 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogics-STEM: Empowering LLM Reasoning via Failure-Driven Post-Training and Document Knowledge Enhancement
Jan 08, 2026We present Logics-STEM, a state-of-the-art reasoning model fine-tuned on Logics-STEM-SFT-Dataset, a high-quality and diverse dataset at 10M scale that represents one of the largest-scale open-source long chain-of-thought corpora. Logics-STEM targets reasoning tasks in the domains of Science, Technology, Engineering, and Mathematics (STEM), and exhibits exceptional performance on STEM-related benchmarks with an average improvement of 4.68% over the next-best model at 8B scale. We attribute the gains to our data-algorithm co-design engine, where they are jointly optimized to fit a gold-standard distribution behind reasoning. Data-wise, the Logics-STEM-SFT-Dataset is constructed from a meticulously designed data curation engine with 5 stages to ensure the quality, diversity, and scalability, including annotation, deduplication, decontamination, distillation, and stratified sampling. Algorithm-wise, our failure-driven post-training framework leverages targeted knowledge retrieval and data synthesis around model failure regions in the Supervised Fine-tuning (SFT) stage to effectively guide the second-stage SFT or the reinforcement learning (RL) for better fitting the target distribution. The superior empirical performance of Logics-STEM reveals the vast potential of combining large-scale open-source data with carefully designed synthetic data, underscoring the critical role of data-algorithm co-design in enhancing reasoning capabilities through post-training. We make both the Logics-STEM models (8B and 32B) and the Logics-STEM-SFT-Dataset (10M and downsampled 2.2M versions) publicly available to support future research in the open-source community.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
LITE: LLM-Impelled efficient Taxonomy Evaluation
Apr 02, 2025This paper presents LITE, an LLM-based evaluation method designed for efficient and flexible assessment of taxonomy quality. To address challenges in large-scale taxonomy evaluation, such as efficiency, fairness, and consistency, LITE adopts a top-down hierarchical evaluation strategy, breaking down the taxonomy into manageable substructures and ensuring result reliability through cross-validation and standardized input formats. LITE also introduces a penalty mechanism to handle extreme cases and provides both quantitative performance analysis and qualitative insights by integrating evaluation metrics closely aligned with task objectives. Experimental results show that LITE demonstrates high reliability in complex evaluation tasks, effectively identifying semantic errors, logical contradictions, and structural flaws in taxonomies, while offering directions for improvement. Code is available at https://github.com/Zhang-l-i-n/TAXONOMY_DETECT .
ToReMi: Topic-Aware Data Reweighting for Dynamic Pre-Training Data Selection
Apr 01, 2025

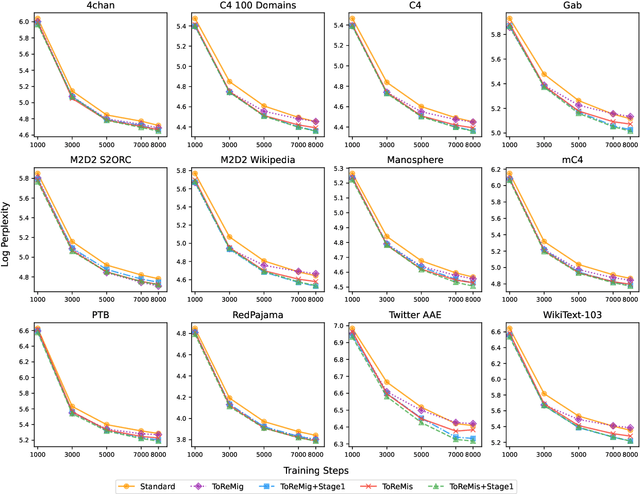

Pre-training large language models (LLMs) necessitates enormous diverse textual corpora, making effective data selection a key challenge for balancing computational resources and model performance. Current methodologies primarily emphasize data quality metrics and mixing proportions, yet they fail to adequately capture the underlying semantic connections between training samples and quality disparities within individual domains. We introduce ToReMi (Topic-based Reweighting for Model improvement), a novel two-stage framework that dynamically adjusts training sample weights according to their topical associations and observed learning patterns. Our comprehensive experiments reveal that ToReMi variants consistently achieve superior performance over conventional pre-training approaches, demonstrating accelerated perplexity reduction across multiple domains and enhanced capabilities on downstream evaluation tasks. Code is available at https://github.com/zxx000728/ToReMi.
