 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonconvex Stochastic Bregman Proximal Gradient Method with Application to Deep Learning
Paper and Code
Jun 29, 2023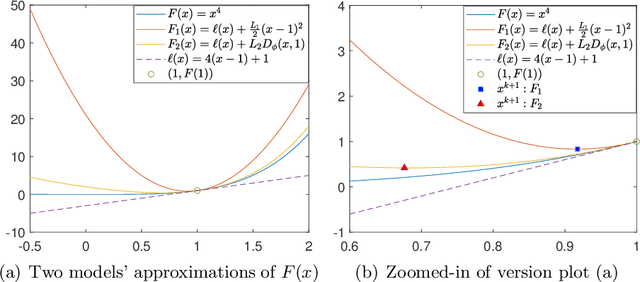



The widely used stochastic gradient methods for minimizing nonconvex composite objective functions require the Lipschitz smoothness of the differentiable part. But the requirement does not hold true for problem classes including quadratic inverse problems and training neural networks. To address this issue, we investigate a family of stochastic Bregman proximal gradient (SBPG) methods, which only require smooth adaptivity of the differentiable part. SBPG replaces the upper quadratic approximation used in SGD with the Bregman proximity measure, resulting in a better approximation model that captures the non-Lipschitz gradients of the nonconvex objective. We formulate the vanilla SBPG and establish its convergence properties under nonconvex setting without finite-sum structure. Experimental results on quadratic inverse problems testify the robustness of SBPG. Moreover, we propose a momentum-based version of SBPG (MSBPG) and prove it has improved convergence properties. We apply MSBPG to the training of deep neural networks with a polynomial kernel function, which ensures the smooth adaptivity of the loss function. Experimental results on representative benchmarks demonstrate the effectiveness and robustness of MSBPG in training neural networks. Since the additional computation cost of MSBPG compared with SGD is negligible in large-scale optimization, MSBPG can potentially be employed as an universal open-source optimizer in the future.