 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
Jul 29, 2025



Creating immersive and playable 3D worlds from texts or images remains a fundamental challenge in computer vision and graphics. Existing world generation approaches typically fall into two categories: video-based methods that offer rich diversity but lack 3D consistency and rendering efficiency, and 3D-based methods that provide geometric consistency but struggle with limited training data and memory-inefficient representations. To address these limitations, we present HunyuanWorld 1.0, a novel framework that combines the best of both worlds for generating immersive, explorable, and interactive 3D scenes from text and image conditions. Our approach features three key advantages: 1) 360{\deg} immersive experiences via panoramic world proxies; 2) mesh export capabilities for seamless compatibility with existing computer graphics pipelines; 3) disentangled object representations for augmented interactivity. The core of our framework is a semantically layered 3D mesh representation that leverages panoramic images as 360{\deg} world proxies for semantic-aware world decomposition and reconstruction, enabling the generation of diverse 3D worlds. Extensive experiments demonstrate that our method achieves state-of-the-art performance in generating coherent, explorable, and interactive 3D worlds while enabling versatile applications in virtual reality, physical simulation, game development, and interactive content creation.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Jan 21, 2025



We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2
Towards Imperceptible Document Manipulations against Neural Ranking Models
May 03, 2023



Adversarial attacks have gained traction in order to identify potential vulnerabilities in neural ranking models (NRMs), but current attack methods often introduce grammatical errors, nonsensical expressions, or incoherent text fragments, which can be easily detected. Additionally, current methods rely heavily on the use of a well-imitated surrogate NRM to guarantee the attack effect, which makes them difficult to use in practice. To address these issues, we propose a framework called Imperceptible DocumEnt Manipulation (IDEM) to produce adversarial documents that are less noticeable to both algorithms and humans. IDEM instructs a well-established generative language model, such as BART, to generate connection sentences without introducing easy-to-detect errors, and employs a separate position-wise merging strategy to balance relevance and coherence of the perturbed text. Experimental results on the popular MS MARCO benchmark demonstrate that IDEM can outperform strong baselines while preserving fluency and correctness of the target documents as evidenced by automatic and human evaluations. Furthermore, the separation of adversarial text generation from the surrogate NRM makes IDEM more robust and less affected by the quality of the surrogate NRM.
