 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetentive or Forgetful? Diving into the Knowledge Memorizing Mechanism of Language Models
Paper and Code
May 16, 2023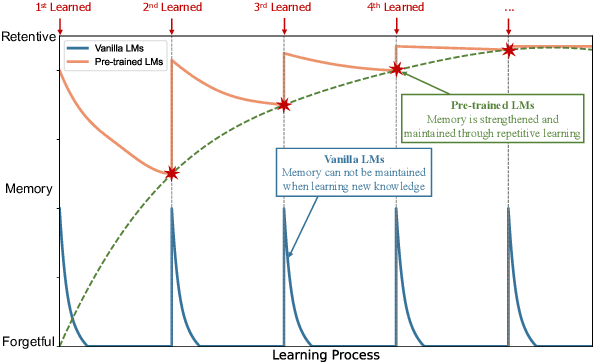



Memory is one of the most essential cognitive functions serving as a repository of world knowledge and episodes of activities. In recent years, large-scale pre-trained language models have shown remarkable memorizing ability. On the contrary, vanilla neural networks without pre-training have been long observed suffering from the catastrophic forgetting problem. To investigate such a retentive-forgetful contradiction and understand the memory mechanism of language models, we conduct thorough experiments by controlling the target knowledge types, the learning strategies and the learning schedules. We find that: 1) Vanilla language models are forgetful; 2) Pre-training leads to retentive language models; 3) Knowledge relevance and diversification significantly influence the memory formation. These conclusions are useful for understanding the abilities of pre-trained language models and shed light on designing and evaluating new learning and inference algorithms of language models.