 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCropCraft: Inverse Procedural Modeling for 3D Reconstruction of Crop Plants
Nov 14, 2024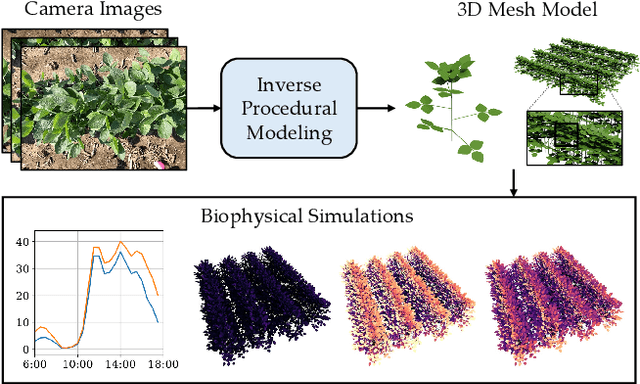
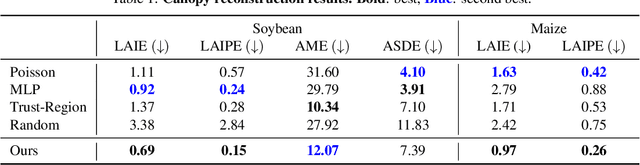
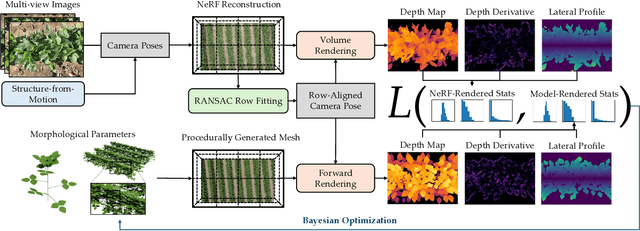
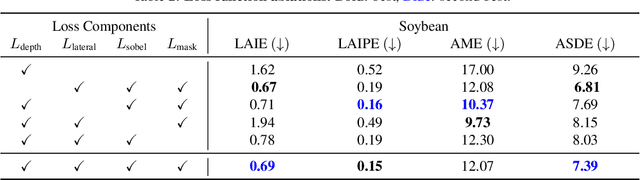
The ability to automatically build 3D digital twins of plants from images has countless applications in agriculture, environmental science, robotics, and other fields. However, current 3D reconstruction methods fail to recover complete shapes of plants due to heavy occlusion and complex geometries. In this work, we present a novel method for 3D reconstruction of agricultural crops based on optimizing a parametric model of plant morphology via inverse procedural modeling. Our method first estimates depth maps by fitting a neural radiance field and then employs Bayesian optimization to estimate plant morphological parameters that result in consistent depth renderings. The resulting 3D model is complete and biologically plausible. We validate our method on a dataset of real images of agricultural fields, and demonstrate that the reconstructions can be used for a variety of monitoring and simulation applications.
Physical Property Understanding from Language-Embedded Feature Fields
Apr 05, 2024Can computers perceive the physical properties of objects solely through vision? Research in cognitive science and vision science has shown that humans excel at identifying materials and estimating their physical properties based purely on visual appearance. In this paper, we present a novel approach for dense prediction of the physical properties of objects using a collection of images. Inspired by how humans reason about physics through vision, we leverage large language models to propose candidate materials for each object. We then construct a language-embedded point cloud and estimate the physical properties of each 3D point using a zero-shot kernel regression approach. Our method is accurate, annotation-free, and applicable to any object in the open world. Experiments demonstrate the effectiveness of the proposed approach in various physical property reasoning tasks, such as estimating the mass of common objects, as well as other properties like friction and hardness.
