 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Discovery of Interpretable Skills from Multi-Task Trajectories
Feb 01, 2026Hierarchical Imitation Learning is a powerful paradigm for acquiring complex robot behaviors from demonstrations. A central challenge, however, lies in discovering reusable skills from long-horizon, multi-task offline data, especially when the data lacks explicit rewards or subtask annotations. In this work, we introduce LOKI, a three-stage end-to-end learning framework designed for offline skill discovery and hierarchical imitation. The framework commences with a two-stage, weakly supervised skill discovery process: Stage one performs coarse, task-aware macro-segmentation by employing an alignment-enforced Vector Quantized VAE guided by weak task labels. Stage two then refines these segments at a micro-level using a self-supervised sequential model, followed by an iterative clustering process to consolidate skill boundaries. The third stage then leverages these precise boundaries to construct a hierarchical policy within an option-based framework-complete with a learned termination condition beta for explicit skill switching. LOKI achieves high success rates on the challenging D4RL Kitchen benchmark and outperforms standard HIL baselines. Furthermore, we demonstrate that the discovered skills are semantically meaningful, aligning with human intuition, and exhibit compositionality by successfully sequencing them to solve a novel, unseen task.
Hypernetwork-based approach for optimal composition design in partially controlled multi-agent systems
Feb 18, 2025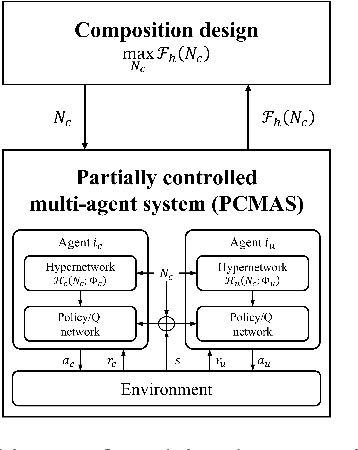

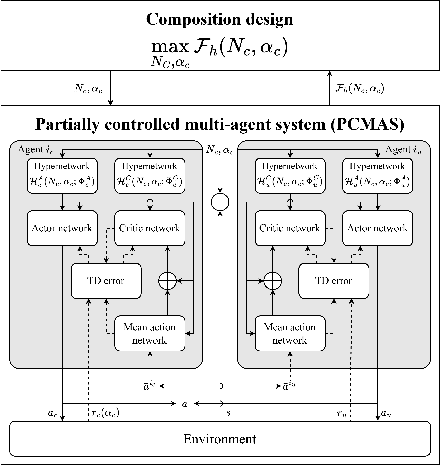

Partially Controlled Multi-Agent Systems (PCMAS) are comprised of controllable agents, managed by a system designer, and uncontrollable agents, operating autonomously. This study addresses an optimal composition design problem in PCMAS, which involves the system designer's problem, determining the optimal number and policies of controllable agents, and the uncontrollable agents' problem, identifying their best-response policies. Solving this bi-level optimization problem is computationally intensive, as it requires repeatedly solving multi-agent reinforcement learning problems under various compositions for both types of agents. To address these challenges, we propose a novel hypernetwork-based framework that jointly optimizes the system's composition and agent policies. Unlike traditional methods that train separate policy networks for each composition, the proposed framework generates policies for both controllable and uncontrollable agents through a unified hypernetwork. This approach enables efficient information sharing across similar configurations, thereby reducing computational overhead. Additional improvements are achieved by incorporating reward parameter optimization and mean action networks. Using real-world New York City taxi data, we demonstrate that our framework outperforms existing methods in approximating equilibrium policies. Our experimental results show significant improvements in key performance metrics, such as order response rate and served demand, highlighting the practical utility of controlling agents and their potential to enhance decision-making in PCMAS.
