 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Few-shot Learning via Deep Laplacian Eigenmaps
Oct 07, 2022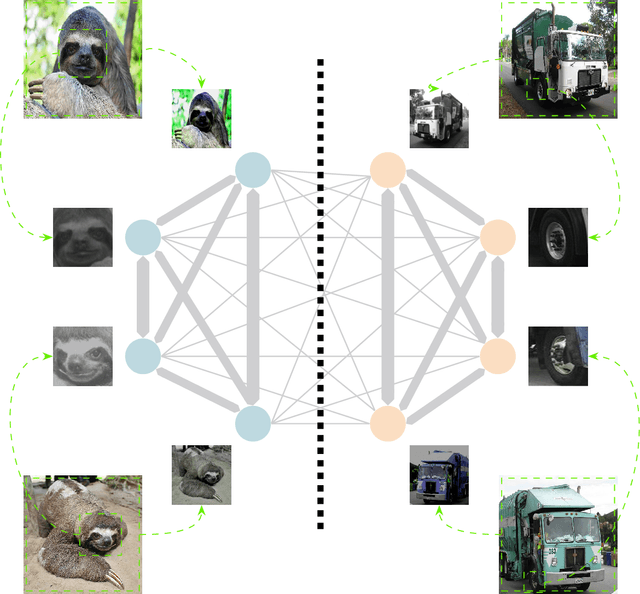
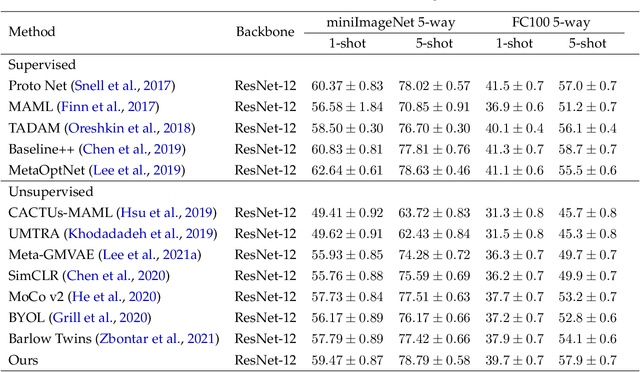
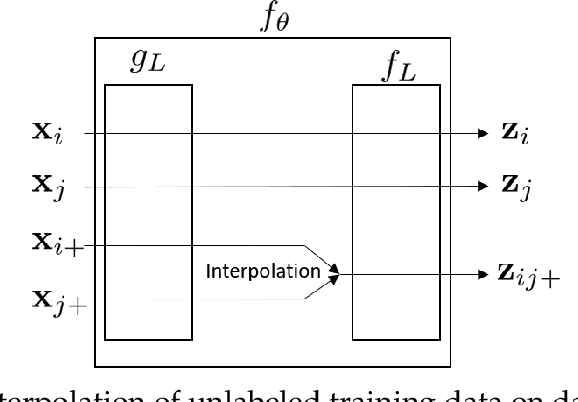
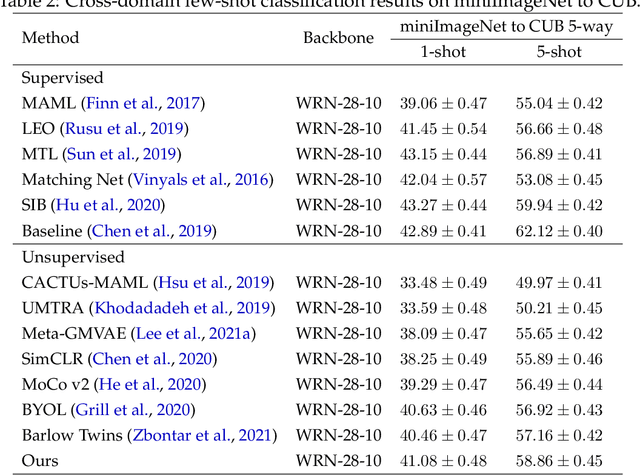
Learning a new task from a handful of examples remains an open challenge in machine learning. Despite the recent progress in few-shot learning, most methods rely on supervised pretraining or meta-learning on labeled meta-training data and cannot be applied to the case where the pretraining data is unlabeled. In this study, we present an unsupervised few-shot learning method via deep Laplacian eigenmaps. Our method learns representation from unlabeled data by grouping similar samples together and can be intuitively interpreted by random walks on augmented training data. We analytically show how deep Laplacian eigenmaps avoid collapsed representation in unsupervised learning without explicit comparison between positive and negative samples. The proposed method significantly closes the performance gap between supervised and unsupervised few-shot learning. Our method also achieves comparable performance to current state-of-the-art self-supervised learning methods under linear evaluation protocol.