Structure from Duplicates: Neural Inverse Graphics from a Pile of Objects
Jan 10, 2024Our world is full of identical objects (\emphe.g., cans of coke, cars of same model). These duplicates, when seen together, provide additional and strong cues for us to effectively reason about 3D. Inspired by this observation, we introduce Structure from Duplicates (SfD), a novel inverse graphics framework that reconstructs geometry, material, and illumination from a single image containing multiple identical objects. SfD begins by identifying multiple instances of an object within an image, and then jointly estimates the 6DoF pose for all instances.An inverse graphics pipeline is subsequently employed to jointly reason about the shape, material of the object, and the environment light, while adhering to the shared geometry and material constraint across instances. Our primary contributions involve utilizing object duplicates as a robust prior for single-image inverse graphics and proposing an in-plane rotation-robust Structure from Motion (SfM) formulation for joint 6-DoF object pose estimation. By leveraging multi-view cues from a single image, SfD generates more realistic and detailed 3D reconstructions, significantly outperforming existing single image reconstruction models and multi-view reconstruction approaches with a similar or greater number of observations.
Networked Time Series Imputation via Position-aware Graph Enhanced Variational Autoencoders
May 29, 2023Multivariate time series (MTS) imputation is a widely studied problem in recent years. Existing methods can be divided into two main groups, including (1) deep recurrent or generative models that primarily focus on time series features, and (2) graph neural networks (GNNs) based models that utilize the topological information from the inherent graph structure of MTS as relational inductive bias for imputation. Nevertheless, these methods either neglect topological information or assume the graph structure is fixed and accurately known. Thus, they fail to fully utilize the graph dynamics for precise imputation in more challenging MTS data such as networked time series (NTS), where the underlying graph is constantly changing and might have missing edges. In this paper, we propose a novel approach to overcome these limitations. First, we define the problem of imputation over NTS which contains missing values in both node time series features and graph structures. Then, we design a new model named PoGeVon which leverages variational autoencoder (VAE) to predict missing values over both node time series features and graph structures. In particular, we propose a new node position embedding based on random walk with restart (RWR) in the encoder with provable higher expressive power compared with message-passing based graph neural networks (GNNs). We further design a decoder with 3-stage predictions from the perspective of multi-task learning to impute missing values in both time series and graph structures reciprocally. Experiment results demonstrate the effectiveness of our model over baselines.
Retrieval Based Time Series Forecasting
Sep 27, 2022
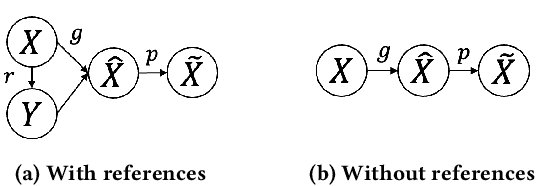
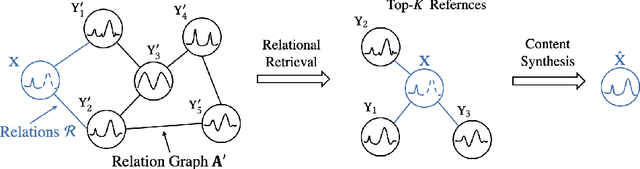
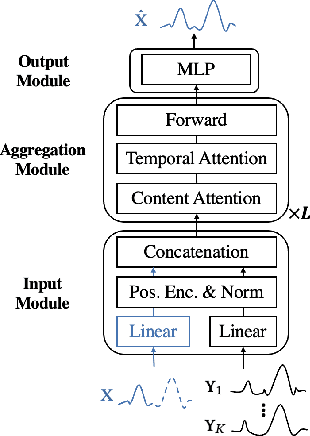
Time series data appears in a variety of applications such as smart transportation and environmental monitoring. One of the fundamental problems for time series analysis is time series forecasting. Despite the success of recent deep time series forecasting methods, they require sufficient observation of historical values to make accurate forecasting. In other words, the ratio of the output length (or forecasting horizon) to the sum of the input and output lengths should be low enough (e.g., 0.3). As the ratio increases (e.g., to 0.8), the uncertainty for the forecasting accuracy increases significantly. In this paper, we show both theoretically and empirically that the uncertainty could be effectively reduced by retrieving relevant time series as references. In the theoretical analysis, we first quantify the uncertainty and show its connections to the Mean Squared Error (MSE). Then we prove that models with references are easier to learn than models without references since the retrieved references could reduce the uncertainty. To empirically demonstrate the effectiveness of the retrieval based time series forecasting models, we introduce a simple yet effective two-stage method, called ReTime consisting of a relational retrieval and a content synthesis. We also show that ReTime can be easily adapted to the spatial-temporal time series and time series imputation settings. Finally, we evaluate ReTime on real-world datasets to demonstrate its effectiveness.
