 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Decomposition Paradigm for Graph-structured Nonlinear Programs via Message Passing
Dec 31, 2025We study finite-sum nonlinear programs whose decision variables interact locally according to a graph or hypergraph. We propose MP-Jacobi (Message Passing-Jacobi), a graph-compliant decentralized framework that couples min-sum message passing with Jacobi block updates. The (hyper)graph is partitioned into tree clusters. At each iteration, agents update in parallel by solving a cluster subproblem whose objective decomposes into (i) an intra-cluster term evaluated by a single min-sum sweep on the cluster tree (cost-to-go messages) and (ii) inter-cluster couplings handled via a Jacobi correction using neighbors' latest iterates. This design uses only single-hop communication and yields a convergent message-passing method on loopy graphs. For strongly convex objectives we establish global linear convergence and explicit rates that quantify how curvature, coupling strength, and the chosen partition affect scalability and provide guidance for clustering. To mitigate the computation and communication cost of exact message updates, we develop graph-compliant surrogates that preserve convergence while reducing per-iteration complexity. We further extend MP-Jacobi to hypergraphs; in heavily overlapping regimes, a surrogate-based hyperedge-splitting scheme restores finite-time intra-cluster message updates and maintains convergence. Experiments validate the theory and show consistent improvements over decentralized gradient baselines.
Memory-Efficient 4-bit Preconditioned Stochastic Optimization
Dec 14, 2024Preconditioned stochastic optimization algorithms, exemplified by Shampoo, have demonstrated superior performance over first-order optimizers, providing both theoretical advantages in convergence rates and practical improvements in large-scale neural network training. However, they incur substantial memory overhead due to the storage demands of non-diagonal preconditioning matrices. To address this, we introduce 4-bit quantization for Shampoo's preconditioners. We introduced two key methods: First, we apply Cholesky decomposition followed by quantization of the Cholesky factors, reducing memory usage by leveraging their lower triangular structure while preserving symmetry and positive definiteness to minimize information loss. To our knowledge, this is the first quantization approach applied to Cholesky factors of preconditioners. Second, we incorporate error feedback in the quantization process, efficiently storing Cholesky factors and error states in the lower and upper triangular parts of the same matrix. Through extensive experiments, we demonstrate that combining Cholesky quantization with error feedback enhances memory efficiency and algorithm performance in large-scale deep-learning tasks. Theoretically, we also provide convergence proofs for quantized Shampoo under both smooth and non-smooth stochastic optimization settings.
Optimization Hyper-parameter Laws for Large Language Models
Sep 07, 2024



Large Language Models have driven significant AI advancements, yet their training is resource-intensive and highly sensitive to hyper-parameter selection. While scaling laws provide valuable guidance on model size and data requirements, they fall short in choosing dynamic hyper-parameters, such as learning-rate (LR) schedules, that evolve during training. To bridge this gap, we present Optimization Hyper-parameter Laws (Opt-Laws), a framework that effectively captures the relationship between hyper-parameters and training outcomes, enabling the pre-selection of potential optimal schedules. Grounded in stochastic differential equations, Opt-Laws introduce novel mathematical interpretability and offer a robust theoretical foundation for some popular LR schedules. Our extensive validation across diverse model sizes and data scales demonstrates Opt-Laws' ability to accurately predict training loss and identify optimal LR schedule candidates in pre-training, continual training, and fine-tuning scenarios. This approach significantly reduces computational costs while enhancing overall model performance.