Re-thinking Knowledge Graph Completion Evaluation from an Information Retrieval Perspective
May 09, 2022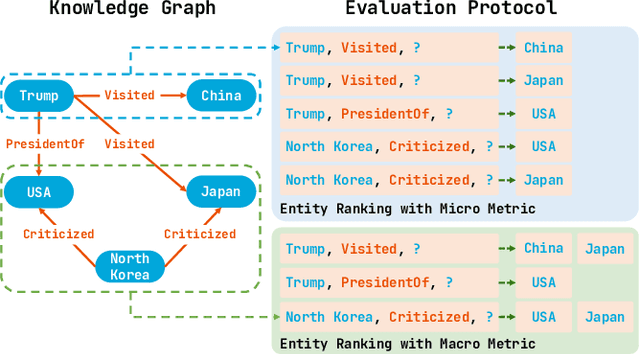
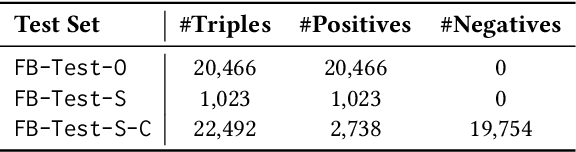
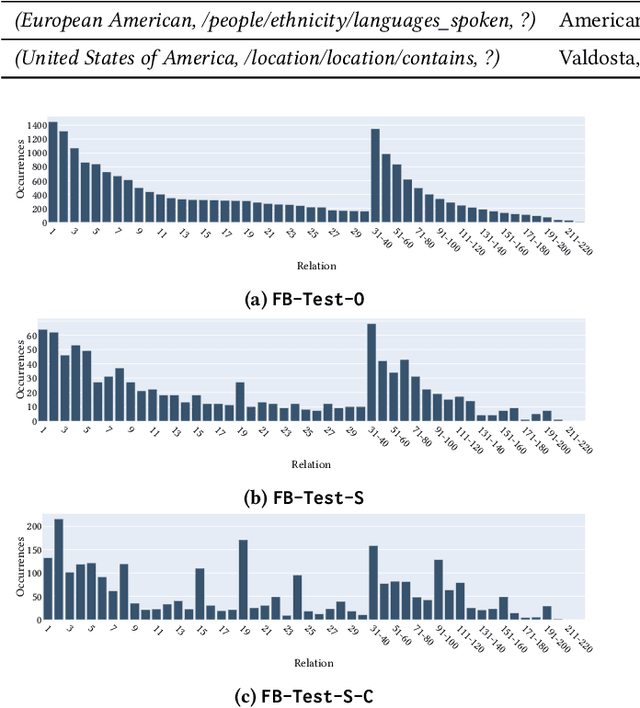

Knowledge graph completion (KGC) aims to infer missing knowledge triples based on known facts in a knowledge graph. Current KGC research mostly follows an entity ranking protocol, wherein the effectiveness is measured by the predicted rank of a masked entity in a test triple. The overall performance is then given by a micro(-average) metric over all individual answer entities. Due to the incomplete nature of the large-scale knowledge bases, such an entity ranking setting is likely affected by unlabelled top-ranked positive examples, raising questions on whether the current evaluation protocol is sufficient to guarantee a fair comparison of KGC systems. To this end, this paper presents a systematic study on whether and how the label sparsity affects the current KGC evaluation with the popular micro metrics. Specifically, inspired by the TREC paradigm for large-scale information retrieval (IR) experimentation, we create a relatively "complete" judgment set based on a sample from the popular FB15k-237 dataset following the TREC pooling method. According to our analysis, it comes as a surprise that switching from the original labels to our "complete" labels results in a drastic change of system ranking of a variety of 13 popular KGC models in terms of micro metrics. Further investigation indicates that the IR-like macro(-average) metrics are more stable and discriminative under different settings, meanwhile, less affected by label sparsity. Thus, for KGC evaluation, we recommend conducting TREC-style pooling to balance between human efforts and label completeness, and reporting also the IR-like macro metrics to reflect the ranking nature of the KGC task.
Towards Quantifiable Dialogue Coherence Evaluation
Jun 01, 2021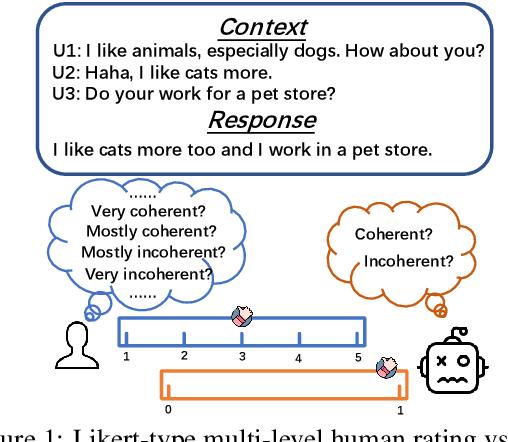
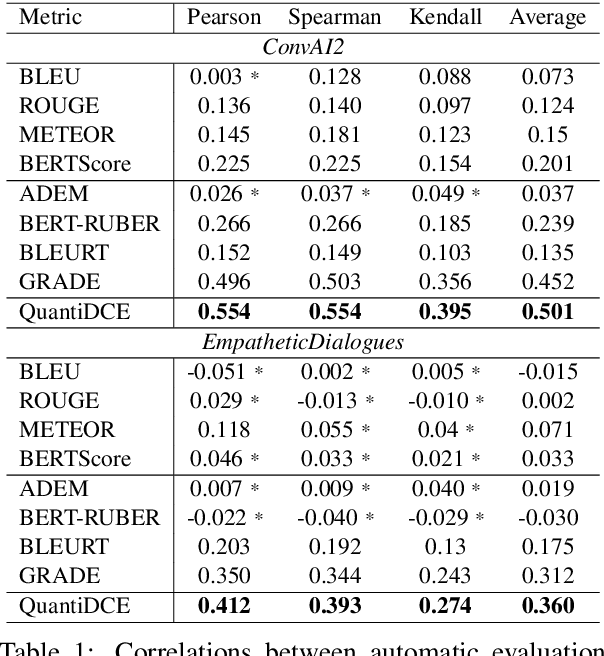
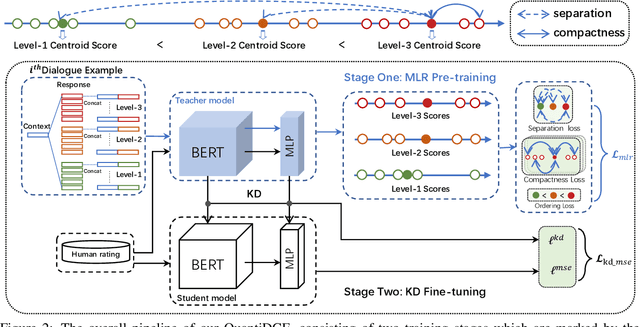
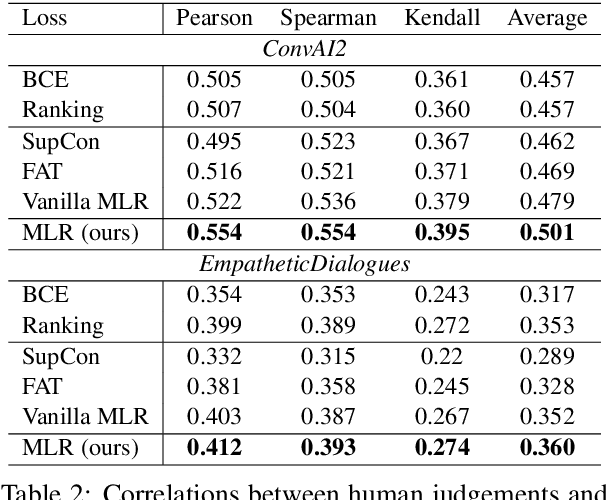