Adaptive Transfer Learning for Plant Phenotyping
Jan 14, 2022Plant phenotyping (Guo et al. 2021; Pieruschka et al. 2019) focuses on studying the diverse traits of plants related to the plants' growth. To be more specific, by accurately measuring the plant's anatomical, ontogenetical, physiological and biochemical properties, it allows identifying the crucial factors of plants' growth in different environments. One commonly used approach is to predict the plant's traits using hyperspectral reflectance (Yendrek et al. 2017; Wang et al. 2021). However, the data distributions of the hyperspectral reflectance data in plant phenotyping might vary in different environments for different plants. That is, it would be computationally expansive to learn the machine learning models separately for one plant in different environments. To solve this problem, we focus on studying the knowledge transferability of modern machine learning models in plant phenotyping. More specifically, this work aims to answer the following questions. (1) How is the performance of conventional machine learning models, e.g., partial least squares regression (PLSR), Gaussian process regression (GPR) and multi-layer perceptron (MLP), affected by the number of annotated samples for plant phenotyping? (2) Whether could the neural network based transfer learning models improve the performance of plant phenotyping? (3) Could the neural network based transfer learning be improved by using infinite-width hidden layers for plant phenotyping?
DeepMask: an algorithm for cloud and cloud shadow detection in optical satellite remote sensing images using deep residual network
Nov 09, 2019
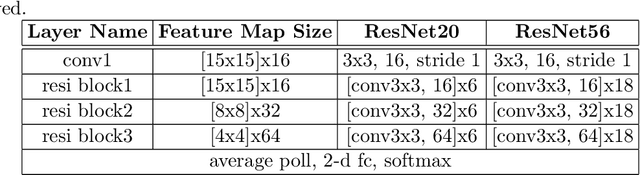
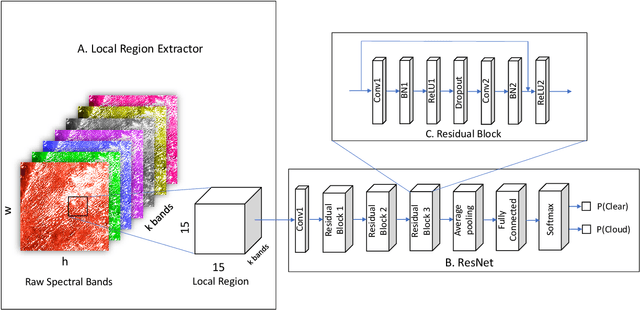
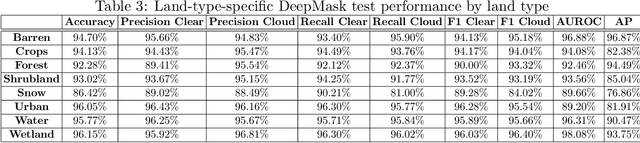
Detecting and masking cloud and cloud shadow from satellite remote sensing images is a pervasive problem in the remote sensing community. Accurate and efficient detection of cloud and cloud shadow is an essential step to harness the value of remotely sensed data for almost all downstream analysis. DeepMask, a new algorithm for cloud and cloud shadow detection in optical satellite remote sensing imagery, is proposed in this study. DeepMask utilizes ResNet, a deep convolutional neural network, for pixel-level cloud mask generation. The algorithm is trained and evaluated on the Landsat 8 Cloud Cover Assessment Validation Dataset distributed across 8 different land types. Compared with CFMask, the most widely used cloud detection algorithm, land-type-specific DeepMask models achieve higher accuracy across all land types. The average accuracy is 93.56%, compared with 85.36% from CFMask. DeepMask also achieves 91.02% accuracy on all-land-type dataset. Compared with other CNN-based cloud mask algorithms, DeepMask benefits from the parsimonious architecture and the residual connection of ResNet. It is compatible with input of any size and shape. DeepMask still maintains high performance when using only red, green, blue, and NIR bands, indicating its potential to be applied to other satellite platforms that only have limited optical bands.