 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
A Unified View of Delta Parameter Editing in Post-Trained Large-Scale Models
Oct 17, 2024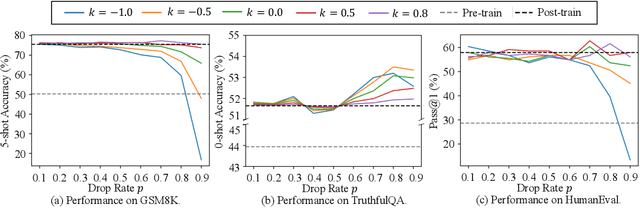
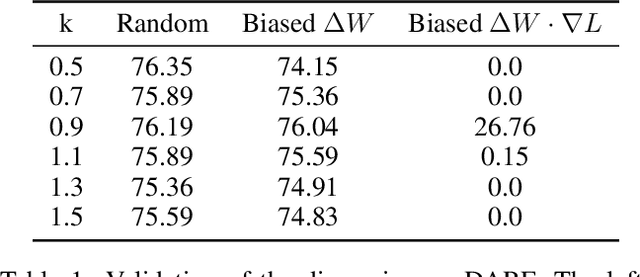
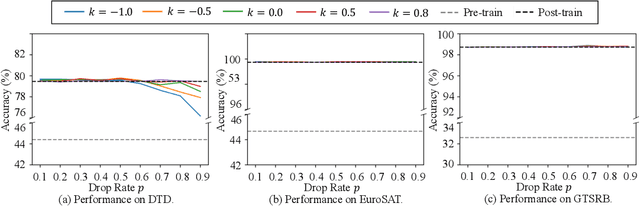
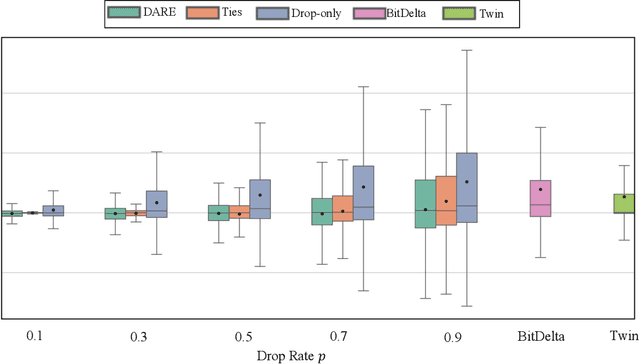
Post-training has emerged as a crucial paradigm for adapting large-scale pre-trained models to various tasks, whose effects are fully reflected by delta parameters (i.e., the disparity between post-trained and pre-trained parameters). While numerous studies have explored delta parameter properties via operations like pruning, quantization, low-rank approximation, and extrapolation, a unified framework for systematically examining these characteristics has been lacking. In this paper, we propose a novel perspective based on Riemann sum approximation of the loss function to elucidate delta parameter editing operations. Our analysis categorizes existing methods into three classes based on their post-editing performance: competitive, decreased, and improved, explaining how they are expressed by the Riemann sum approximation term and how they alter the model performance. Extensive experiments on both visual and language models, including ViT, LLaMA 3, Qwen 2, and Mistral, corroborate our theoretical findings. Furthermore, we introduce extensions to existing techniques like DARE and BitDelta, highlighting their limitations in leveraging the properties of delta parameters and reorganizing them into general expressions to enhance the applicability and effectiveness of delta parameter editing in post-trained models.
StructRAG: Boosting Knowledge Intensive Reasoning of LLMs via Inference-time Hybrid Information Structurization
Oct 11, 2024