Burning RED: Unlocking Subtask-Driven Reinforcement Learning and Risk-Awareness in Average-Reward Markov Decision Processes
Oct 14, 2024Average-reward Markov decision processes (MDPs) provide a foundational framework for sequential decision-making under uncertainty. However, average-reward MDPs have remained largely unexplored in reinforcement learning (RL) settings, with the majority of RL-based efforts having been allocated to episodic and discounted MDPs. In this work, we study a unique structural property of average-reward MDPs and utilize it to introduce Reward-Extended Differential (or RED) reinforcement learning: a novel RL framework that can be used to effectively and efficiently solve various subtasks simultaneously in the average-reward setting. We introduce a family of RED learning algorithms for prediction and control, including proven-convergent algorithms for the tabular case. We then showcase the power of these algorithms by demonstrating how they can be used to learn a policy that optimizes, for the first time, the well-known conditional value-at-risk (CVaR) risk measure in a fully-online manner, without the use of an explicit bi-level optimization scheme or an augmented state-space.
Bayesian Optimization Framework for Efficient Fleet Design in Autonomous Multi-Robot Exploration
Aug 21, 2024



This study addresses the challenge of fleet design optimization in the context of heterogeneous multi-robot fleets, aiming to obtain feasible designs that balance performance and costs. In the domain of autonomous multi-robot exploration, reinforcement learning agents play a central role, offering adaptability to complex terrains and facilitating collaboration among robots. However, modifying the fleet composition results in changes in the learned behavior, and training multi-robot systems using multi-agent reinforcement learning is expensive. Therefore, an exhaustive evaluation of each potential fleet design is infeasible. To tackle these hurdles, we introduce Bayesian Optimization for Fleet Design (BOFD), a framework leveraging multi-objective Bayesian Optimization to explore fleets on the Pareto front of performance and cost while accounting for uncertainty in the design space. Moreover, we establish a sub-linear bound for cumulative regret, supporting BOFD's robustness and efficacy. Extensive benchmark experiments in synthetic and simulated environments demonstrate the superiority of our framework over state-of-the-art methods, achieving efficient fleet designs with minimal fleet evaluations.
Unsupervised Few-shot Learning via Deep Laplacian Eigenmaps
Oct 07, 2022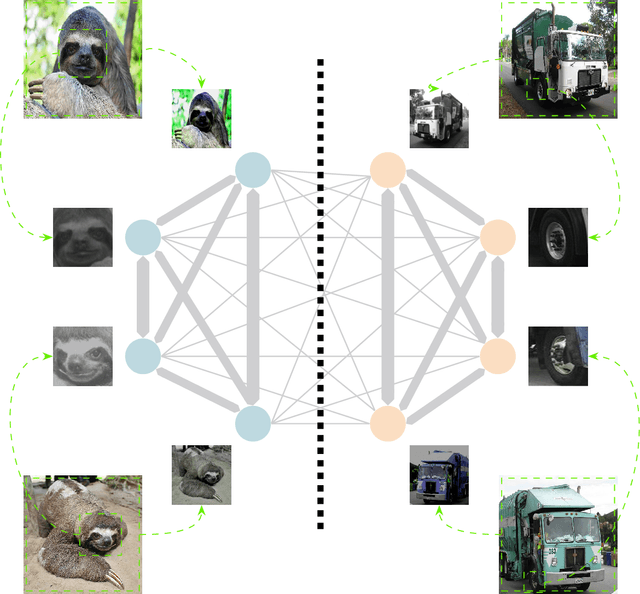
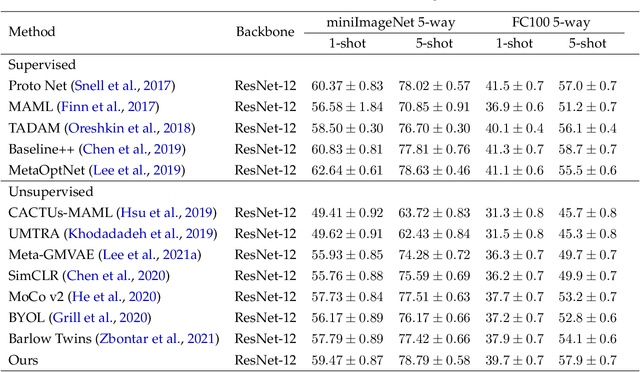
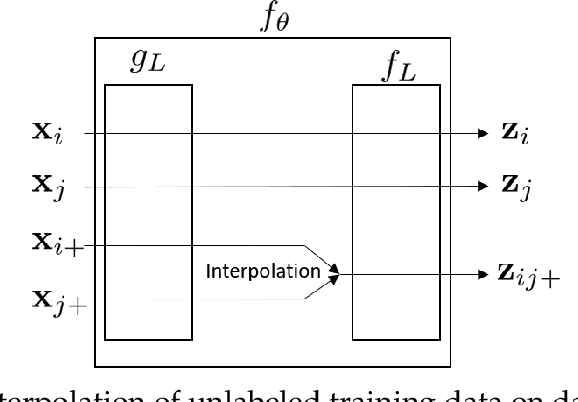
Learning a new task from a handful of examples remains an open challenge in machine learning. Despite the recent progress in few-shot learning, most methods rely on supervised pretraining or meta-learning on labeled meta-training data and cannot be applied to the case where the pretraining data is unlabeled. In this study, we present an unsupervised few-shot learning method via deep Laplacian eigenmaps. Our method learns representation from unlabeled data by grouping similar samples together and can be intuitively interpreted by random walks on augmented training data. We analytically show how deep Laplacian eigenmaps avoid collapsed representation in unsupervised learning without explicit comparison between positive and negative samples. The proposed method significantly closes the performance gap between supervised and unsupervised few-shot learning. Our method also achieves comparable performance to current state-of-the-art self-supervised learning methods under linear evaluation protocol.
