 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Quantity: Trajectory Diversity Scaling for Code Agents
Feb 03, 2026As code large language models (LLMs) evolve into tool-interactive agents via the Model Context Protocol (MCP), their generalization is increasingly limited by low-quality synthetic data and the diminishing returns of quantity scaling. Moreover, quantity-centric scaling exhibits an early bottleneck that underutilizes trajectory data. We propose TDScaling, a Trajectory Diversity Scaling-based data synthesis framework for code agents that scales performance through diversity rather than raw volume. Under a fixed training budget, increasing trajectory diversity yields larger gains than adding more trajectories, improving the performance-cost trade-off for agent training. TDScaling integrates four innovations: (1) a Business Cluster mechanism that captures real-service logical dependencies; (2) a blueprint-driven multi-agent paradigm that enforces trajectory coherence; (3) an adaptive evolution mechanism that steers synthesis toward long-tail scenarios using Domain Entropy, Reasoning Mode Entropy, and Cumulative Action Complexity to prevent mode collapse; and (4) a sandboxed code tool that mitigates catastrophic forgetting of intrinsic coding capabilities. Experiments on general tool-use benchmarks (BFCL, tau^2-Bench) and code agent tasks (RebenchT, CodeCI, BIRD) demonstrate a win-win outcome: TDScaling improves both tool-use generalization and inherent coding proficiency. We plan to release the full codebase and the synthesized dataset (including 30,000+ tool clusters) upon publication.
SoLoPO: Unlocking Long-Context Capabilities in LLMs via Short-to-Long Preference Optimization
May 16, 2025Despite advances in pretraining with extended context lengths, large language models (LLMs) still face challenges in effectively utilizing real-world long-context information, primarily due to insufficient long-context alignment caused by data quality issues, training inefficiencies, and the lack of well-designed optimization objectives. To address these limitations, we propose a framework named $\textbf{S}$h$\textbf{o}$rt-to-$\textbf{Lo}$ng $\textbf{P}$reference $\textbf{O}$ptimization ($\textbf{SoLoPO}$), decoupling long-context preference optimization (PO) into two components: short-context PO and short-to-long reward alignment (SoLo-RA), supported by both theoretical and empirical evidence. Specifically, short-context PO leverages preference pairs sampled from short contexts to enhance the model's contextual knowledge utilization ability. Meanwhile, SoLo-RA explicitly encourages reward score consistency utilization for the responses when conditioned on both short and long contexts that contain identical task-relevant information. This facilitates transferring the model's ability to handle short contexts into long-context scenarios. SoLoPO is compatible with mainstream preference optimization algorithms, while substantially improving the efficiency of data construction and training processes. Experimental results show that SoLoPO enhances all these algorithms with respect to stronger length and domain generalization abilities across various long-context benchmarks, while achieving notable improvements in both computational and memory efficiency.
IOPO: Empowering LLMs with Complex Instruction Following via Input-Output Preference Optimization
Nov 09, 2024



In the realm of large language models (LLMs), the ability of models to accurately follow instructions is paramount as more agents and applications leverage LLMs for construction, where the complexity of instructions are rapidly increasing. However, on the one hand, there is only a certain amount of complex instruction evaluation data; on the other hand, there are no dedicated algorithms to improve the ability to follow complex instructions. To this end, this paper introduces TRACE, a benchmark for improving and evaluating the complex instructionfollowing ability, which consists of 120K training data and 1K evaluation data. Furthermore, we propose IOPO (Input-Output Preference Optimization) alignment method which takes both input and output preference pairs into consideration, where LLMs not only rapidly align with response preferences but also meticulously explore the instruction preferences. Extensive experiments on both in-domain and outof-domain datasets confirm the effectiveness of IOPO, showing 8.15%, 2.18% improvements on in-domain data and 6.29%, 3.13% on outof-domain data compared to SFT and DPO respectively.
