 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeε-BMC: A Bayesian Ensemble Approach to Epsilon-Greedy Exploration in Model-Free Reinforcement Learning
Paper and Code

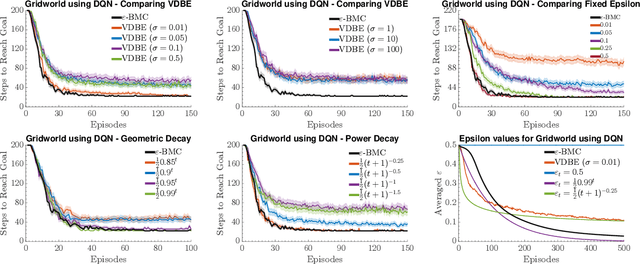

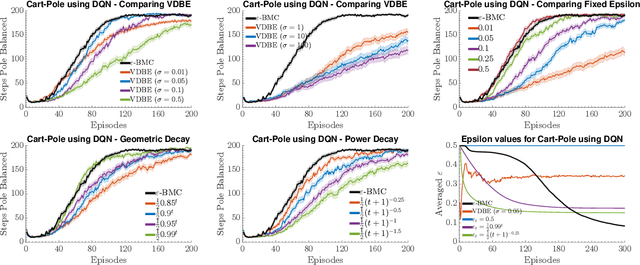
Resolving the exploration-exploitation trade-off remains a fundamental problem in the design and implementation of reinforcement learning (RL) algorithms. In this paper, we focus on model-free RL using the epsilon-greedy exploration policy, which despite its simplicity, remains one of the most frequently used forms of exploration. However, a key limitation of this policy is the specification of $\varepsilon$. In this paper, we provide a novel Bayesian perspective of $\varepsilon$ as a measure of the uniformity of the Q-value function. We introduce a closed-form Bayesian model update based on Bayesian model combination (BMC), based on this new perspective, which allows us to adapt $\varepsilon$ using experiences from the environment in constant time with monotone convergence guarantees. We demonstrate that our proposed algorithm, $\varepsilon$-\texttt{BMC}, efficiently balances exploration and exploitation on different problems, performing comparably or outperforming the best tuned fixed annealing schedules and an alternative data-dependent $\varepsilon$ adaptation scheme proposed in the literature.