 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRef-Adv: Exploring MLLM Visual Reasoning in Referring Expression Tasks
Feb 27, 2026Referring Expression Comprehension (REC) links language to region level visual perception. Standard benchmarks (RefCOCO, RefCOCO+, RefCOCOg) have progressed rapidly with multimodal LLMs but remain weak tests of visual reasoning and grounding: (i) many expressions are very short, leaving little reasoning demand; (ii) images often contain few distractors, making the target easy to find; and (iii) redundant descriptors enable shortcut solutions that bypass genuine text understanding and visual reasoning. We introduce Ref-Adv, a modern REC benchmark that suppresses shortcuts by pairing linguistically nontrivial expressions with only the information necessary to uniquely identify the target. The dataset contains referring expressions on real images, curated with hard distractors and annotated with reasoning facets including negation. We conduct comprehensive ablations (word order perturbations and descriptor deletion sufficiency) to show that solving Ref-Adv requires reasoning beyond simple cues, and we evaluate a broad suite of contemporary multimodal LLMs on Ref-Adv. Despite strong results on RefCOCO, RefCOCO+, and RefCOCOg, models drop markedly on Ref-Adv, revealing reliance on shortcuts and gaps in visual reasoning and grounding. We provide an in depth failure analysis and aim for Ref-Adv to guide future work on visual reasoning and grounding in MLLMs.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
Similarity is Not All You Need: Endowing Retrieval Augmented Generation with Multi Layered Thoughts
May 30, 2024



In recent years, large language models (LLMs) have made remarkable achievements in various domains. However, the untimeliness and cost of knowledge updates coupled with hallucination issues of LLMs have curtailed their applications in knowledge intensive tasks, where retrieval augmented generation (RAG) can be of help. Nevertheless, existing retrieval augmented models typically use similarity as a bridge between queries and documents and follow a retrieve then read procedure. In this work, we argue that similarity is not always the panacea and totally relying on similarity would sometimes degrade the performance of retrieval augmented generation. To this end, we propose MetRag, a Multi layEred Thoughts enhanced Retrieval Augmented Generation framework. To begin with, beyond existing similarity oriented thought, we embrace a small scale utility model that draws supervision from an LLM for utility oriented thought and further come up with a smarter model by comprehensively combining the similarity and utility oriented thoughts. Furthermore, given the fact that the retrieved document set tends to be huge and using them in isolation makes it difficult to capture the commonalities and characteristics among them, we propose to make an LLM as a task adaptive summarizer to endow retrieval augmented generation with compactness-oriented thought. Finally, with multi layered thoughts from the precedent stages, an LLM is called for knowledge augmented generation. Extensive experiments on knowledge-intensive tasks have demonstrated the superiority of MetRag.
AntDT: A Self-Adaptive Distributed Training Framework for Leader and Straggler Nodes
Apr 15, 2024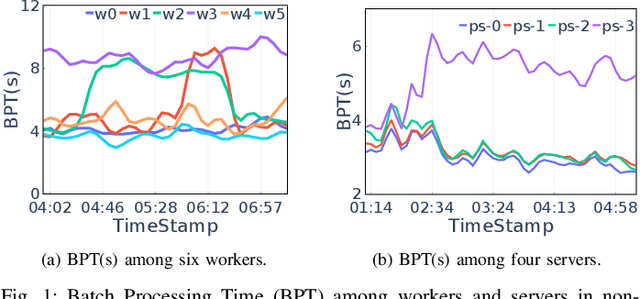
