 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive Gaussian processes for probabilistic time-series generation
Paper and Code
Feb 10, 2021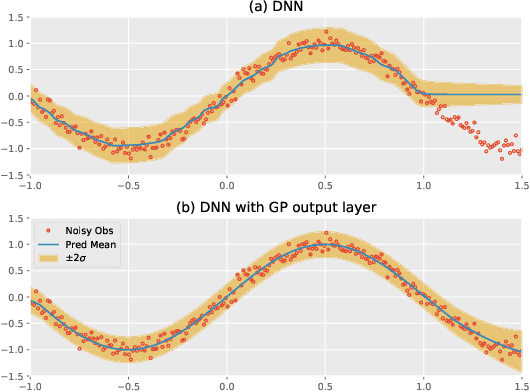
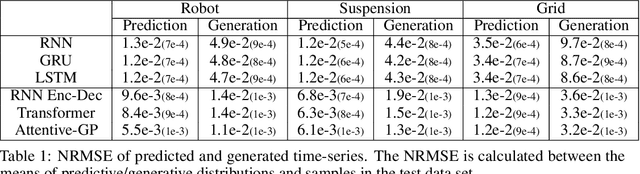
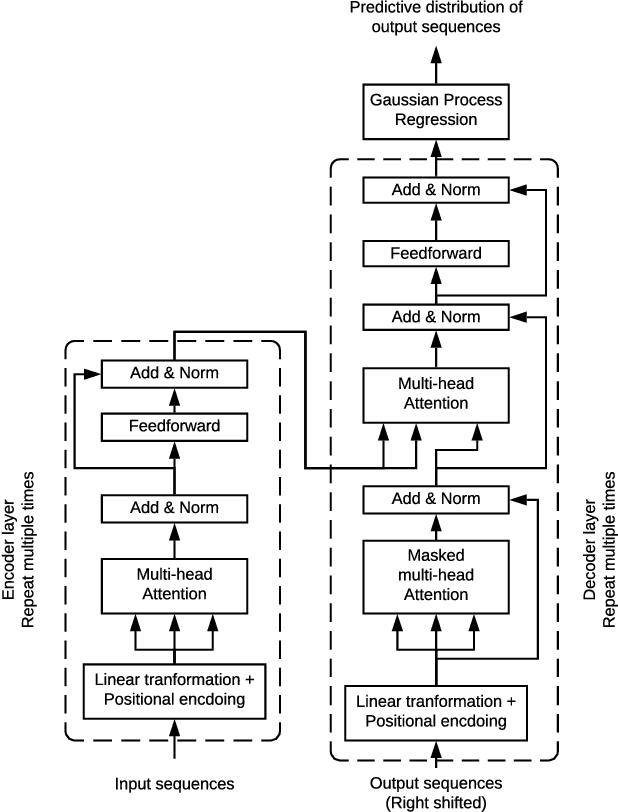
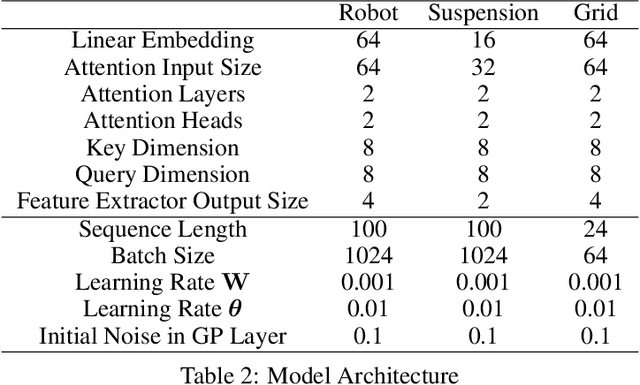
The transduction of sequence has been mostly done by recurrent networks, which are computationally demanding and often underestimate uncertainty severely. We propose a computationally efficient attention-based network combined with the Gaussian process regression to generate real-valued sequence, which we call the Attentive-GP. The proposed model not only improves the training efficiency by dispensing recurrence and convolutions but also learns the factorized generative distribution with Bayesian representation. However, the presence of the GP precludes the commonly used mini-batch approach to the training of the attention network. Therefore, we develop a block-wise training algorithm to allow mini-batch training of the network while the GP is trained using full-batch, resulting in a scalable training method. The algorithm has been proved to converge and shows comparable, if not better, quality of the found solution. As the algorithm does not assume any specific network architecture, it can be used with a wide range of hybrid models such as neural networks with kernel machine layers in the scarcity of resources for computation and memory.