Leave No Document Behind: Benchmarking Long-Context LLMs with Extended Multi-Doc QA
Jun 25, 2024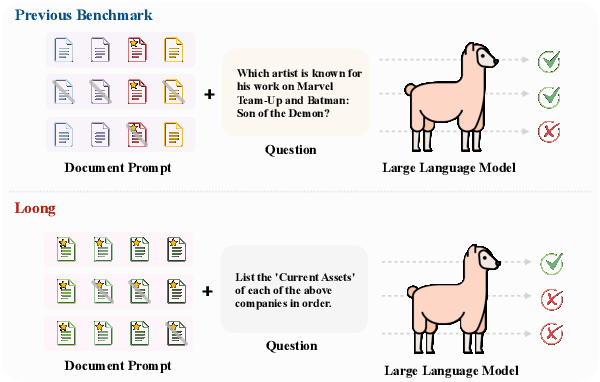
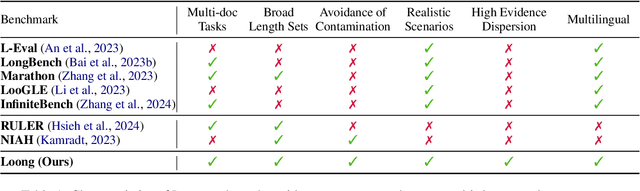
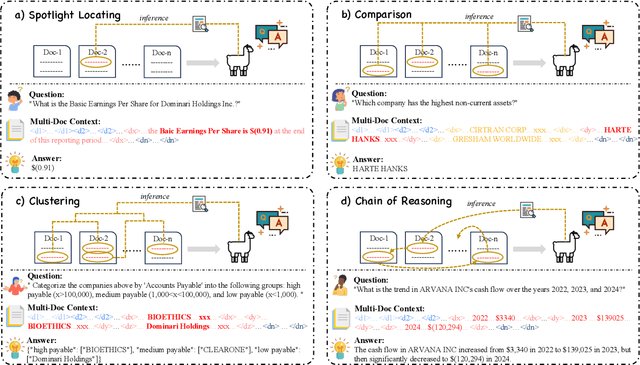

Long-context modeling capabilities have garnered widespread attention, leading to the emergence of Large Language Models (LLMs) with ultra-context windows. Meanwhile, benchmarks for evaluating long-context LLMs are gradually catching up. However, existing benchmarks employ irrelevant noise texts to artificially extend the length of test cases, diverging from the real-world scenarios of long-context applications. To bridge this gap, we propose a novel long-context benchmark, Loong, aligning with realistic scenarios through extended multi-document question answering (QA). Unlike typical document QA, in Loong's test cases, each document is relevant to the final answer, ignoring any document will lead to the failure of the answer. Furthermore, Loong introduces four types of tasks with a range of context lengths: Spotlight Locating, Comparison, Clustering, and Chain of Reasoning, to facilitate a more realistic and comprehensive evaluation of long-context understanding. Extensive experiments indicate that existing long-context language models still exhibit considerable potential for enhancement. Retrieval augmented generation (RAG) achieves poor performance, demonstrating that Loong can reliably assess the model's long-context modeling capabilities.
