 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Draft Policy Misalignment: Group Tree Optimization for Speculative Decoding
Sep 26, 2025Speculative decoding accelerates large language model (LLM) inference by letting a lightweight draft model propose multiple tokens that the target model verifies in parallel. Yet existing training objectives optimize only a single greedy draft path, while decoding follows a tree policy that re-ranks and verifies multiple branches. This draft policy misalignment limits achievable speedups. We introduce Group Tree Optimization (GTO), which aligns training with the decoding-time tree policy through two components: (i) Draft Tree Reward, a sampling-free objective equal to the expected acceptance length of the draft tree under the target model, directly measuring decoding performance; (ii) Group-based Draft Policy Training, a stable optimization scheme that contrasts trees from the current and a frozen reference draft model, forming debiased group-standardized advantages and applying a PPO-style surrogate along the longest accepted sequence for robust updates. We further prove that increasing our Draft Tree Reward provably improves acceptance length and speedup. Across dialogue (MT-Bench), code (HumanEval), and math (GSM8K), and multiple LLMs (e.g., LLaMA-3.1-8B, LLaMA-3.3-70B, Vicuna-1.3-13B, DeepSeek-R1-Distill-LLaMA-8B), GTO increases acceptance length by 7.4% and yields an additional 7.7% speedup over prior state-of-the-art EAGLE-3. By bridging draft policy misalignment, GTO offers a practical, general solution for efficient LLM inference.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
Fourier Low-rank and Sparse Tensor for Efficient Tensor Completion
May 16, 2025Tensor completion is crucial in many scientific domains with missing data problems. Traditional low-rank tensor models, including CP, Tucker, and Tensor-Train, exploit low-dimensional structures to recover missing data. However, these methods often treat all tensor modes symmetrically, failing to capture the unique spatiotemporal patterns inherent in scientific data, where the temporal component exhibits both low-frequency stability and high-frequency variations. To address this, we propose a novel model, \underline{F}ourier \underline{Lo}w-rank and \underline{S}parse \underline{T}ensor (FLoST), which decomposes the tensor along the temporal dimension using a Fourier transform. This approach captures low-frequency components with low-rank matrices and high-frequency fluctuations with sparsity, resulting in a hybrid structure that efficiently models both smooth and localized variations. Compared to the well-known tubal-rank model, which assumes low-rankness across all frequency components, FLoST requires significantly fewer parameters, making it computationally more efficient, particularly when the time dimension is large. Through theoretical analysis and empirical experiments, we demonstrate that FLoST outperforms existing tensor completion models in terms of both accuracy and computational efficiency, offering a more interpretable solution for spatiotemporal data reconstruction.
Towards Understanding Why Data Augmentation Improves Generalization
Feb 13, 2025
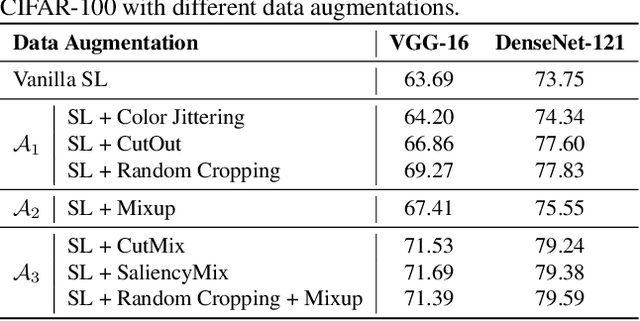


Data augmentation is a cornerstone technique in deep learning, widely used to improve model generalization. Traditional methods like random cropping and color jittering, as well as advanced techniques such as CutOut, Mixup, and CutMix, have achieved notable success across various domains. However, the mechanisms by which data augmentation improves generalization remain poorly understood, and existing theoretical analyses typically focus on individual techniques without a unified explanation. In this work, we present a unified theoretical framework that elucidates how data augmentation enhances generalization through two key effects: partial semantic feature removal and feature mixing. Partial semantic feature removal reduces the model's reliance on individual feature, promoting diverse feature learning and better generalization. Feature mixing, by scaling down original semantic features and introducing noise, increases training complexity, driving the model to develop more robust features. Advanced methods like CutMix integrate both effects, achieving complementary benefits. Our theoretical insights are further supported by experimental results, validating the effectiveness of this unified perspective.
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
Memory-Efficient 4-bit Preconditioned Stochastic Optimization
Dec 14, 2024Preconditioned stochastic optimization algorithms, exemplified by Shampoo, have demonstrated superior performance over first-order optimizers, providing both theoretical advantages in convergence rates and practical improvements in large-scale neural network training. However, they incur substantial memory overhead due to the storage demands of non-diagonal preconditioning matrices. To address this, we introduce 4-bit quantization for Shampoo's preconditioners. We introduced two key methods: First, we apply Cholesky decomposition followed by quantization of the Cholesky factors, reducing memory usage by leveraging their lower triangular structure while preserving symmetry and positive definiteness to minimize information loss. To our knowledge, this is the first quantization approach applied to Cholesky factors of preconditioners. Second, we incorporate error feedback in the quantization process, efficiently storing Cholesky factors and error states in the lower and upper triangular parts of the same matrix. Through extensive experiments, we demonstrate that combining Cholesky quantization with error feedback enhances memory efficiency and algorithm performance in large-scale deep-learning tasks. Theoretically, we also provide convergence proofs for quantized Shampoo under both smooth and non-smooth stochastic optimization settings.
Federated PCA and Estimation for Spiked Covariance Matrices: Optimal Rates and Efficient Algorithm
Nov 23, 2024