Automatic dialogue coherence evaluation has attracted increasing attention and is crucial for developing promising dialogue systems. However, existing metrics have two major limitations: (a) they are mostly trained in a simplified two-level setting (coherent vs. incoherent), while humans give Likert-type multi-level coherence scores, dubbed as "quantifiable"; (b) their predicted coherence scores cannot align with the actual human rating standards due to the absence of human guidance during training. To address these limitations, we propose Quantifiable Dialogue Coherence Evaluation (QuantiDCE), a novel framework aiming to train a quantifiable dialogue coherence metric that can reflect the actual human rating standards. Specifically, QuantiDCE includes two training stages, Multi-Level Ranking (MLR) pre-training and Knowledge Distillation (KD) fine-tuning. During MLR pre-training, a new MLR loss is proposed for enabling the model to learn the coarse judgement of coherence degrees. Then, during KD fine-tuning, the pretrained model is further finetuned to learn the actual human rating standards with only very few human-annotated data. To advocate the generalizability even with limited fine-tuning data, a novel KD regularization is introduced to retain the knowledge learned at the pre-training stage. Experimental results show that the model trained by QuantiDCE presents stronger correlations with human judgements than the other state-of-the-art metrics.
Co-BERT: A Context-Aware BERT Retrieval Model Incorporating Local and Query-specific Context
Apr 17, 2021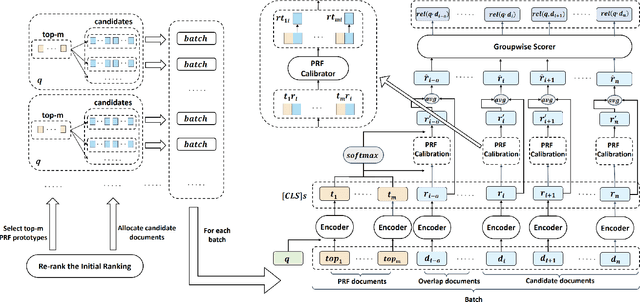
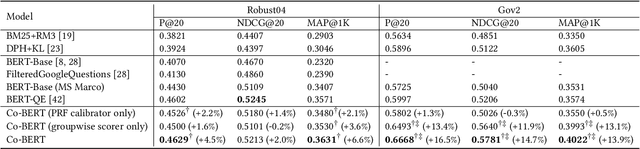
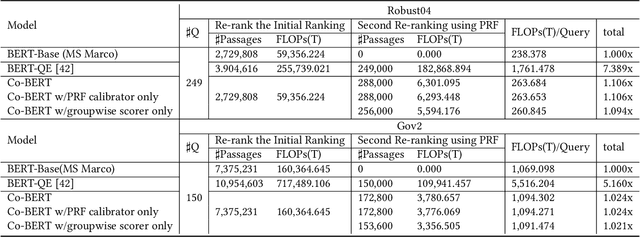

BERT-based text ranking models have dramatically advanced the state-of-the-art in ad-hoc retrieval, wherein most models tend to consider individual query-document pairs independently. In the mean time, the importance and usefulness to consider the cross-documents interactions and the query-specific characteristics in a ranking model have been repeatedly confirmed, mostly in the context of learning to rank. The BERT-based ranking model, however, has not been able to fully incorporate these two types of ranking context, thereby ignoring the inter-document relationships from the ranking and the differences among queries. To mitigate this gap, in this work, an end-to-end transformer-based ranking model, named Co-BERT, has been proposed to exploit several BERT architectures to calibrate the query-document representations using pseudo relevance feedback before modeling the relevance of a group of documents jointly. Extensive experiments on two standard test collections confirm the effectiveness of the proposed model in improving the performance of text re-ranking over strong fine-tuned BERT-Base baselines. We plan to make our implementation open source to enable further comparisons.