Quantum-Inspired Tensor Neural Networks for Partial Differential Equations
Aug 10, 2022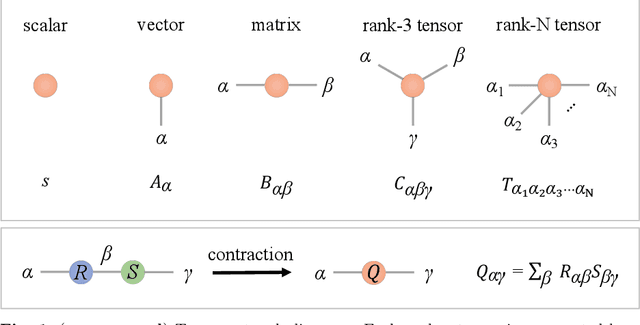
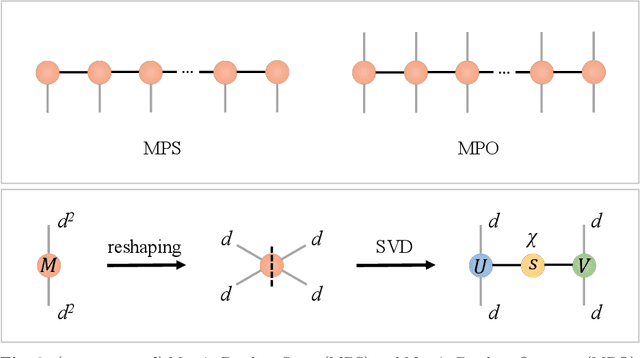
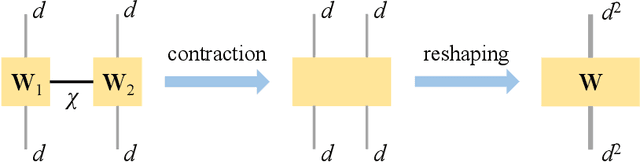

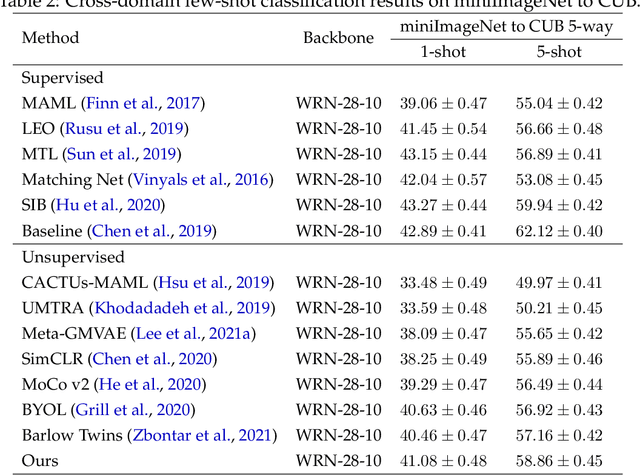
Partial Differential Equations (PDEs) are used to model a variety of dynamical systems in science and engineering. Recent advances in deep learning have enabled us to solve them in a higher dimension by addressing the curse of dimensionality in new ways. However, deep learning methods are constrained by training time and memory. To tackle these shortcomings, we implement Tensor Neural Networks (TNN), a quantum-inspired neural network architecture that leverages Tensor Network ideas to improve upon deep learning approaches. We demonstrate that TNN provide significant parameter savings while attaining the same accuracy as compared to the classical Dense Neural Network (DNN). In addition, we also show how TNN can be trained faster than DNN for the same accuracy. We benchmark TNN by applying them to solve parabolic PDEs, specifically the Black-Scholes-Barenblatt equation, widely used in financial pricing theory, empirically showing the advantages of TNN over DNN. Further examples, such as the Hamilton-Jacobi-Bellman equation, are also discussed.