Self-Retrieval: Building an Information Retrieval System with One Large Language Model
Feb 23, 2024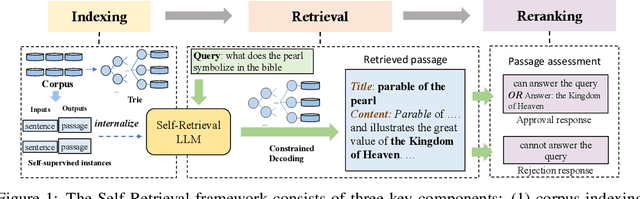
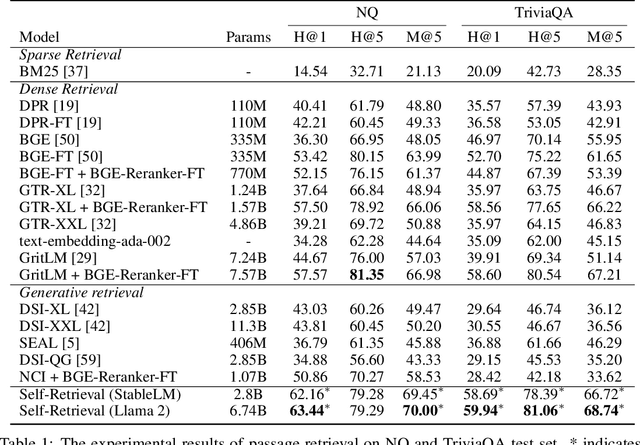
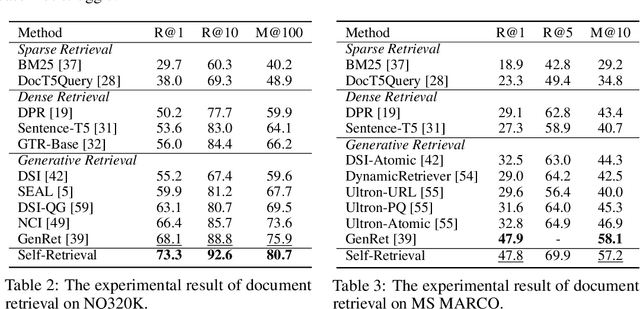
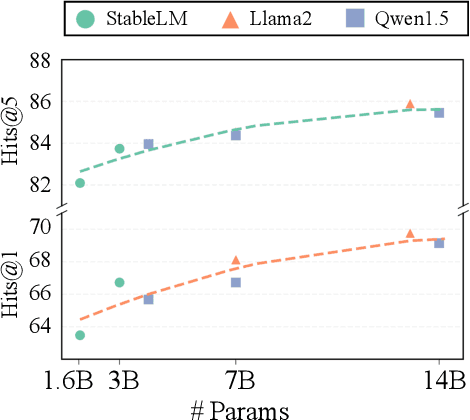
The rise of large language models (LLMs) has transformed the role of information retrieval (IR) systems in the way to humans accessing information. Due to the isolated architecture and the limited interaction, existing IR systems are unable to fully accommodate the shift from directly providing information to humans to indirectly serving large language models. In this paper, we propose Self-Retrieval, an end-to-end, LLM-driven information retrieval architecture that can fully internalize the required abilities of IR systems into a single LLM and deeply leverage the capabilities of LLMs during IR process. Specifically, Self-retrieval internalizes the corpus to retrieve into a LLM via a natural language indexing architecture. Then the entire retrieval process is redefined as a procedure of document generation and self-assessment, which can be end-to-end executed using a single large language model. Experimental results demonstrate that Self-Retrieval not only significantly outperforms previous retrieval approaches by a large margin, but also can significantly boost the performance of LLM-driven downstream applications like retrieval augumented generation.
Unified Language Representation for Question Answering over Text, Tables, and Images
Jun 29, 2023



When trying to answer complex questions, people often rely on multiple sources of information, such as visual, textual, and tabular data. Previous approaches to this problem have focused on designing input features or model structure in the multi-modal space, which is inflexible for cross-modal reasoning or data-efficient training. In this paper, we call for an alternative paradigm, which transforms the images and tables into unified language representations, so that we can simplify the task into a simpler textual QA problem that can be solved using three steps: retrieval, ranking, and generation, all within a language space. This idea takes advantage of the power of pre-trained language models and is implemented in a framework called Solar. Our experimental results show that Solar outperforms all existing methods by 10.6-32.3 pts on two datasets, MultimodalQA and MMCoQA, across ten different metrics. Additionally, Solar achieves the best performance on the WebQA leaderboard
Coarse-to-Fine Knowledge Selection for Document Grounded Dialogs
Feb 23, 2023

Multi-document grounded dialogue systems (DGDS) belong to a class of conversational agents that answer users' requests by finding supporting knowledge from a collection of documents. Most previous studies aim to improve the knowledge retrieval model or propose more effective ways to incorporate external knowledge into a parametric generation model. These methods, however, focus on retrieving knowledge from mono-granularity language units (e.g. passages, sentences, or spans in documents), which is not enough to effectively and efficiently capture precise knowledge in long documents. This paper proposes Re3G, which aims to optimize both coarse-grained knowledge retrieval and fine-grained knowledge extraction in a unified framework. Specifically, the former efficiently finds relevant passages in a retrieval-and-reranking process, whereas the latter effectively extracts finer-grain spans within those passages to incorporate into a parametric answer generation model (BART, T5). Experiments on DialDoc Shared Task demonstrate the effectiveness of our method.
