 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Ligands Docking to Protein Pockets
Jan 25, 2025



Molecular docking is a key task in computational biology that has attracted increasing interest from the machine learning community. While existing methods have achieved success, they generally treat each protein-ligand pair in isolation. Inspired by the biochemical observation that ligands binding to the same target protein tend to adopt similar poses, we propose \textsc{GroupBind}, a novel molecular docking framework that simultaneously considers multiple ligands docking to a protein. This is achieved by introducing an interaction layer for the group of ligands and a triangle attention module for embedding protein-ligand and group-ligand pairs. By integrating our approach with diffusion-based docking model, we set a new S performance on the PDBBind blind docking benchmark, demonstrating the effectiveness of our proposed molecular docking paradigm.
FAFE: Immune Complex Modeling with Geodesic Distance Loss on Noisy Group Frames
Jul 01, 2024



Despite the striking success of general protein folding models such as AlphaFold2(AF2, Jumper et al. (2021)), the accurate computational modeling of antibody-antigen complexes remains a challenging task. In this paper, we first analyze AF2's primary loss function, known as the Frame Aligned Point Error (FAPE), and raise a previously overlooked issue that FAPE tends to face gradient vanishing problem on high-rotational-error targets. To address this fundamental limitation, we propose a novel geodesic loss called Frame Aligned Frame Error (FAFE, denoted as F2E to distinguish from FAPE), which enables the model to better optimize both the rotational and translational errors between two frames. We then prove that F2E can be reformulated as a group-aware geodesic loss, which translates the optimization of the residue-to-residue error to optimizing group-to-group geodesic frame distance. By fine-tuning AF2 with our proposed new loss function, we attain a correct rate of 52.3\% (DockQ $>$ 0.23) on an evaluation set and 43.8\% correct rate on a subset with low homology, with substantial improvement over AF2 by 182\% and 100\% respectively.
Interpretable Geometric Deep Learning via Learnable Randomness Injection