Don't overfit the history -- Recursive time series data augmentation
Jul 06, 2022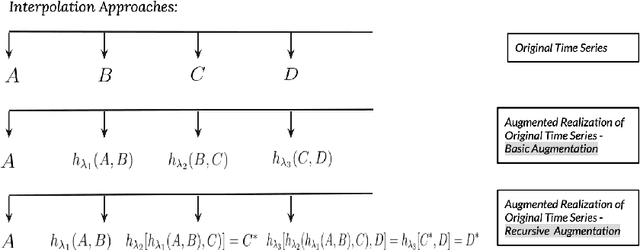
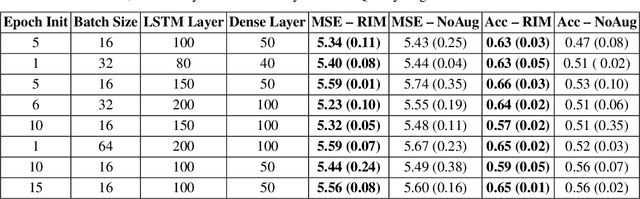
Time series observations can be seen as realizations of an underlying dynamical system governed by rules that we typically do not know. For time series learning tasks, we need to understand that we fit our model on available data, which is a unique realized history. Training on a single realization often induces severe overfitting lacking generalization. To address this issue, we introduce a general recursive framework for time series augmentation, which we call Recursive Interpolation Method, denoted as RIM. New samples are generated using a recursive interpolation function of all previous values in such a way that the enhanced samples preserve the original inherent time series dynamics. We perform theoretical analysis to characterize the proposed RIM and to guarantee its test performance. We apply RIM to diverse real world time series cases to achieve strong performance over non-augmented data on regression, classification, and reinforcement learning tasks.
Meta-free few-shot learning via representation learning with weight averaging
Apr 30, 2022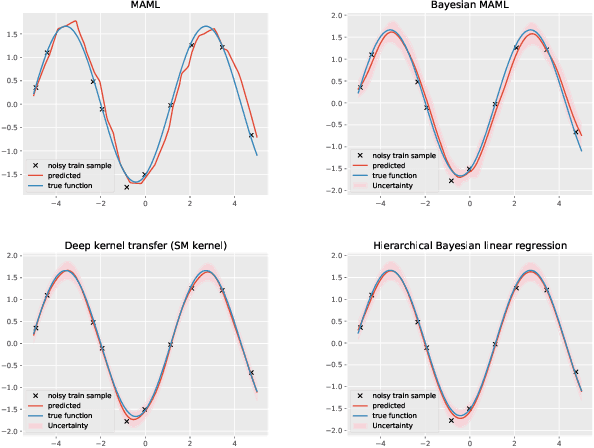
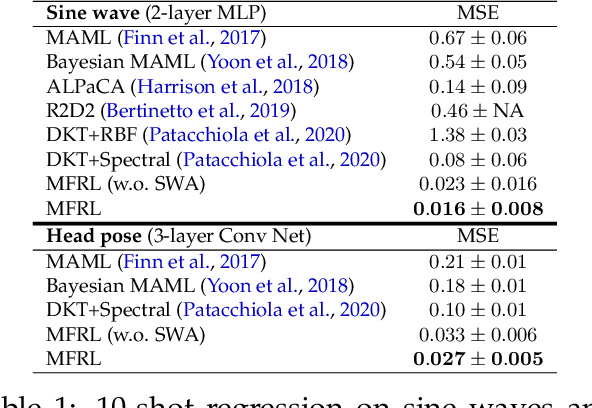
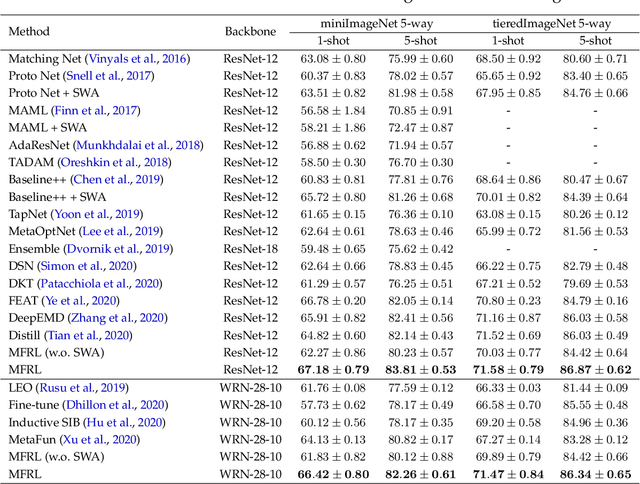

Recent studies on few-shot classification using transfer learning pose challenges to the effectiveness and efficiency of episodic meta-learning algorithms. Transfer learning approaches are a natural alternative, but they are restricted to few-shot classification. Moreover, little attention has been on the development of probabilistic models with well-calibrated uncertainty from few-shot samples, except for some Bayesian episodic learning algorithms. To tackle the aforementioned issues, we propose a new transfer learning method to obtain accurate and reliable models for few-shot regression and classification. The resulting method does not require episodic meta-learning and is called meta-free representation learning (MFRL). MFRL first finds low-rank