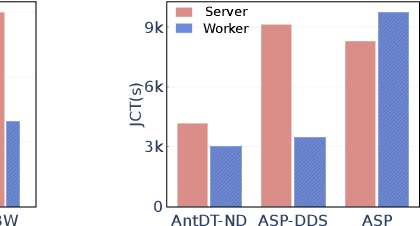
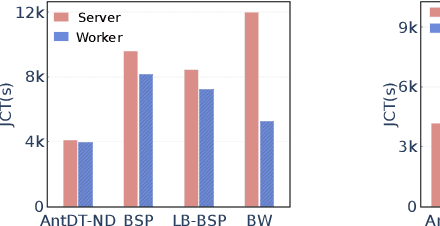
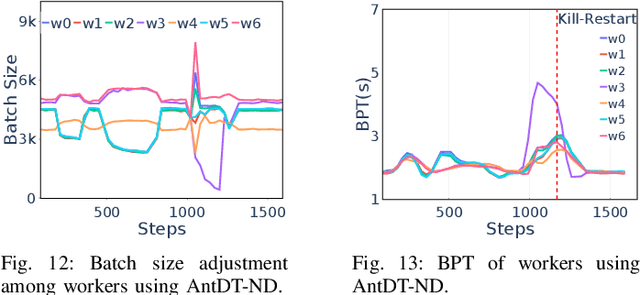
Many distributed training techniques like Parameter Server and AllReduce have been proposed to take advantage of the increasingly large data and rich features. However, stragglers frequently occur in distributed training due to resource contention and hardware heterogeneity, which significantly hampers the training efficiency. Previous works only address part of the stragglers and could not adaptively solve various stragglers in practice. Additionally, it is challenging to use a systematic framework to address all stragglers because different stragglers require diverse data allocation and fault-tolerance mechanisms. Therefore, this paper proposes a unified distributed training framework called AntDT (Ant Distributed Training Framework) to adaptively solve the straggler problems. Firstly, the framework consists of four components, including the Stateful Dynamic Data Sharding service, Monitor, Controller, and Agent. These components work collaboratively to efficiently distribute workloads and provide a range of pre-defined straggler mitigation methods with fault tolerance, thereby hiding messy details of data allocation and fault handling. Secondly, the framework provides a high degree of flexibility, allowing for the customization of straggler mitigation solutions based on the specific circumstances of the cluster. Leveraging this flexibility, we introduce two straggler mitigation solutions, namely AntDT-ND for non-dedicated clusters and AntDT-DD for dedicated clusters, as practical examples to resolve various types of stragglers at Ant Group. Justified by our comprehensive experiments and industrial deployment statistics, AntDT outperforms other SOTA methods more than 3x in terms of training efficiency. Additionally, in Alipay's homepage recommendation scenario, using AntDT reduces the training duration of the ranking model from 27.8 hours to just 5.4 hours.
AntBatchInfer: Elastic Batch Inference in the Kubernetes Cluster
Apr 15, 2024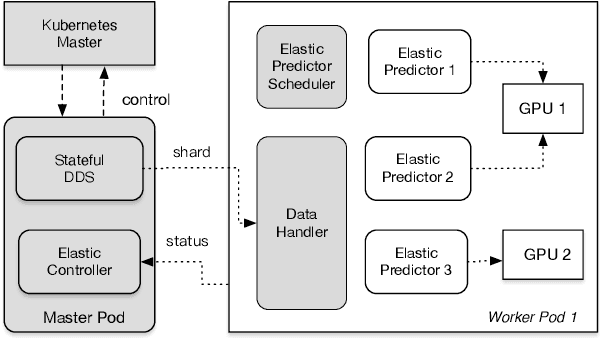
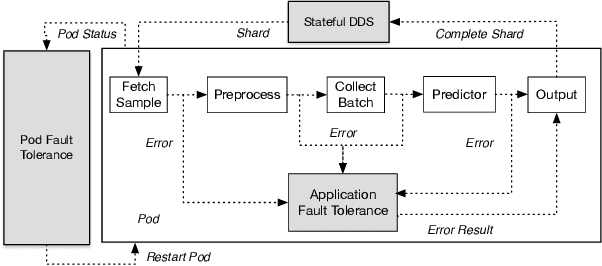
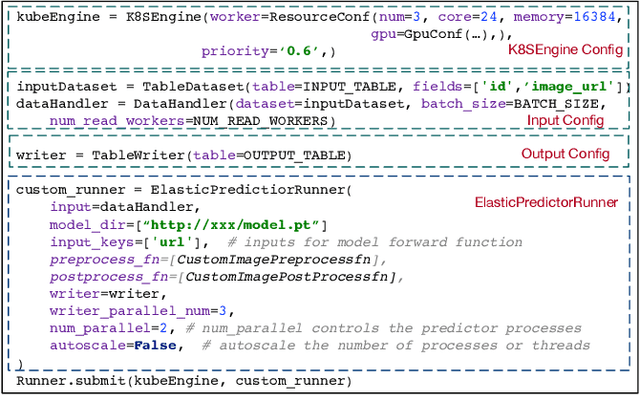
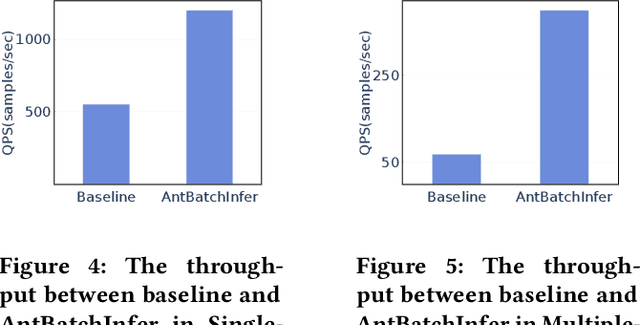
Offline batch inference is a common task in the industry for deep learning applications, but it can be challenging to ensure stability and performance when dealing with large amounts of data and complicated inference pipelines. This paper demonstrated AntBatchInfer, an elastic batch inference framework, which is specially optimized for the non-dedicated cluster. AntBatchInfer addresses these challenges by providing multi-level fault-tolerant capabilities, enabling the stable execution of versatile and long-running inference tasks. It also improves inference efficiency by pipelining, intra-node, and inter-node scaling. It further optimizes the performance in complicated multiple-model batch inference scenarios. Through extensive experiments and real-world statistics, we demonstrate the superiority of our framework in terms of stability and efficiency. In the experiment, it outperforms the baseline by at least $2\times$ and $6\times$ in the single-model or multiple-model batch inference. Also, it is widely used at Ant Group, with thousands of daily jobs from various scenarios, including DLRM, CV, and NLP, which proves its practicability in the industry.