Retrieval-augmented generation (RAG) is a key means to effectively enhance large language models (LLMs) in many knowledge-based tasks. However, existing RAG methods struggle with knowledge-intensive reasoning tasks, because useful information required to these tasks are badly scattered. This characteristic makes it difficult for existing RAG methods to accurately identify key information and perform global reasoning with such noisy augmentation. In this paper, motivated by the cognitive theories that humans convert raw information into various structured knowledge when tackling knowledge-intensive reasoning, we proposes a new framework, StructRAG, which can identify the optimal structure type for the task at hand, reconstruct original documents into this structured format, and infer answers based on the resulting structure. Extensive experiments across various knowledge-intensive tasks show that StructRAG achieves state-of-the-art performance, particularly excelling in challenging scenarios, demonstrating its potential as an effective solution for enhancing LLMs in complex real-world applications.
Self-Retrieval: Building an Information Retrieval System with One Large Language Model
Feb 23, 2024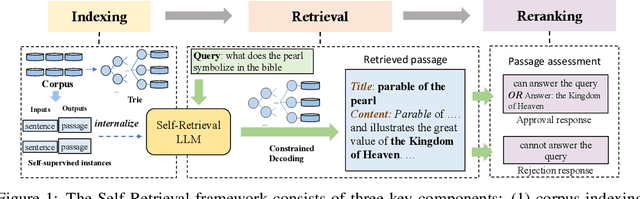
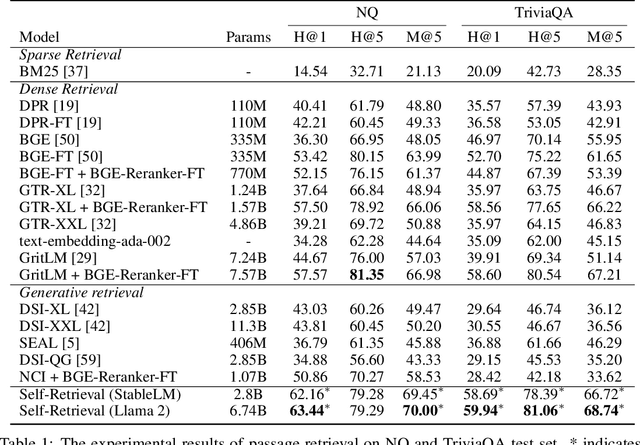
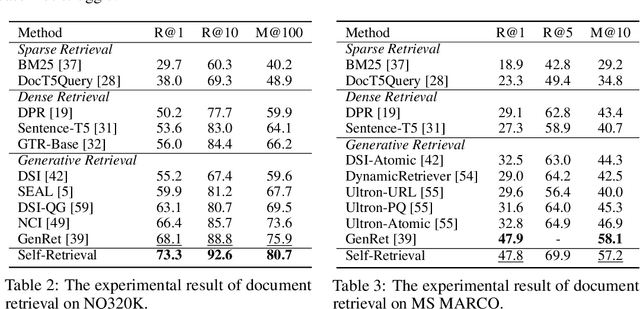
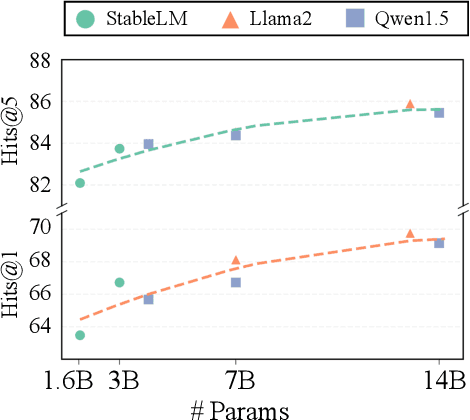
The rise of large language models (LLMs) has transformed the role of information retrieval (IR) systems in the way to humans accessing information. Due to the isolated architecture and the limited interaction, existing IR systems are unable to fully accommodate the shift from directly providing information to humans to indirectly serving large language models. In this paper, we propose Self-Retrieval, an end-to-end, LLM-driven information retrieval architecture that can fully internalize the required abilities of IR systems into a single LLM and deeply leverage the capabilities of LLMs during IR process. Specifically, Self-retrieval internalizes the corpus to retrieve into a LLM via a natural language indexing architecture. Then the entire retrieval process is redefined as a procedure of document generation and self-assessment, which can be end-to-end executed using a single large language model. Experimental results demonstrate that Self-Retrieval not only significantly outperforms previous retrieval approaches by a large margin, but also can significantly boost the performance of LLM-driven downstream applications like retrieval augumented generation.
ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases
Jun 08, 2023



Enabling large language models to effectively utilize real-world tools is crucial for achieving embodied intelligence. Existing approaches to tool learning have primarily relied on either extremely large language models, such as GPT-4, to attain generalized tool-use abilities in a zero-shot manner, or have utilized supervised learning to train limited types of tools on compact models. However, it remains uncertain whether smaller language models can achieve generalized tool-use abilities without specific tool-specific training. To address this question, this paper introduces ToolAlpaca, a novel framework designed to automatically generate a tool-use corpus and learn generalized tool-use abilities on compact language models with minimal human intervention. Specifically, ToolAlpaca first collects a comprehensive dataset by building a multi-agent simulation environment, which contains 3938 tool-use instances from more than 400 real-world tool APIs spanning 50 distinct categories. Subsequently, the constructed corpus is employed to fine-tune compact language models, resulting in two models, namely ToolAlpaca-7B and ToolAlpaca-13B, respectively. Finally, we evaluate the ability of these models to utilize previously unseen tools without specific training. Experimental results demonstrate that ToolAlpaca achieves effective generalized tool-use capabilities comparable to those of extremely large language models like GPT-3.5. This validation supports the notion that learning generalized tool-use abilities is feasible for compact language models.
Retentive or Forgetful? Diving into the Knowledge Memorizing Mechanism of Language Models
May 16, 2023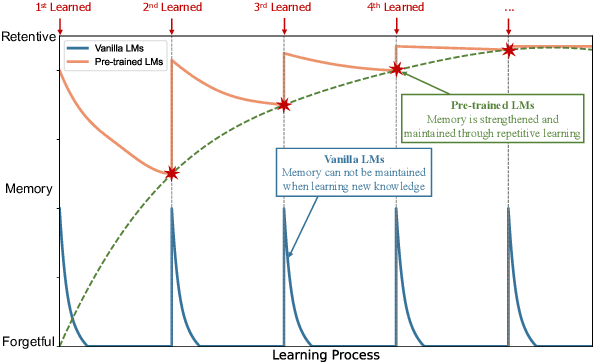



Memory is one of the most essential cognitive functions serving as a repository of world knowledge and episodes of activities. In recent years, large-scale pre-trained language models have shown remarkable memorizing ability. On the contrary, vanilla neural networks without pre-training have been long observed suffering from the catastrophic forgetting problem. To investigate such a retentive-forgetful contradiction and understand the memory mechanism of language models, we conduct thorough experiments by controlling the target knowledge types, the learning strategies and the learning schedules. We find that: 1) Vanilla language models are forgetful; 2) Pre-training leads to retentive language models; 3) Knowledge relevance and diversification significantly influence the memory formation. These conclusions are useful for understanding the abilities of pre-trained language models and shed light on designing and evaluating new learning and inference algorithms of language models.