrases increases. Specifically, the GA loss decreases the WER of rare vocabularies by up to 19.2% on LibriSpeech compared to the contextual biasing baseline, and up to 49.3% compared to a vanilla Transducer.
A New Benchmark of Aphasia Speech Recognition and Detection Based on E-Branchformer and Multi-task Learning
May 19, 2023



Aphasia is a language disorder that affects the speaking ability of millions of patients. This paper presents a new benchmark for Aphasia speech recognition and detection tasks using state-of-the-art speech recognition techniques with the AphsiaBank dataset. Specifically, we introduce two multi-task learning methods based on the CTC/Attention architecture to perform both tasks simultaneously. Our system achieves state-of-the-art speaker-level detection accuracy (97.3%), and a relative WER reduction of 11% for moderate Aphasia patients. In addition, we demonstrate the generalizability of our approach by applying it to another disordered speech database, the DementiaBank Pitt corpus. We will make our all-in-one recipes and pre-trained model publicly available to facilitate reproducibility. Our standardized data preprocessing pipeline and open-source recipes enable researchers to compare results directly, promoting progress in disordered speech processing.
A Comparative Study on E-Branchformer vs Conformer in Speech Recognition, Translation, and Understanding Tasks
May 18, 2023



Conformer, a convolution-augmented Transformer variant, has become the de facto encoder architecture for speech processing due to its superior performance in various tasks, including automatic speech recognition (ASR), speech translation (ST) and spoken language understanding (SLU). Recently, a new encoder called E-Branchformer has outperformed Conformer in the LibriSpeech ASR benchmark, making it promising for more general speech applications. This work compares E-Branchformer and Conformer through extensive experiments using different types of end-to-end sequence-to-sequence models. Results demonstrate that E-Branchformer achieves comparable or better performance than Conformer in almost all evaluation sets across 15 ASR, 2 ST, and 3 SLU benchmarks, while being more stable during training. We will release our training configurations and pre-trained models for reproducibility, which can benefit the speech community.
End-to-End Mandarin Tone Classification with Short Term Context Information
Apr 12, 2021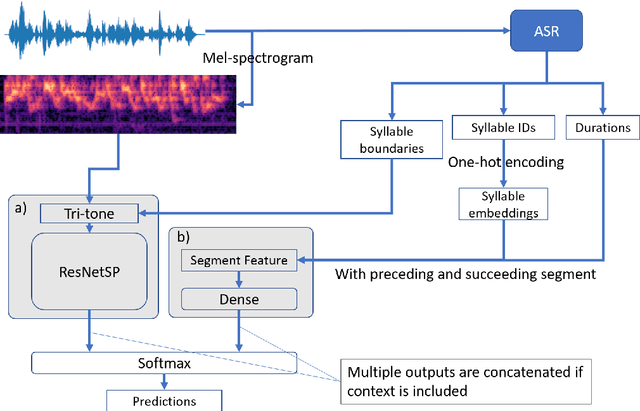
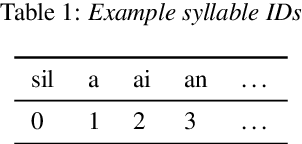

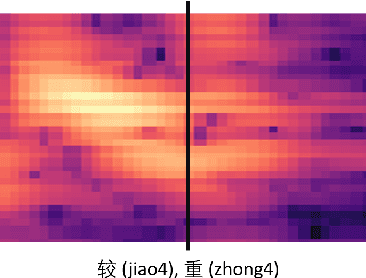
In this paper, we propose an end-to-end Mandarin tone classification method from continuous speech utterances utilizing both the spectrogram and the short term context information as the inputs. Both Mel-spectrograms and context segment features are used to train the tone classifier. We first divide the spectrogram frames into syllable segments using force alignment results produced by an ASR model. Then we extract the short term segment features to capture the context information across multiple syllables. Feeding both the Mel-spectrogram and the short term context segment features into an end-to-end model could significantly improve the performance. Experiments are performed on a large scale open source Mandarin speech dataset to evaluate the proposed method. Results show that the this method improves the classification accuracy from $79.5\%$ to $88.7\%$ on the AISHELL3 database.