 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeO-PRESS: Boosting OCT axial resolution with Prior guidance, Recurrence, and Equivariant Self-Supervision
Jan 06, 2024



Optical coherence tomography (OCT) is a noninvasive technology that enables real-time imaging of tissue microanatomies. The axial resolution of OCT is intrinsically constrained by the spectral bandwidth of the employed light source while maintaining a fixed center wavelength for a specific application. Physically extending this bandwidth faces strong limitations and requires a substantial cost. We present a novel computational approach, called as O-PRESS, for boosting the axial resolution of OCT with Prior Guidance, a Recurrent mechanism, and Equivariant Self-Supervision. Diverging from conventional superresolution methods that rely on physical models or data-driven techniques, our method seamlessly integrates OCT modeling and deep learning, enabling us to achieve real-time axial-resolution enhancement exclusively from measurements without a need for paired images. Our approach solves two primary tasks of resolution enhancement and noise reduction with one treatment. Both tasks are executed in a self-supervised manner, with equivariance imaging and free space priors guiding their respective processes. Experimental evaluations, encompassing both quantitative metrics and visual assessments, consistently verify the efficacy and superiority of our approach, which exhibits performance on par with fully supervised methods. Importantly, the robustness of our model is affirmed, showcasing its dual capability to enhance axial resolution while concurrently improving the signal-to-noise ratio.
Rethinking Memory and Communication Cost for Efficient Large Language Model Training
Oct 09, 2023
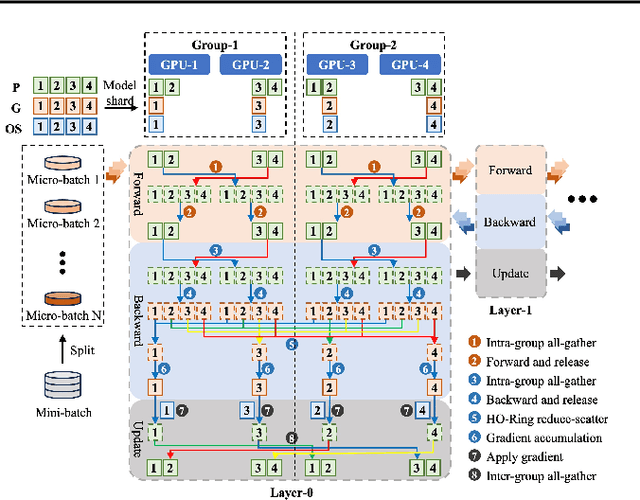
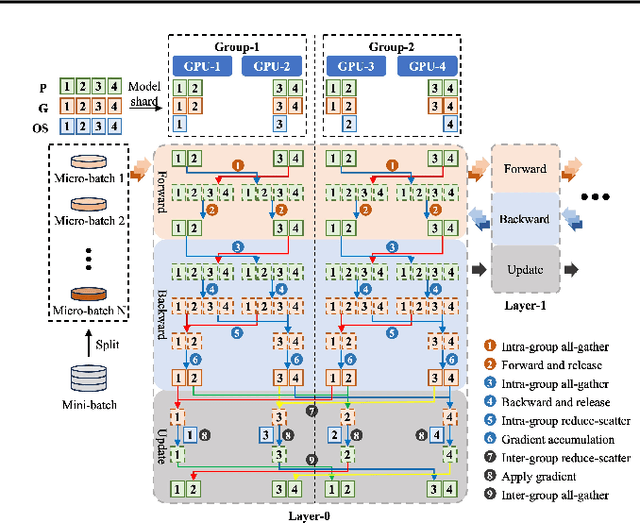
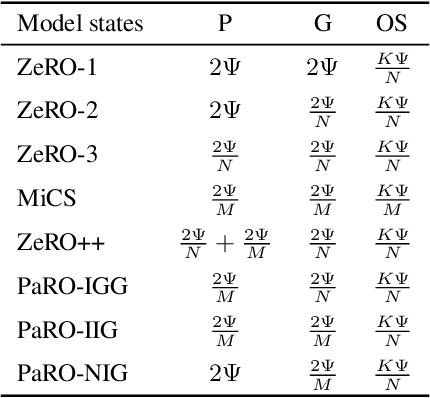
As model sizes and training datasets continue to increase, large-scale model training frameworks reduce memory consumption by various sharding techniques. However, the huge communication overhead reduces the training efficiency, especially in public cloud environments with varying network bandwidths. In this paper, we rethink the impact of memory consumption and communication overhead on the training speed of large language model, and propose a memory-communication balanced \underline{Pa}rtial \underline{R}edundancy \underline{O}ptimizer (PaRO). PaRO reduces the amount and frequency of inter-group communication by grouping GPU clusters and introducing minor intra-group memory redundancy, thereby improving the training efficiency of the model. Additionally, we propose a Hierarchical Overlapping Ring (HO-Ring) communication topology to enhance communication efficiency between nodes or across switches in large model training. Our experiments demonstrate that the HO-Ring algorithm improves communication efficiency by 32.6\% compared to the traditional Ring algorithm. Compared to the baseline ZeRO, PaRO significantly improves training throughput by 1.2x-2.6x and achieves a near-linear scalability. Therefore, the PaRO strategy provides more fine-grained options for the trade-off between memory consumption and communication overhead in different training scenarios.