M2-Encoder: Advancing Bilingual Image-Text Understanding by Large-scale Efficient Pretraining
Feb 04, 2024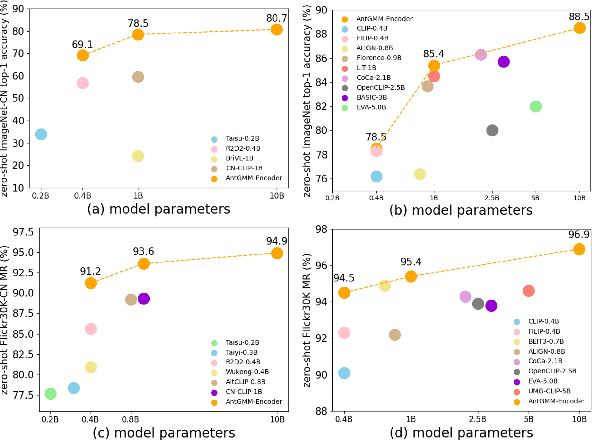
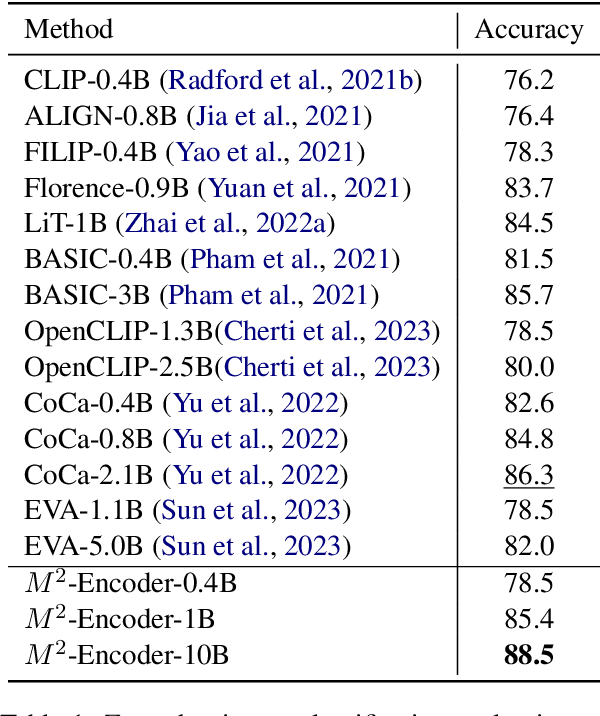
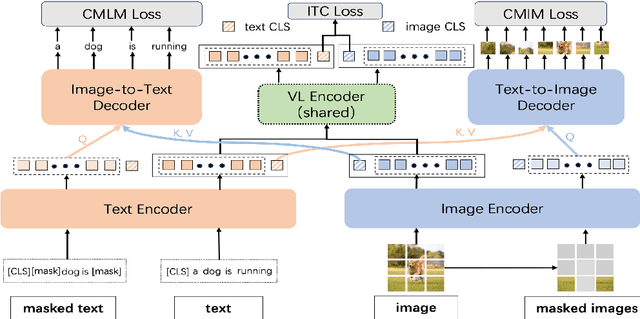
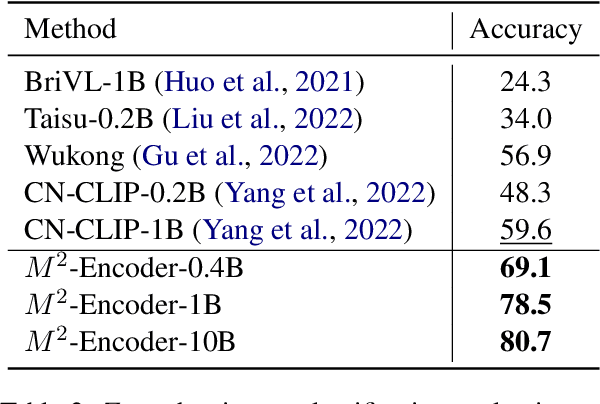
Vision-language foundation models like CLIP have revolutionized the field of artificial intelligence. Nevertheless, VLM models supporting multi-language, e.g., in both Chinese and English, have lagged due to the relative scarcity of large-scale pretraining datasets. Toward this end, we introduce a comprehensive bilingual (Chinese-English) dataset BM-6B with over 6 billion image-text pairs, aimed at enhancing multimodal foundation models to well understand images in both languages. To handle such a scale of dataset, we propose a novel grouped aggregation approach for image-text contrastive loss computation, which reduces the communication overhead and GPU memory demands significantly, facilitating a 60% increase in training speed. We pretrain a series of bilingual image-text foundation models with an enhanced fine-grained understanding ability on BM-6B, the resulting models, dubbed as $M^2$-Encoders (pronounced "M-Square"), set new benchmarks in both languages for multimodal retrieval and classification tasks. Notably, Our largest $M^2$-Encoder-10B model has achieved top-1 accuracies of 88.5% on ImageNet and 80.7% on ImageNet-CN under a zero-shot classification setting, surpassing previously reported SoTA methods by 2.2% and 21.1%, respectively. The $M^2$-Encoder series represents one of the most comprehensive bilingual image-text foundation models to date, so we are making it available to the research community for further exploration and development.