Developing Lagrangian-based Methods for Nonsmooth Nonconvex Optimization
Apr 15, 2024In this paper, we consider the minimization of a nonsmooth nonconvex objective function $f(x)$ over a closed convex subset $\mathcal{X}$ of $\mathbb{R}^n$, with additional nonsmooth nonconvex constraints $c(x) = 0$. We develop a unified framework for developing Lagrangian-based methods, which takes a single-step update to the primal variables by some subgradient methods in each iteration. These subgradient methods are ``embedded'' into our framework, in the sense that they are incorporated as black-box updates to the primal variables. We prove that our proposed framework inherits the global convergence guarantees from these embedded subgradient methods under mild conditions. In addition, we show that our framework can be extended to solve constrained optimization problems with expectation constraints. Based on the proposed framework, we show that a wide range of existing stochastic subgradient methods, including the proximal SGD, proximal momentum SGD, and proximal ADAM, can be embedded into Lagrangian-based methods. Preliminary numerical experiments on deep learning tasks illustrate that our proposed framework yields efficient variants of Lagrangian-based methods with convergence guarantees for nonconvex nonsmooth constrained optimization problems.
Adam-family Methods with Decoupled Weight Decay in Deep Learning
Oct 13, 2023In this paper, we investigate the convergence properties of a wide class of Adam-family methods for minimizing quadratically regularized nonsmooth nonconvex optimization problems, especially in the context of training nonsmooth neural networks with weight decay. Motivated by the AdamW method, we propose a novel framework for Adam-family methods with decoupled weight decay. Within our framework, the estimators for the first-order and second-order moments of stochastic subgradients are updated independently of the weight decay term. Under mild assumptions and with non-diminishing stepsizes for updating the primary optimization variables, we establish the convergence properties of our proposed framework. In addition, we show that our proposed framework encompasses a wide variety of well-known Adam-family methods, hence offering convergence guarantees for these methods in the training of nonsmooth neural networks. More importantly, we show that our proposed framework asymptotically approximates the SGD method, thereby providing an explanation for the empirical observation that decoupled weight decay enhances generalization performance for Adam-family methods. As a practical application of our proposed framework, we propose a novel Adam-family method named Adam with Decoupled Weight Decay (AdamD), and establish its convergence properties under mild conditions. Numerical experiments demonstrate that AdamD outperforms Adam and is comparable to AdamW, in the aspects of both generalization performance and efficiency.
Nonconvex Stochastic Bregman Proximal Gradient Method with Application to Deep Learning
Jun 29, 2023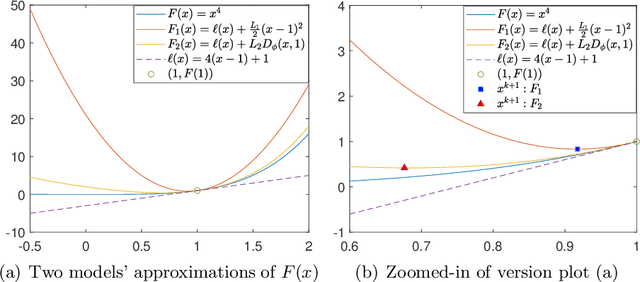



The widely used stochastic gradient methods for minimizing nonconvex composite objective functions require the Lipschitz smoothness of the differentiable part. But the requirement does not hold true for problem classes including quadratic inverse problems and training neural networks. To address this issue, we investigate a family of stochastic Bregman proximal gradient (SBPG) methods, which only require smooth adaptivity of the differentiable part. SBPG replaces the upper quadratic approximation used in SGD with the Bregman proximity measure, resulting in a better approximation model that captures the non-Lipschitz gradients of the nonconvex objective. We formulate the vanilla SBPG and establish its convergence properties under nonconvex setting without finite-sum structure. Experimental results on quadratic inverse problems testify the robustness of SBPG. Moreover, we propose a momentum-based version of SBPG (MSBPG) and prove it has improved convergence properties. We apply MSBPG to the training of deep neural networks with a polynomial kernel function, which ensures the smooth adaptivity of the loss function. Experimental results on representative benchmarks demonstrate the effectiveness and robustness of MSBPG in training neural networks. Since the additional computation cost of MSBPG compared with SGD is negligible in large-scale optimization, MSBPG can potentially be employed as an universal open-source optimizer in the future.