Oct 30, 2022Point cloud data is ubiquitous in scientific fields. Recently, geometric deep learning (GDL) has been widely applied to solve prediction tasks with such data. However, GDL models are often complicated and hardly interpretable, which poses concerns to scientists when deploying these models in scientific analysis and experiments. This work proposes a general mechanism named learnable randomness injection (LRI), which allows building inherently interpretable models based on general GDL backbones. LRI-induced models, once being trained, can detect the points in the point cloud data that carry information indicative of the prediction label. We also propose four datasets from real scientific applications that cover the domains of high-energy physics and biochemistry to evaluate the LRI mechanism. Compared with previous post-hoc interpretation methods, the points detected by LRI align much better and stabler with the ground-truth patterns that have actual scientific meanings. LRI is grounded by the information bottleneck principle. LRI-induced models also show more robustness to the distribution shifts between training and test scenarios. Our code and datasets are available at \url{https://github.com/Graph-COM/LRI}.
Pre-training of Graph Neural Network for Modeling Effects of Mutations on Protein-Protein Binding Affinity
Aug 28, 2020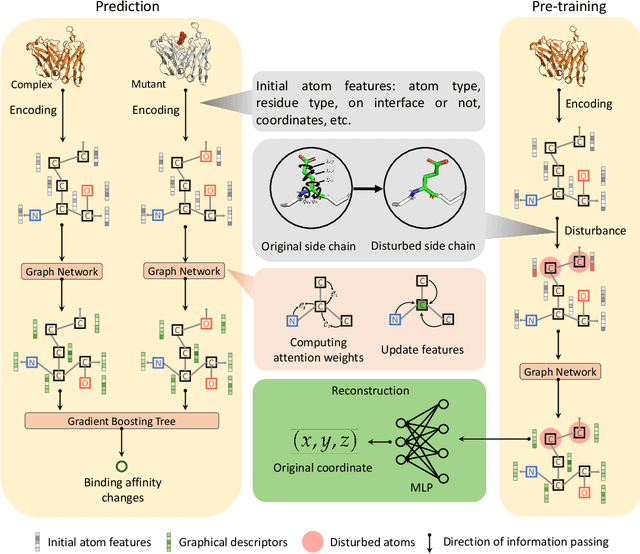
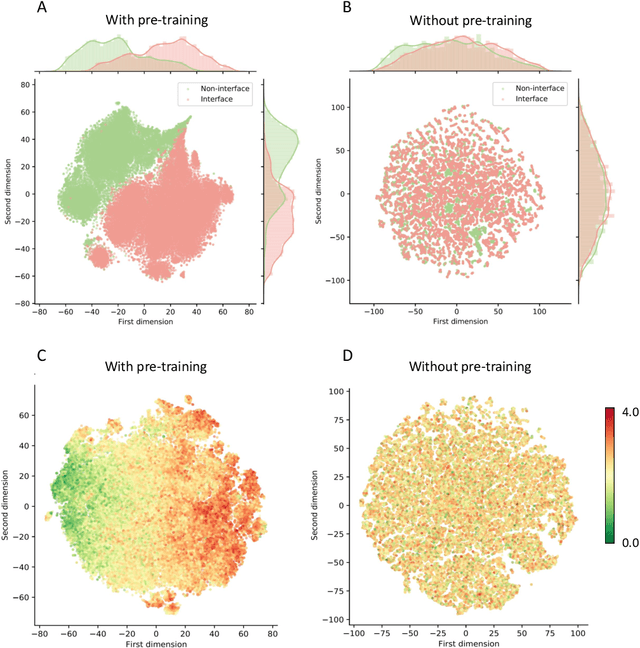
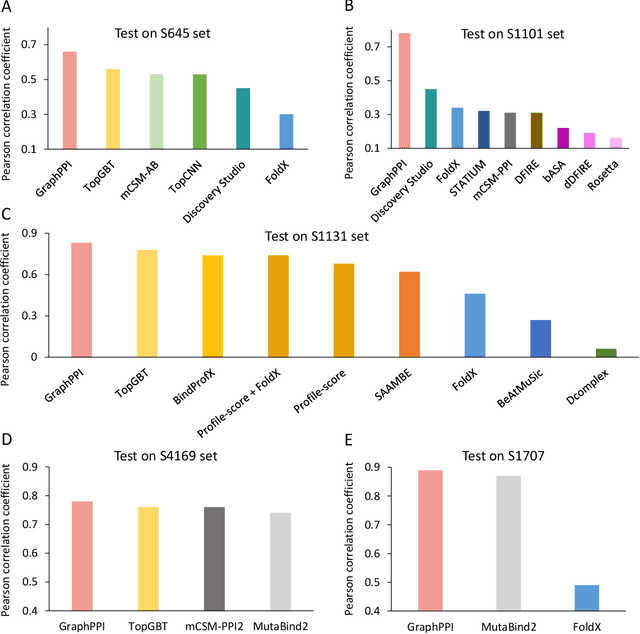
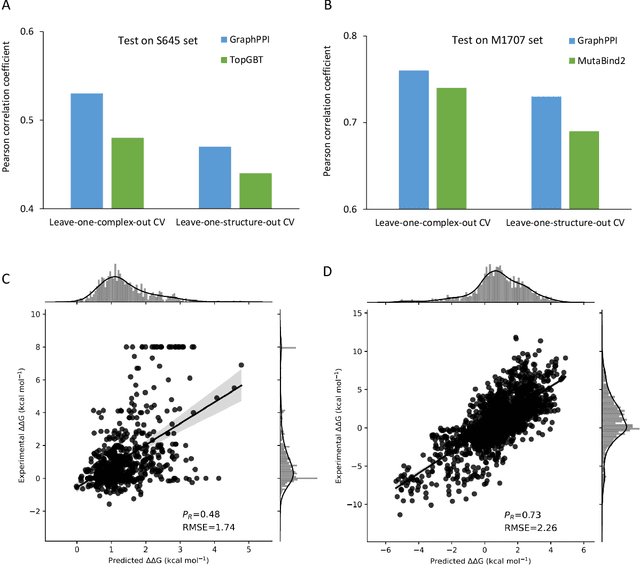
Modeling the effects of mutations on the binding affinity plays a crucial role in protein engineering and drug design. In this study, we develop a novel deep learning based framework, named GraphPPI, to predict the binding affinity changes upon mutations based on the features provided by a graph neural network (GNN). In particular, GraphPPI first employs a well-designed pre-training scheme to enforce the GNN to capture the features that are predictive of the effects of mutations on binding affinity in an unsupervised manner and then integrates these graphical features with gradient-boosting trees to perform the prediction. Experiments showed that, without any annotated signals, GraphPPI can capture meaningful patterns of the protein structures. Also, GraphPPI achieved new state-of-the-art performance in predicting the binding affinity changes upon both single- and multi-point mutations on five benchmark datasets. In-depth analyses also showed GraphPPI can accurately estimate the effects of mutations on the binding affinity between SARS-CoV-2 and its neutralizing antibodies. These results have established GraphPPI as a powerful and useful computational tool in the studies of protein design.