Meta-free few-shot learning via representation learning with weight averaging
Apr 30, 2022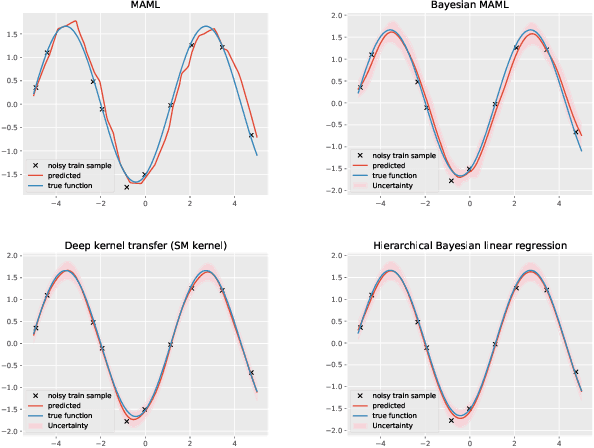
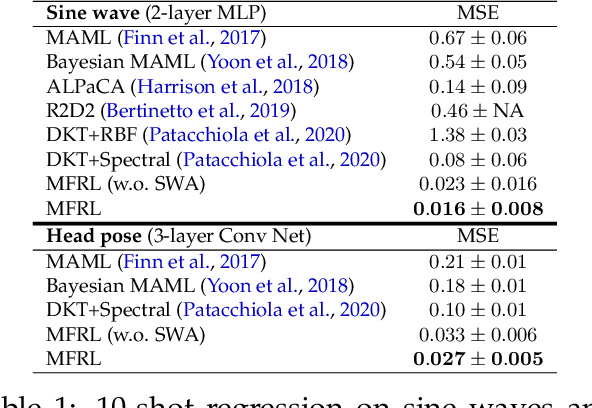
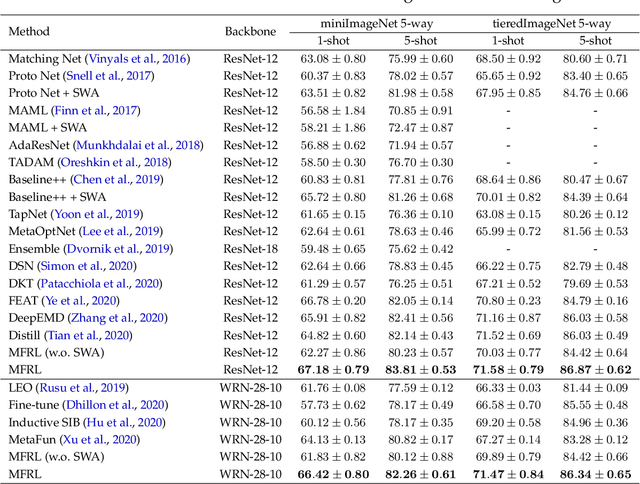

Recent studies on few-shot classification using transfer learning pose challenges to the effectiveness and efficiency of episodic meta-learning algorithms. Transfer learning approaches are a natural alternative, but they are restricted to few-shot classification. Moreover, little attention has been on the development of probabilistic models with well-calibrated uncertainty from few-shot samples, except for some Bayesian episodic learning algorithms. To tackle the aforementioned issues, we propose a new transfer learning method to obtain accurate and reliable models for few-shot regression and classification. The resulting method does not require episodic meta-learning and is called meta-free representation learning (MFRL). MFRL first finds low-rank representation generalizing well on meta-test tasks. Given the learned representation, probabilistic linear models are fine-tuned with few-shot samples to obtain models with well-calibrated uncertainty. The proposed method not only achieves the highest accuracy on a wide range of few-shot learning benchmark datasets but also correctly quantifies the prediction uncertainty. In addition, weight averaging and temperature scaling are effective in improving the accuracy and reliability of few-shot learning in existing meta-learning algorithms with a wide range of learning paradigms and model architectures.