GAPO: Learning Preferential Prompt through Generative Adversarial Policy Optimization
Mar 26, 2025Recent advances in large language models have highlighted the critical need for precise control over model outputs through predefined constraints. While existing methods attempt to achieve this through either direct instruction-response synthesis or preferential response optimization, they often struggle with constraint understanding and adaptation. This limitation becomes particularly evident when handling fine-grained constraints, leading to either hallucination or brittle performance. We introduce Generative Adversarial Policy Optimization (GAPO), a novel framework that combines GAN-based training dynamics with an encoder-only reward model to progressively learn and adapt to increasingly complex constraints. GAPO leverages adversarial training to automatically generate training samples of varying difficulty while utilizing the encoder-only architecture to better capture prompt-response relationships. Extensive experiments demonstrate GAPO's superior performance across multiple benchmarks, particularly in scenarios requiring fine-grained constraint handling, where it significantly outperforms existing methods like PPO, DPO, and KTO. Our results suggest that GAPO's unique approach to preferential prompt learning offers a more robust and effective solution for controlling LLM outputs. Code is avaliable in https://github.com/MikeGu721/GAPO.
LLM-GAN: Construct Generative Adversarial Network Through Large Language Models For Explainable Fake News Detection
Sep 03, 2024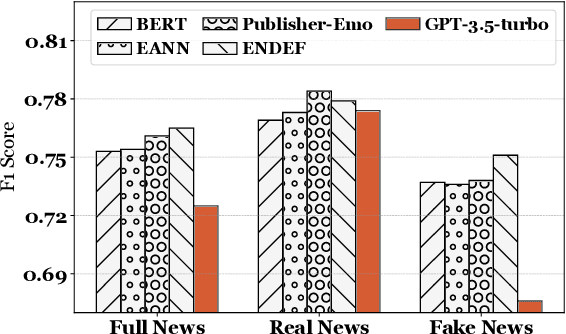
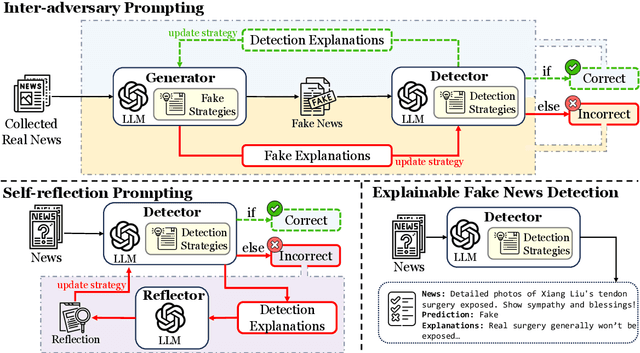
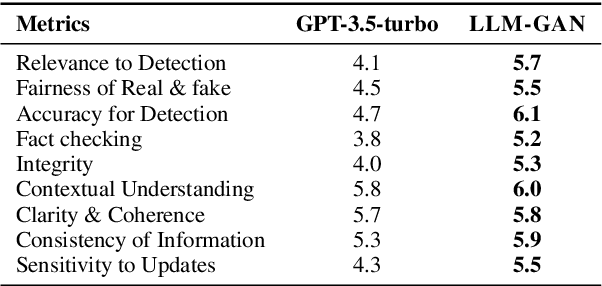
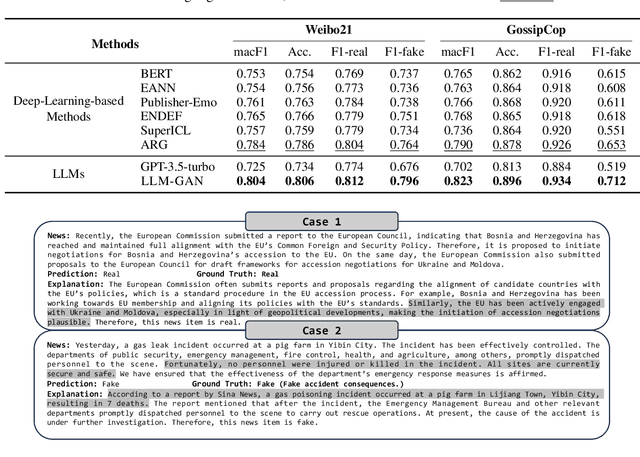
Explainable fake news detection predicts the authenticity of news items with annotated explanations. Today, Large Language Models (LLMs) are known for their powerful natural language understanding and explanation generation abilities. However, presenting LLMs for explainable fake news detection remains two main challenges. Firstly, fake news appears reasonable and could easily mislead LLMs, leaving them unable to understand the complex news-faking process. Secondly, utilizing LLMs for this task would generate both correct and incorrect explanations, which necessitates abundant labor in the loop. In this paper, we propose LLM-GAN, a novel framework that utilizes prompting mechanisms to enable an LLM to become Generator and Detector and for realistic fake news generation and detection. Our results demonstrate LLM-GAN's effectiveness in both prediction performance and explanation quality. We further showcase the integration of LLM-GAN to a cloud-native AI platform to provide better fake news detection service in the cloud.