G-Meta: Distributed Meta Learning in GPU Clusters for Large-Scale Recommender Systems
Jan 09, 2024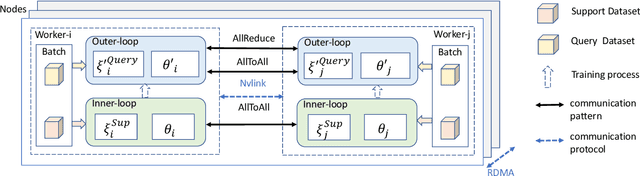
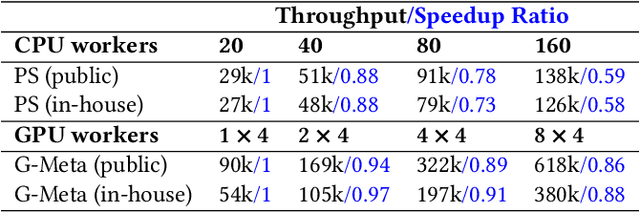
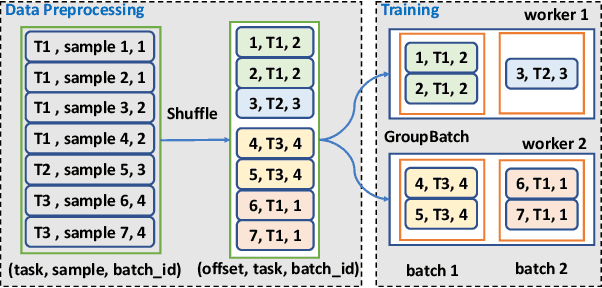
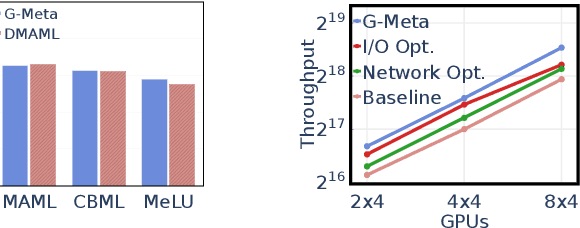
Recently, a new paradigm, meta learning, has been widely applied to Deep Learning Recommendation Models (DLRM) and significantly improves statistical performance, especially in cold-start scenarios. However, the existing systems are not tailored for meta learning based DLRM models and have critical problems regarding efficiency in distributed training in the GPU cluster. It is because the conventional deep learning pipeline is not optimized for two task-specific datasets and two update loops in meta learning. This paper provides a high-performance framework for large-scale training for Optimization-based Meta DLRM models over the \textbf{G}PU cluster, namely \textbf{G}-Meta. Firstly, G-Meta utilizes both data parallelism and model parallelism with careful orchestration regarding computation and communication efficiency, to enable high-speed distributed training. Secondly, it proposes a Meta-IO pipeline for efficient data ingestion to alleviate the I/O bottleneck. Various experimental results show that G-Meta achieves notable training speed without loss of statistical performance. Since early 2022, G-Meta has been deployed in Alipay's core advertising and recommender system, shrinking the continuous delivery of models by four times. It also obtains 6.48\% improvement in Conversion Rate (CVR) and 1.06\% increase in CPM (Cost Per Mille) in Alipay's homepage display advertising, with the benefit of larger training samples and tasks.