Attentive Gaussian processes for probabilistic time-series generation
Feb 10, 2021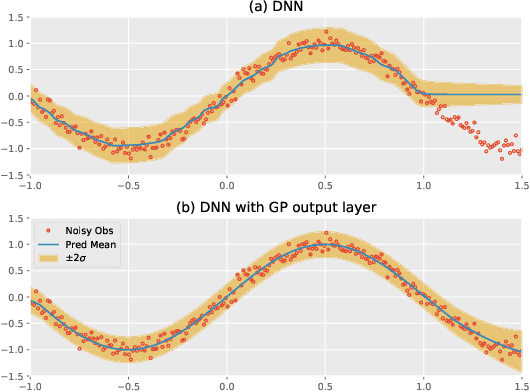
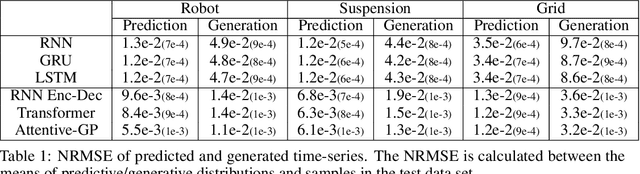
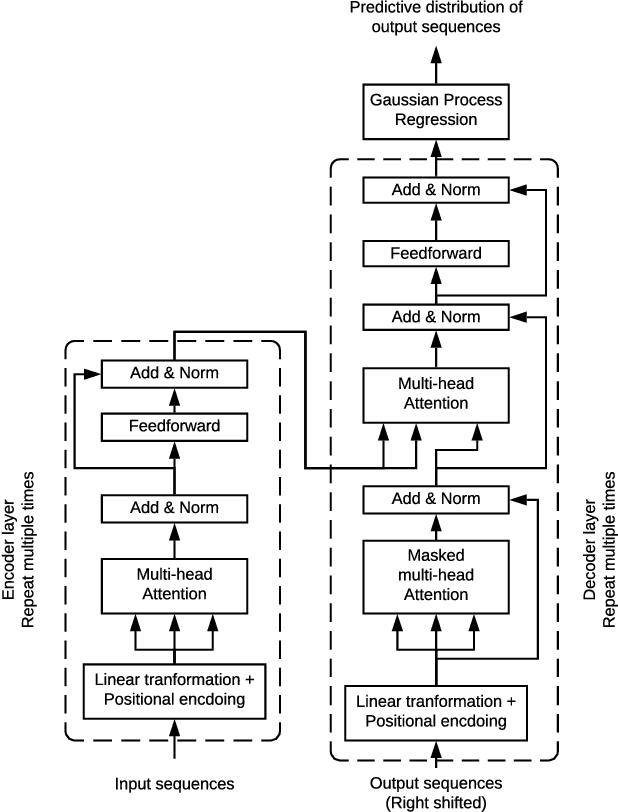
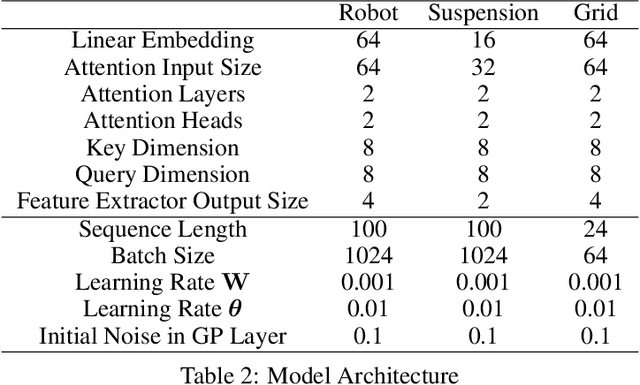
The transduction of sequence has been mostly done by recurrent networks, which are computationally demanding and often underestimate uncertainty severely. We propose a computationally efficient attention-based network combined with the Gaussian process regression to generate real-valued sequence, which we call the Attentive-GP. The proposed model not only improves the training efficiency by dispensing recurrence and convolutions but also learns the factorized generative distribution with Bayesian representation. However, the presence of the GP precludes the commonly used mini-batch approach to the training of the attention network. Therefore, we develop a block-wise training algorithm to allow mini-batch training of the network while the GP is trained using full-batch, resulting in a scalable training method. The algorithm has been proved to converge and shows comparable, if not better, quality of the found solution. As the algorithm does not assume any specific network architecture, it can be used with a wide range of hybrid models such as neural networks with kernel machine layers in the scarcity of resources for computation and memory.