DeepMask: an algorithm for cloud and cloud shadow detection in optical satellite remote sensing images using deep residual network
Nov 09, 2019
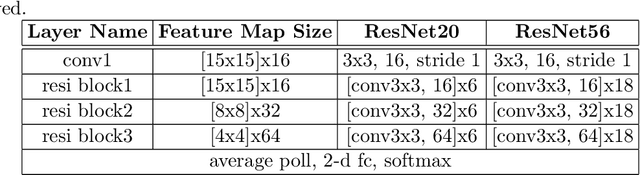
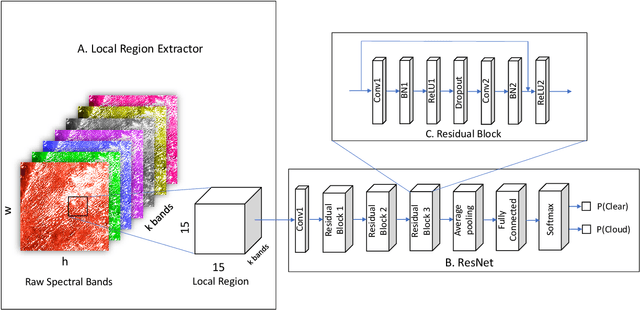
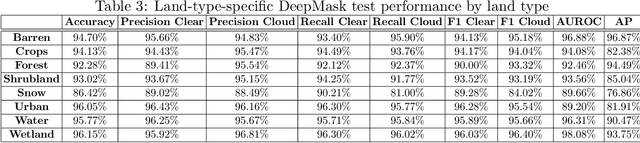
Detecting and masking cloud and cloud shadow from satellite remote sensing images is a pervasive problem in the remote sensing community. Accurate and efficient detection of cloud and cloud shadow is an essential step to harness the value of remotely sensed data for almost all downstream analysis. DeepMask, a new algorithm for cloud and cloud shadow detection in optical satellite remote sensing imagery, is proposed in this study. DeepMask utilizes ResNet, a deep convolutional neural network, for pixel-level cloud mask generation. The algorithm is trained and evaluated on the Landsat 8 Cloud Cover Assessment Validation Dataset distributed across 8 different land types. Compared with CFMask, the most widely used cloud detection algorithm, land-type-specific DeepMask models achieve higher accuracy across all land types. The average accuracy is 93.56%, compared with 85.36% from CFMask. DeepMask also achieves 91.02% accuracy on all-land-type dataset. Compared with other CNN-based cloud mask algorithms, DeepMask benefits from the parsimonious architecture and the residual connection of ResNet. It is compatible with input of any size and shape. DeepMask still maintains high performance when using only red, green, blue, and NIR bands, indicating its potential to be applied to other satellite platforms that only have limited optical bands.
Sequence Modeling of Temporal Credit Assignment for Episodic Reinforcement Learning
May 31, 2019

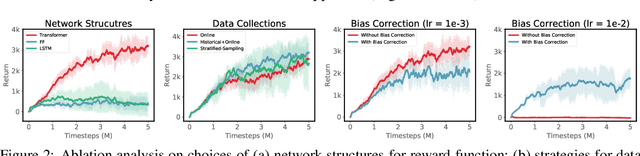
Recent advances in deep reinforcement learning algorithms have shown great potential and success for solving many challenging real-world problems, including Go game and robotic applications. Usually, these algorithms need a carefully designed reward function to guide training in each time step. However, in real world, it is non-trivial to design such a reward function, and the only signal available is usually obtained at the end of a trajectory, also known as the episodic reward or return. In this work, we introduce a new algorithm for temporal credit assignment, which learns to decompose the episodic return back to each time-step in the trajectory using deep neural networks. With this learned reward signal, the learning efficiency can be substantially improved for episodic reinforcement learning. In particular, we find that expressive language models such as the Transformer can be adopted for learning the importance and the dependency of states in the trajectory, therefore providing high-quality and interpretable learned reward signals. We have performed extensive experiments on a set of MuJoCo continuous locomotive control tasks with only episodic returns and demonstrated the effectiveness of our algorithm.