GRADE: Automatic Graph-Enhanced Coherence Metric for Evaluating Open-Domain Dialogue Systems
Oct 08, 2020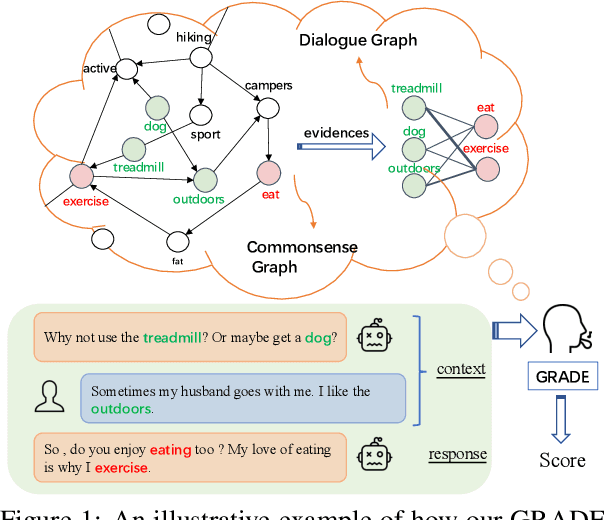
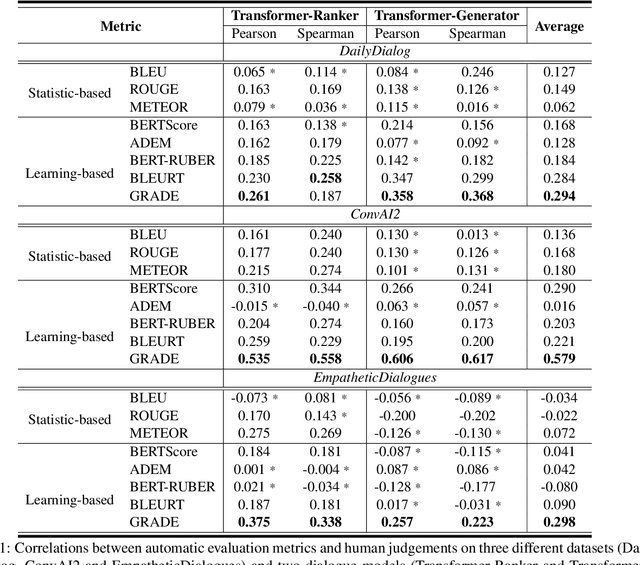
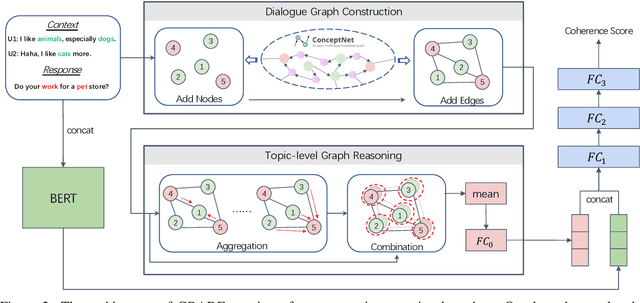
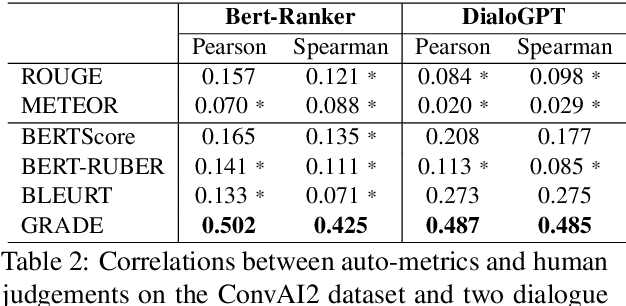
Automatically evaluating dialogue coherence is a challenging but high-demand ability for developing high-quality open-domain dialogue systems. However, current evaluation metrics consider only surface features or utterance-level semantics, without explicitly considering the fine-grained topic transition dynamics of dialogue flows. Here, we first consider that the graph structure constituted with topics in a dialogue can accurately depict the underlying communication logic, which is a more natural way to produce persuasive metrics. Capitalized on the topic-level dialogue graph, we propose a new evaluation metric GRADE, which stands for Graph-enhanced Representations for Automatic Dialogue Evaluation. Specifically, GRADE incorporates both coarse-grained utterance-level contextualized representations and fine-grained topic-level graph representations to evaluate dialogue coherence. The graph representations are obtained by reasoning over topic-level dialogue graphs enhanced with the evidence from a commonsense graph, including k-hop neighboring representations and hop-attention weights. Experimental results show that our GRADE significantly outperforms other state-of-the-art metrics on measuring diverse dialogue models in terms of the Pearson and Spearman correlations with human judgements. Besides, we release a new large-scale human evaluation benchmark to facilitate future research on automatic metrics.
Dynamic Knowledge Routing Network For Target-Guided Open-Domain Conversation
Mar 06, 2020
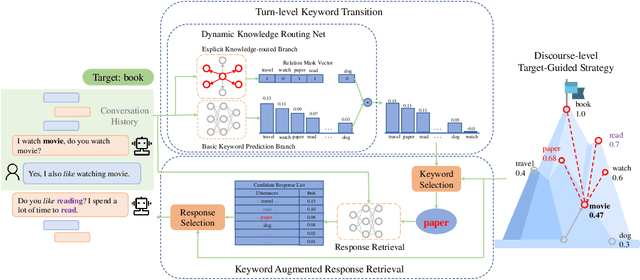
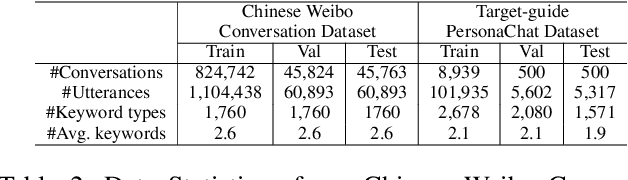