Metropolitan Segment Traffic Speeds from Massive Floating Car Data in 10 Cities
Feb 17, 2023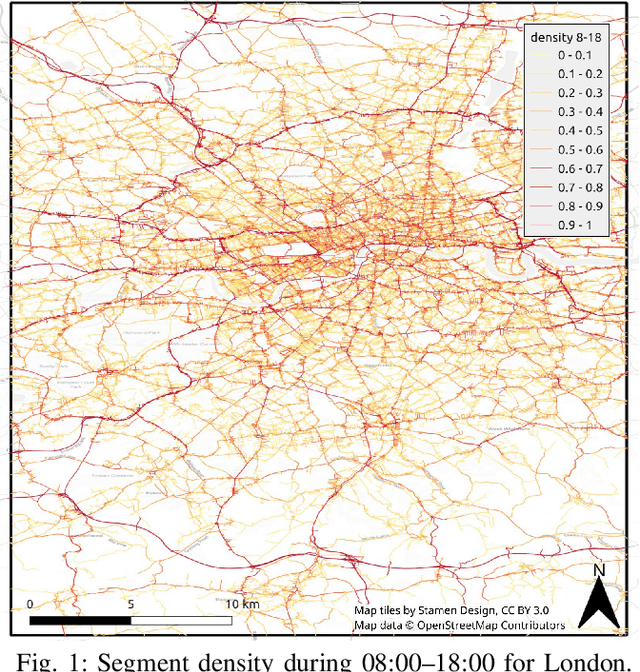
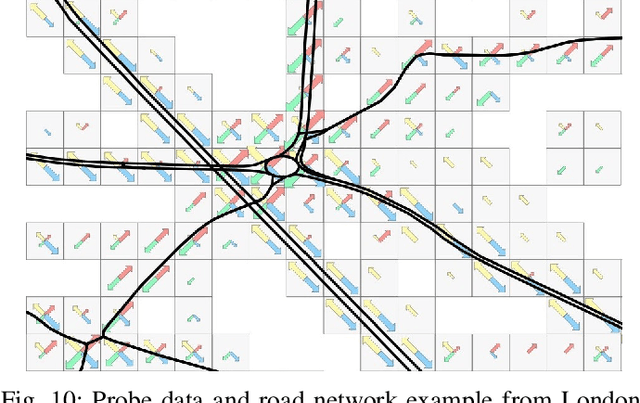
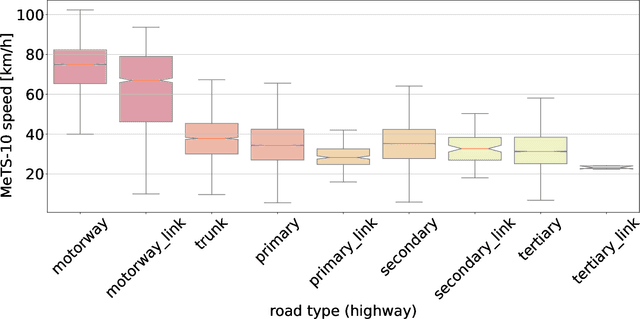
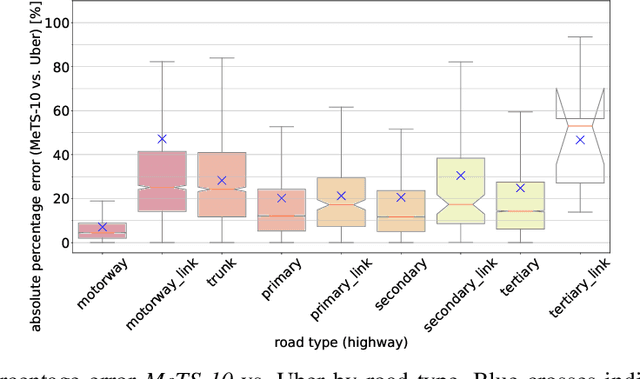
Traffic analysis is crucial for urban operations and planning, while the availability of dense urban traffic data beyond loop detectors is still scarce. We present a large-scale floating vehicle dataset of per-street segment traffic information, Metropolitan Segment Traffic Speeds from Massive Floating Car Data in 10 Cities (MeTS-10), available for 10 global cities with a 15-minute resolution for collection periods ranging between 108 and 361 days in 2019-2021 and covering more than 1500 square kilometers per metropolitan area. MeTS-10 features traffic speed information at all street levels from main arterials to local streets for Antwerp, Bangkok, Barcelona, Berlin, Chicago, Istanbul, London, Madrid, Melbourne and Moscow. The dataset leverages the industrial-scale floating vehicle Traffic4cast data with speeds and vehicle counts provided in a privacy-preserving spatio-temporal aggregation. We detail the efficient matching approach mapping the data to the OpenStreetMap road graph. We evaluate the dataset by comparing it with publicly available stationary vehicle detector data (for Berlin, London, and Madrid) and the Uber traffic speed dataset (for Barcelona, Berlin, and London). The comparison highlights the differences across datasets in spatio-temporal coverage and variations in the reported traffic caused by the binning method. MeTS-10 enables novel, city-wide analysis of mobility and traffic patterns for ten major