 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll Languages Matter: Understanding and Mitigating Language Bias in Multilingual RAG
Apr 22, 2026Multilingual Retrieval-Augmented Generation (mRAG) leverages cross-lingual evidence to ground Large Language Models (LLMs) in global knowledge. However, we show that current mRAG systems suffer from a language bias during reranking, systematically favoring English and the query's native language. By introducing an estimated oracle evidence analysis, we quantify a substantial performance gap between existing rerankers and the achievable upper bound. Further analysis reveals a critical distributional mismatch: while optimal predictions require evidence scattered across multiple languages, current systems systematically suppress such ``answer-critical'' documents, thereby limiting downstream generation performance. To bridge this gap, we propose \textit{\textbf{L}anguage-\textbf{A}gnostic \textbf{U}tility-driven \textbf{R}eranker \textbf{A}lignment (LAURA)}, which aligns multilingual evidence ranking with downstream generative utility. Experiments across diverse languages and generation models show that LAURA effectively mitigates language bias and consistently improves mRAG performance.
DeepPresenter: Environment-Grounded Reflection for Agentic Presentation Generation
Feb 26, 2026Presentation generation requires deep content research, coherent visual design, and iterative refinement based on observation. However, existing presentation agents often rely on predefined workflows and fixed templates. To address this, we present DeepPresenter, an agentic framework that adapts to diverse user intents, enables effective feedback-driven refinement, and generalizes beyond a scripted pipeline. Specifically, DeepPresenter autonomously plans, renders, and revises intermediate slide artifacts to support long-horizon refinement with environmental observations. Furthermore, rather than relying on self-reflection over internal signals (e.g., reasoning traces), our environment-grounded reflection conditions the generation process on perceptual artifact states (e.g., rendered slides), enabling the system to identify and correct presentation-specific issues during execution. Results on the evaluation set covering diverse presentation-generation scenarios show that DeepPresenter achieves state-of-the-art performance, and the fine-tuned 9B model remains highly competitive at substantially lower cost. Our project is available at: https://github.com/icip-cas/PPTAgent
Beyond Local Edits: Embedding-Virtualized Knowledge for Broader Evaluation and Preservation of Model Editing
Feb 02, 2026Knowledge editing methods for large language models are commonly evaluated using predefined benchmarks that assess edited facts together with a limited set of related or neighboring knowledge. While effective, such evaluations remain confined to finite, dataset-bounded samples, leaving the broader impact of editing on the model's knowledge system insufficiently understood. To address this gap, we introduce Embedding-Virtualized Knowledge (EVK) that characterizes model knowledge through controlled perturbations in embedding space, enabling the exploration of a substantially broader and virtualized knowledge region beyond explicit data annotations. Based on EVK, we construct an embedding-level evaluation benchmark EVK-Bench that quantifies potential knowledge drift induced by editing, revealing effects that are not captured by conventional sample-based metrics. Furthermore, we propose a plug-and-play EVK-Align module that constrains embedding-level knowledge drift during editing and can be seamlessly integrated into existing editing methods. Experiments demonstrate that our approach enables more comprehensive evaluation while significantly improving knowledge preservation without sacrificing editing accuracy.
Identifying and Transferring Reasoning-Critical Neurons: Improving LLM Inference Reliability via Activation Steering
Jan 27, 2026Despite the strong reasoning capabilities of recent large language models (LLMs), achieving reliable performance on challenging tasks often requires post-training or computationally expensive sampling strategies, limiting their practical efficiency. In this work, we first show that a small subset of neurons in LLMs exhibits strong predictive correlations with reasoning correctness. Based on this observation, we propose AdaRAS (Adaptive Reasoning Activation Steering), a lightweight test-time framework that improves reasoning reliability by selectively intervening on neuron activations. AdaRAS identifies Reasoning-Critical Neurons (RCNs) via a polarity-aware mean-difference criterion and adaptively steers their activations during inference, enhancing incorrect reasoning traces while avoiding degradation on already-correct cases. Experiments on 10 mathematics and coding benchmarks demonstrate consistent improvements, including over 13% gains on AIME-24 and AIME-25. Moreover, AdaRAS exhibits strong transferability across datasets and scalability to stronger models, outperforming post-training methods without additional training or sampling cost.
AI-Salesman: Towards Reliable Large Language Model Driven Telemarketing
Nov 15, 2025Goal-driven persuasive dialogue, exemplified by applications like telemarketing, requires sophisticated multi-turn planning and strict factual faithfulness, which remains a significant challenge for even state-of-the-art Large Language Models (LLMs). A lack of task-specific data often limits previous works, and direct LLM application suffers from strategic brittleness and factual hallucination. In this paper, we first construct and release TeleSalesCorpus, the first real-world-grounded dialogue dataset for this domain. We then propose AI-Salesman, a novel framework featuring a dual-stage architecture. For the training stage, we design a Bayesian-supervised reinforcement learning algorithm that learns robust sales strategies from noisy dialogues. For the inference stage, we introduce the Dynamic Outline-Guided Agent (DOGA), which leverages a pre-built script library to provide dynamic, turn-by-turn strategic guidance. Moreover, we design a comprehensive evaluation framework that combines fine-grained metrics for key sales skills with the LLM-as-a-Judge paradigm. Experimental results demonstrate that our proposed AI-Salesman significantly outperforms baseline models in both automatic metrics and comprehensive human evaluations, showcasing its effectiveness in complex persuasive scenarios.
DeepSolution: Boosting Complex Engineering Solution Design via Tree-based Exploration and Bi-point Thinking
Feb 28, 2025Designing solutions for complex engineering challenges is crucial in human production activities. However, previous research in the retrieval-augmented generation (RAG) field has not sufficiently addressed tasks related to the design of complex engineering solutions. To fill this gap, we introduce a new benchmark, SolutionBench, to evaluate a system's ability to generate complete and feasible solutions for engineering problems with multiple complex constraints. To further advance the design of complex engineering solutions, we propose a novel system, SolutionRAG, that leverages the tree-based exploration and bi-point thinking mechanism to generate reliable solutions. Extensive experimental results demonstrate that SolutionRAG achieves state-of-the-art (SOTA) performance on the SolutionBench, highlighting its potential to enhance the automation and reliability of complex engineering solution design in real-world applications.
StructRAG: Boosting Knowledge Intensive Reasoning of LLMs via Inference-time Hybrid Information Structurization
Oct 11, 2024