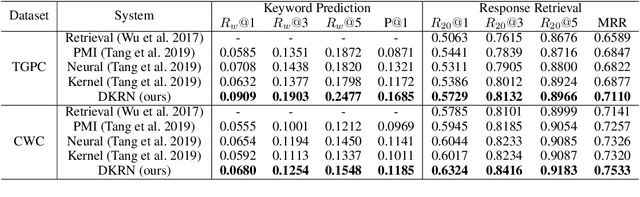
Target-guided open-domain conversation aims to proactively and naturally guide a dialogue agent or human to achieve specific goals, topics or keywords during open-ended conversations. Existing methods mainly rely on single-turn datadriven learning and simple target-guided strategy without considering semantic or factual knowledge relations among candidate topics/keywords. This results in poor transition smoothness and low success rate. In this work, we adopt a structured approach that controls the intended content of system responses by introducing coarse-grained keywords, attains smooth conversation transition through turn-level supervised learning and knowledge relations between candidate keywords, and drives an conversation towards an specified target with discourse-level guiding strategy. Specially, we propose a novel dynamic knowledge routing network (DKRN) which considers semantic knowledge relations among candidate keywords for accurate next topic prediction of next discourse. With the help of more accurate keyword prediction, our keyword-augmented response retrieval module can achieve better retrieval performance and more meaningful conversations. Besides, we also propose a novel dual discourse-level target-guided strategy to guide conversations to reach their goals smoothly with higher success rate. Furthermore, to push the research boundary of target-guided open-domain conversation to match real-world scenarios better, we introduce a new large-scale Chinese target-guided open-domain conversation dataset (more than 900K conversations) crawled from Sina Weibo. Quantitative and human evaluations show our method can produce meaningful and effective target-guided conversations, significantly improving over other state-of-the-art methods by more than 20% in success rate and more than 0.6 in average smoothness score.