Federated Learning (FL) has gained significant recent attention in machine learning for its enhanced privacy and data security, making it indispensable in fields such as healthcare, finance, and personalized services. This paper investigates federated PCA and estimation for spiked covariance matrices under distributed differential privacy constraints. We establish minimax rates of convergence, with a key finding that the central server's optimal rate is the harmonic mean of the local clients' minimax rates. This guarantees consistent estimation at the central server as long as at least one local client provides consistent results. Notably, consistency is maintained even if some local estimators are inconsistent, provided there are enough clients. These findings highlight the robustness and scalability of FL for reliable statistical inference under privacy constraints. To establish minimax lower bounds, we derive a matrix version of van Trees' inequality, which is of independent interest. Furthermore, we propose an efficient algorithm that preserves differential privacy while achieving near-optimal rates at the central server, up to a logarithmic factor. We address significant technical challenges in analyzing this algorithm, which involves a three-layer spectral decomposition. Numerical performance of the proposed algorithm is investigated using both simulated and real data.
Towards Understanding Why FixMatch Generalizes Better Than Supervised Learning
Oct 15, 2024



Semi-supervised learning (SSL), exemplified by FixMatch (Sohn et al., 2020), has shown significant generalization advantages over supervised learning (SL), particularly in the context of deep neural networks (DNNs). However, it is still unclear, from a theoretical standpoint, why FixMatch-like SSL algorithms generalize better than SL on DNNs. In this work, we present the first theoretical justification for the enhanced test accuracy observed in FixMatch-like SSL applied to DNNs by taking convolutional neural networks (CNNs) on classification tasks as an example. Our theoretical analysis reveals that the semantic feature learning processes in FixMatch and SL are rather different. In particular, FixMatch learns all the discriminative features of each semantic class, while SL only randomly captures a subset of features due to the well-known lottery ticket hypothesis. Furthermore, we show that our analysis framework can be applied to other FixMatch-like SSL methods, e.g., FlexMatch, FreeMatch, Dash, and SoftMatch. Inspired by our theoretical analysis, we develop an improved variant of FixMatch, termed Semantic-Aware FixMatch (SA-FixMatch). Experimental results corroborate our theoretical findings and the enhanced generalization capability of SA-FixMatch.
Online Policy Learning and Inference by Matrix Completion
Apr 26, 2024Making online decisions can be challenging when features are sparse and orthogonal to historical ones, especially when the optimal policy is learned through collaborative filtering. We formulate the problem as a matrix completion bandit (MCB), where the expected reward under each arm is characterized by an unknown low-rank matrix. The $\epsilon$-greedy bandit and the online gradient descent algorithm are explored. Policy learning and regret performance are studied under a specific schedule for exploration probabilities and step sizes. A faster decaying exploration probability yields smaller regret but learns the optimal policy less accurately. We investigate an online debiasing method based on inverse propensity weighting (IPW) and a general framework for online policy inference. The IPW-based estimators are asymptotically normal under mild arm-optimality conditions. Numerical simulations corroborate our theoretical findings. Our methods are applied to the San Francisco parking pricing project data, revealing intriguing discoveries and outperforming the benchmark policy.
Towards More Faithful Natural Language Explanation Using Multi-Level Contrastive Learning in VQA
Dec 21, 2023



Natural language explanation in visual question answer (VQA-NLE) aims to explain the decision-making process of models by generating natural language sentences to increase users' trust in the black-box systems. Existing post-hoc methods have achieved significant progress in obtaining a plausible explanation. However, such post-hoc explanations are not always aligned with human logical inference, suffering from the issues on: 1) Deductive unsatisfiability, the generated explanations do not logically lead to the answer; 2) Factual inconsistency, the model falsifies its counterfactual explanation for answers without considering the facts in images; and 3) Semantic perturbation insensitivity, the model can not recognize the semantic changes caused by small perturbations. These problems reduce the faithfulness of explanations generated by models. To address the above issues, we propose a novel self-supervised \textbf{M}ulti-level \textbf{C}ontrastive \textbf{L}earning based natural language \textbf{E}xplanation model (MCLE) for VQA with semantic-level, image-level, and instance-level factual and counterfactual samples. MCLE extracts discriminative features and aligns the feature spaces from explanations with visual question and answer to generate more consistent explanations. We conduct extensive experiments, ablation analysis, and case study to demonstrate the effectiveness of our method on two VQA-NLE benchmarks.