Retrieval-augmented generation (RAG) is a key means to effectively enhance large language models (LLMs) in many knowledge-based tasks. However, existing RAG methods struggle with knowledge-intensive reasoning tasks, because useful information required to these tasks are badly scattered. This characteristic makes it difficult for existing RAG methods to accurately identify key information and perform global reasoning with such noisy augmentation. In this paper, motivated by the cognitive theories that humans convert raw information into various structured knowledge when tackling knowledge-intensive reasoning, we proposes a new framework, StructRAG, which can identify the optimal structure type for the task at hand, reconstruct original documents into this structured format, and infer answers based on the resulting structure. Extensive experiments across various knowledge-intensive tasks show that StructRAG achieves state-of-the-art performance, particularly excelling in challenging scenarios, demonstrating its potential as an effective solution for enhancing LLMs in complex real-world applications.
Seg2Act: Global Context-aware Action Generation for Document Logical Structuring
Oct 09, 2024



Document logical structuring aims to extract the underlying hierarchical structure of documents, which is crucial for document intelligence. Traditional approaches often fall short in handling the complexity and the variability of lengthy documents. To address these issues, we introduce Seg2Act, an end-to-end, generation-based method for document logical structuring, revisiting logical structure extraction as an action generation task. Specifically, given the text segments of a document, Seg2Act iteratively generates the action sequence via a global context-aware generative model, and simultaneously updates its global context and current logical structure based on the generated actions. Experiments on ChCatExt and HierDoc datasets demonstrate the superior performance of Seg2Act in both supervised and transfer learning settings.
READoc: A Unified Benchmark for Realistic Document Structured Extraction
Sep 08, 2024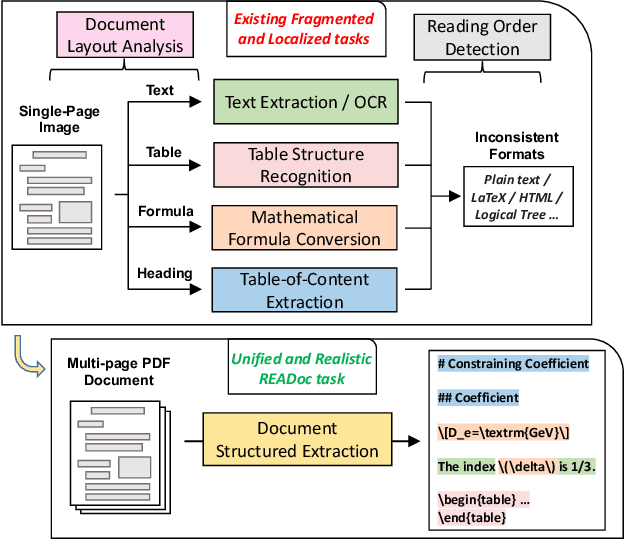


Document Structured Extraction (DSE) aims to extract structured content from raw documents. Despite the emergence of numerous DSE systems, their unified evaluation remains inadequate, significantly hindering the field's advancement. This problem is largely attributed to existing benchmark paradigms, which exhibit fragmented and localized characteristics. To address these limitations and offer a thorough evaluation of DSE systems, we introduce a novel benchmark named READoc, which defines DSE as a realistic task of converting unstructured PDFs into semantically rich Markdown. The READoc dataset is derived from 2,233 diverse and real-world documents from arXiv and GitHub. In addition, we develop a DSE Evaluation S$^3$uite comprising Standardization, Segmentation and Scoring modules, to conduct a unified evaluation of state-of-the-art DSE approaches. By evaluating a range of pipeline tools, expert visual models, and general VLMs, we identify the gap between current work and the unified, realistic DSE objective for the first time. We aspire that READoc will catalyze future research in DSE, fostering more comprehensive and practical solutions.
Offline Pseudo Relevance Feedback for Efficient and Effective Single-pass Dense Retrieval
Aug 20, 2023


Dense retrieval has made significant advancements in information retrieval (IR) by achieving high levels of effectiveness while maintaining online efficiency during a single-pass retrieval process. However, the application of pseudo relevance feedback (PRF) to further enhance retrieval effectiveness results in a doubling of online latency. To address this challenge, this paper presents a single-pass dense retrieval framework that shifts the PRF process offline through the utilization of pre-generated pseudo-queries. As a result, online retrieval is reduced to a single matching with the pseudo-queries, hence providing faster online retrieval. The effectiveness of the proposed approach is evaluated on the standard TREC DL and HARD datasets, and the results demonstrate its promise. Our code is openly available at https://github.com/Rosenberg37/OPRF.