representation generalizing well on meta-test tasks. Given the learned representation, probabilistic linear models are fine-tuned with few-shot samples to obtain models with well-calibrated uncertainty. The proposed method not only achieves the highest accuracy on a wide range of few-shot learning benchmark datasets but also correctly quantifies the prediction uncertainty. In addition, weight averaging and temperature scaling are effective in improving the accuracy and reliability of few-shot learning in existing meta-learning algorithms with a wide range of learning paradigms and model architectures.
Risk-Aware Transfer in Reinforcement Learning using Successor Features
May 28, 2021
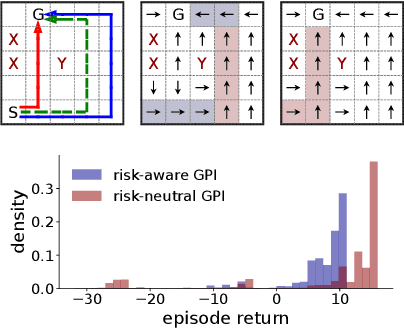

Sample efficiency and risk-awareness are central to the development of practical reinforcement learning (RL) for complex decision-making. The former can be addressed by transfer learning and the latter by optimizing some utility function of the return. However, the problem of transferring skills in a risk-aware manner is not well-understood. In this paper, we address the problem of risk-aware policy transfer between tasks in a common domain that differ only in their reward functions, in which risk is measured by the variance of reward streams. Our approach begins by extending the idea of generalized policy improvement to maximize entropic utilities, thus extending policy improvement via dynamic programming to sets of policies and levels of risk-aversion. Next, we extend the idea of successor features (SF), a value function representation that decouples the environment dynamics from the rewards, to capture the variance of returns. Our resulting risk-aware successor features (RaSF) integrate seamlessly within the RL framework, inherit the superior task generalization ability of SFs, and incorporate risk-awareness into the decision-making. Experiments on a discrete navigation domain and control of a simulated robotic arm demonstrate the ability of RaSFs to outperform alternative methods including SFs, when taking the risk of the learned policies into account.