world cities, overcoming current limitations of spatially sparse vehicle detector data. The large spatial and temporal coverage offers an opportunity for joining the MeTS-10 with other datasets, such as traffic surveys in traffic planning studies or vehicle detector data in traffic control settings.
Layout-Aware Information Extraction for Document-Grounded Dialogue: Dataset, Method and Demonstration
Jul 14, 2022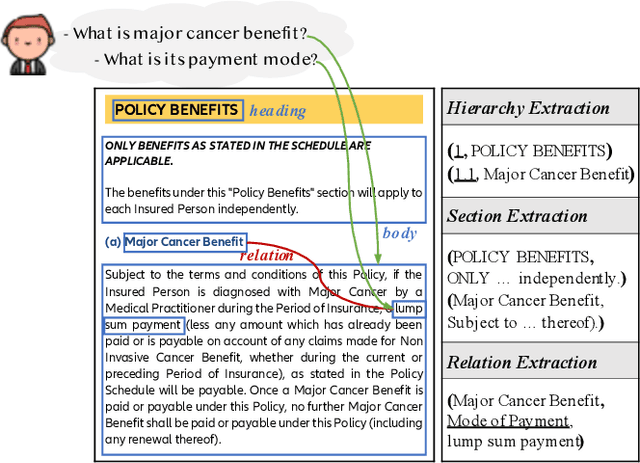
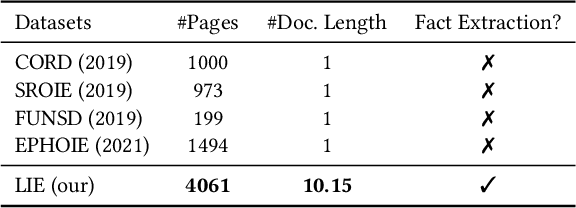

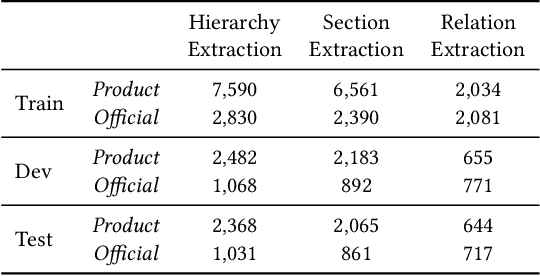
Building document-grounded dialogue systems have received growing interest as documents convey a wealth of human knowledge and commonly exist in enterprises. Wherein, how to comprehend and retrieve information from documents is a challenging research problem. Previous work ignores the visual property of documents and treats them as plain text, resulting in incomplete modality. In this paper, we propose a Layout-aware document-level Information Extraction dataset, LIE, to facilitate the study of extracting both structural and semantic knowledge from visually rich documents (VRDs), so as to generate accurate responses in dialogue systems. LIE contains 62k annotations of three extraction tasks from 4,061 pages in product and official documents, becoming the largest VRD-based information extraction dataset to the best of our knowledge. We also develop benchmark methods that extend the token-based language model to consider layout features like humans. Empirical results show that layout is critical for VRD-based extraction, and system demonstration also verifies that the extracted knowledge can help locate the answers that users care about.
