 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogics-Parsing-Omni Technical Report
Mar 12, 2026Addressing the challenges of fragmented task definitions and the heterogeneity of unstructured data in multimodal parsing, this paper proposes the Omni Parsing framework. This framework establishes a Unified Taxonomy covering documents, images, and audio-visual streams, introducing a progressive parsing paradigm that bridges perception and cognition. Specifically, the framework integrates three hierarchical levels: 1) Holistic Detection, which achieves precise spatial-temporal grounding of objects or events to establish a geometric baseline for perception; 2) Fine-grained Recognition, which performs symbolization (e.g., OCR/ASR) and attribute extraction on localized objects to complete structured entity parsing; and 3) Multi-level Interpreting, which constructs a reasoning chain from local semantics to global logic. A pivotal advantage of this framework is its evidence anchoring mechanism, which enforces a strict alignment between high-level semantic descriptions and low-level facts. This enables ``evidence-based'' logical induction, transforming unstructured signals into standardized knowledge that is locatable, enumerable, and traceable. Building on this foundation, we constructed a standardized dataset and released the Logics-Parsing-Omni model, which successfully converts complex audio-visual signals into machine-readable structured knowledge. Experiments demonstrate that fine-grained perception and high-level cognition are synergistic, effectively enhancing model reliability. Furthermore, to quantitatively evaluate these capabilities, we introduce OmniParsingBench. Code, models and the benchmark are released at https://github.com/alibaba/Logics-Parsing/tree/master/Logics-Parsing-Omni.
Logics-STEM: Empowering LLM Reasoning via Failure-Driven Post-Training and Document Knowledge Enhancement
Jan 08, 2026We present Logics-STEM, a state-of-the-art reasoning model fine-tuned on Logics-STEM-SFT-Dataset, a high-quality and diverse dataset at 10M scale that represents one of the largest-scale open-source long chain-of-thought corpora. Logics-STEM targets reasoning tasks in the domains of Science, Technology, Engineering, and Mathematics (STEM), and exhibits exceptional performance on STEM-related benchmarks with an average improvement of 4.68% over the next-best model at 8B scale. We attribute the gains to our data-algorithm co-design engine, where they are jointly optimized to fit a gold-standard distribution behind reasoning. Data-wise, the Logics-STEM-SFT-Dataset is constructed from a meticulously designed data curation engine with 5 stages to ensure the quality, diversity, and scalability, including annotation, deduplication, decontamination, distillation, and stratified sampling. Algorithm-wise, our failure-driven post-training framework leverages targeted knowledge retrieval and data synthesis around model failure regions in the Supervised Fine-tuning (SFT) stage to effectively guide the second-stage SFT or the reinforcement learning (RL) for better fitting the target distribution. The superior empirical performance of Logics-STEM reveals the vast potential of combining large-scale open-source data with carefully designed synthetic data, underscoring the critical role of data-algorithm co-design in enhancing reasoning capabilities through post-training. We make both the Logics-STEM models (8B and 32B) and the Logics-STEM-SFT-Dataset (10M and downsampled 2.2M versions) publicly available to support future research in the open-source community.
A Physical Coherence Benchmark for Evaluating Video Generation Models via Optical Flow-guided Frame Prediction
Feb 08, 2025



Recent advances in video generation models demonstrate their potential as world simulators, but they often struggle with videos deviating from physical laws, a key concern overlooked by most text-to-video benchmarks. We introduce a benchmark designed specifically to assess the Physical Coherence of generated videos, PhyCoBench. Our benchmark includes 120 prompts covering 7 categories of physical principles, capturing key physical laws observable in video content. We evaluated four state-of-the-art (SoTA) T2V models on PhyCoBench and conducted manual assessments. Additionally, we propose an automated evaluation model: PhyCoPredictor, a diffusion model that generates optical flow and video frames in a cascade manner. Through a consistency evaluation comparing automated and manual sorting, the experimental results show that PhyCoPredictor currently aligns most closely with human evaluation. Therefore, it can effectively evaluate the physical coherence of videos, providing insights for future model optimization. Our benchmark, which includes physical coherence prompts, automatic evaluation tool PhyCoPredictor, and generated video dataset, will all be released on GitHub shortly.
Bridging the Gap between Reality and Ideality of Entity Matching: A Revisiting and Benchmark Re-Construction
May 12, 2022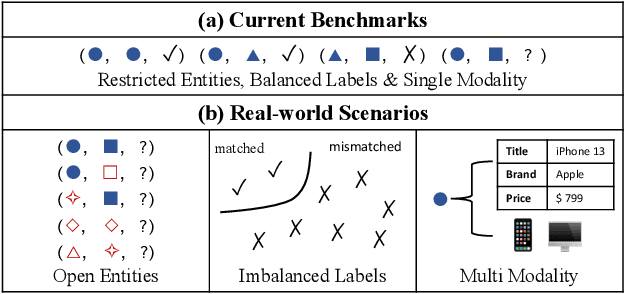
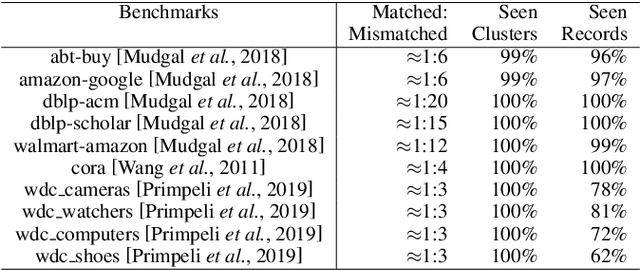
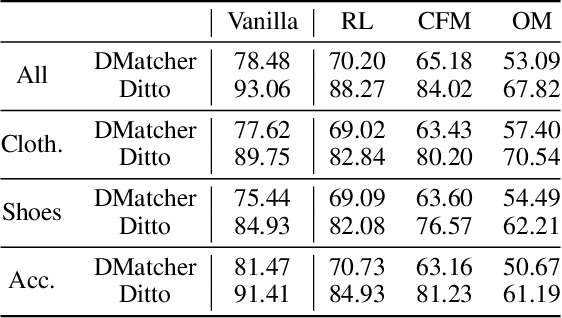

Entity matching (EM) is the most critical step for entity resolution (ER). While current deep learningbased methods achieve very impressive performance on standard EM benchmarks, their realworld application performance is much frustrating. In this paper, we highlight that such the gap between reality and ideality stems from the unreasonable benchmark construction process, which is inconsistent with the nature of entity matching and therefore leads to biased evaluations of current EM approaches. To this end, we build a new EM corpus and re-construct EM benchmarks to challenge critical assumptions implicit in the previous benchmark construction process by step-wisely changing the restricted entities, balanced labels, and single-modal records in previous benchmarks into open entities, imbalanced labels, and multimodal records in an open environment. Experimental results demonstrate that the assumptions made in the previous benchmark construction process are not coincidental with the open environment, which conceal the main challenges of the task and therefore significantly overestimate the current progress of entity matching. The constructed benchmarks and code are publicly released