Attentive Gaussian processes for probabilistic time-series generation
Feb 10, 2021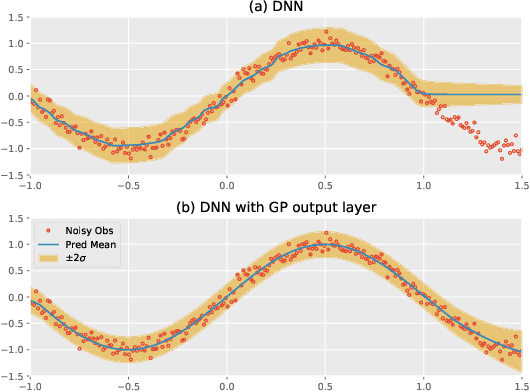
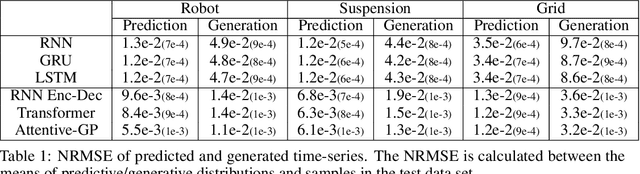
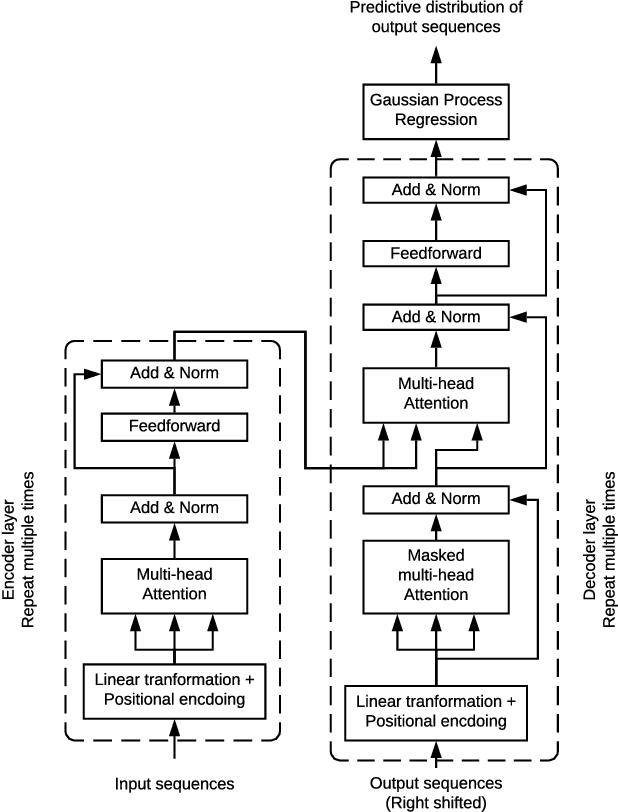
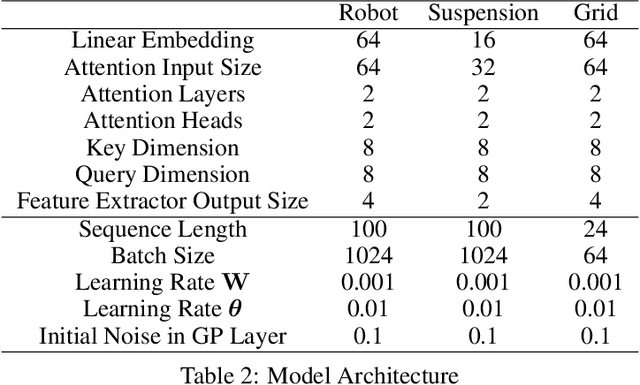
The transduction of sequence has been mostly done by recurrent networks, which are computationally demanding and often underestimate uncertainty severely. We propose a computationally efficient attention-based network combined with the Gaussian process regression to generate real-valued sequence, which we call the Attentive-GP. The proposed model not only improves the training efficiency by dispensing recurrence and convolutions but also learns the factorized generative distribution with Bayesian representation. However, the presence of the GP precludes the commonly used mini-batch approach to the training of the attention network. Therefore, we develop a block-wise training algorithm to allow mini-batch training of the network while the GP is trained using full-batch, resulting in a scalable training method. The algorithm has been proved to converge and shows comparable, if not better, quality of the found solution. As the algorithm does not assume any specific network architecture, it can be used with a wide range of hybrid models such as neural networks with kernel machine layers in the scarcity of resources for computation and memory.