Bridging the Gap between Reality and Ideality of Entity Matching: A Revisiting and Benchmark Re-Construction
May 12, 2022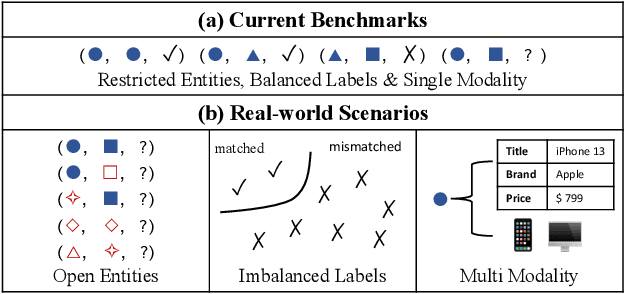
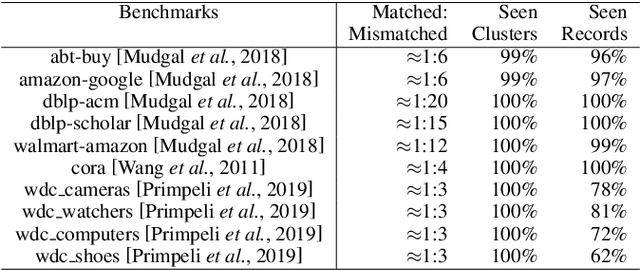
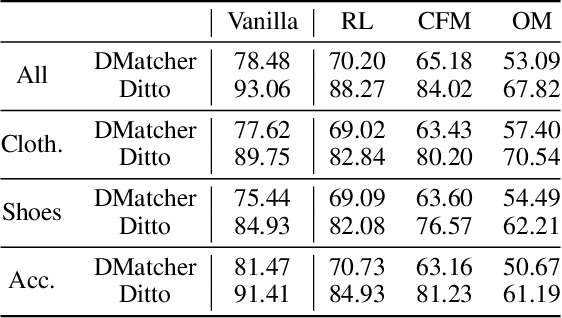

Entity matching (EM) is the most critical step for entity resolution (ER). While current deep learningbased methods achieve very impressive performance on standard EM benchmarks, their realworld application performance is much frustrating. In this paper, we highlight that such the gap between reality and ideality stems from the unreasonable benchmark construction process, which is inconsistent with the nature of entity matching and therefore leads to biased evaluations of current EM approaches. To this end, we build a new EM corpus and re-construct EM benchmarks to challenge critical assumptions implicit in the previous benchmark construction process by step-wisely changing the restricted entities, balanced labels, and single-modal records in previous benchmarks into open entities, imbalanced labels, and multimodal records in an open environment. Experimental results demonstrate that the assumptions made in the previous benchmark construction process are not coincidental with the open environment, which conceal the main challenges of the task and therefore significantly overestimate the current progress of entity matching. The constructed benchmarks and code are publicly released