 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayout-Aware Information Extraction for Document-Grounded Dialogue: Dataset, Method and Demonstration
Paper and Code
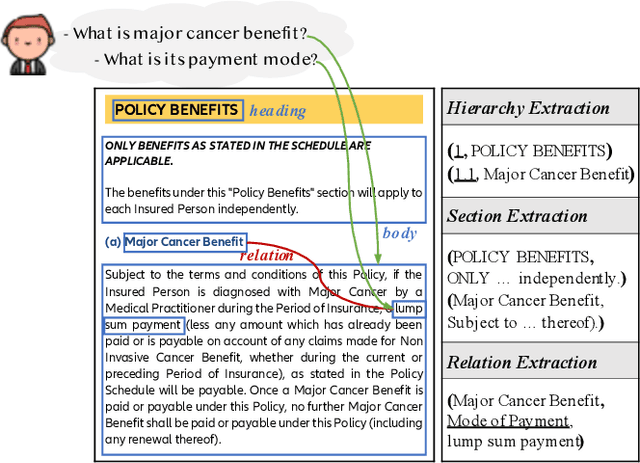
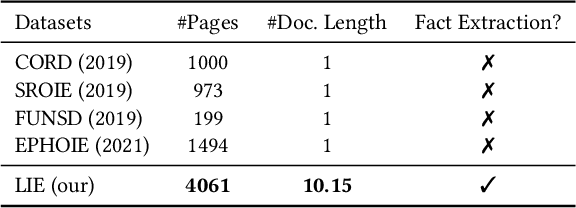

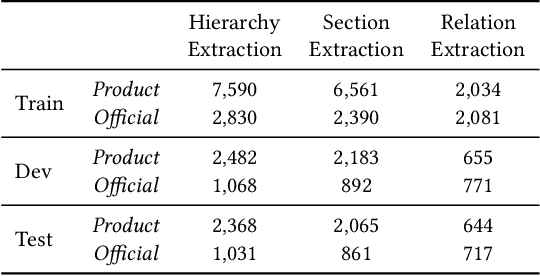
Building document-grounded dialogue systems have received growing interest as documents convey a wealth of human knowledge and commonly exist in enterprises. Wherein, how to comprehend and retrieve information from documents is a challenging research problem. Previous work ignores the visual property of documents and treats them as plain text, resulting in incomplete modality. In this paper, we propose a Layout-aware document-level Information Extraction dataset, LIE, to facilitate the study of extracting both structural and semantic knowledge from visually rich documents (VRDs), so as to generate accurate responses in dialogue systems. LIE contains 62k annotations of three extraction tasks from 4,061 pages in product and official documents, becoming the largest VRD-based information extraction dataset to the best of our knowledge. We also develop benchmark methods that extend the token-based language model to consider layout features like humans. Empirical results show that layout is critical for VRD-based extraction, and system demonstration also verifies that the extracted knowledge can help locate the answers that users care about.