An Adaptive Placement and Parallelism Framework for Accelerating RLHF Training
Dec 19, 2023



Recently, ChatGPT or InstructGPT like large language models (LLM) has made a significant impact in the AI world. These models are incredibly versatile, capable of performing language tasks on par or even exceeding the capabilities of human experts. Many works have attempted to reproduce the complex InstructGPT's RLHF (Reinforcement Learning with Human Feedback) training pipeline. However, the mainstream distributed RLHF training methods typically adopt a fixed model placement strategy, referred to as the Flattening strategy. This strategy treats all four models involved in RLHF as a single entity and places them on all devices, regardless of their differences. Unfortunately, this strategy exacerbates the generation bottlenecks in the RLHF training and degrades the overall training efficiency. To address these issues, we propose an adaptive model placement framework that offers two flexible model placement strategies. These strategies allow for the agile allocation of models across devices in a fine-grained manner. The Interleaving strategy helps reduce memory redundancy and communication costs during RLHF training. On the other hand, the Separation strategy improves the throughput of model training by separating the training and generation stages of the RLHF pipeline. Notably, this framework seamlessly integrates with other mainstream techniques for acceleration and enables automatic hyperparameter search. Extensive experiments have demonstrated that our Interleaving and Separation strategies can achieve notable improvements up to 11x, compared to the current state-of-the-art (SOTA) approaches. These experiments encompassed a wide range of training scenarios, involving models of varying sizes and devices of different scales. The results highlight the effectiveness and superiority of our approaches in accelerating the training of distributed RLHF.
Rethinking Memory and Communication Cost for Efficient Large Language Model Training
Oct 09, 2023
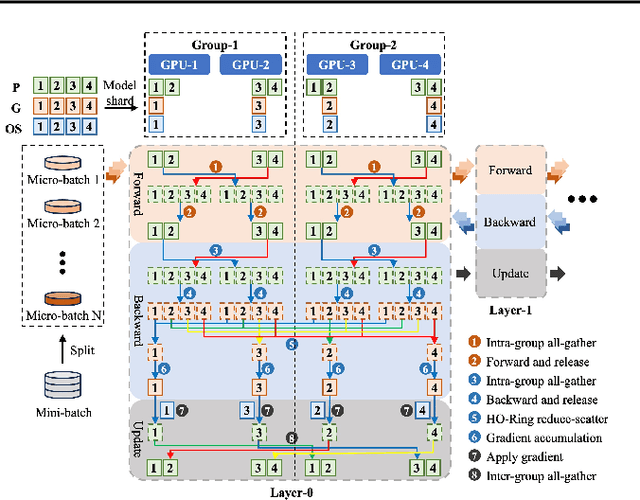
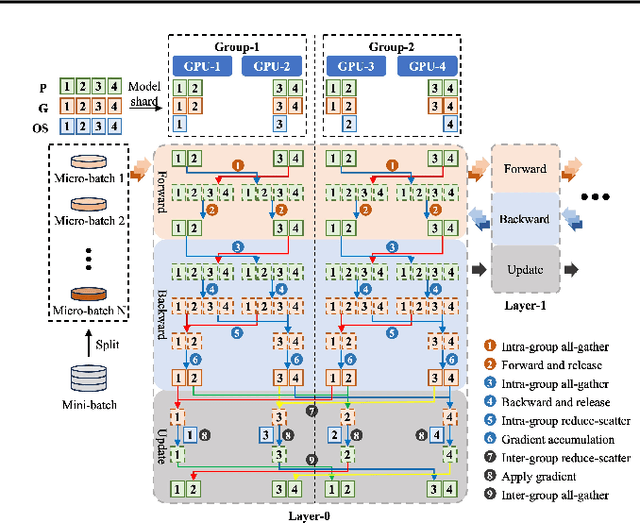
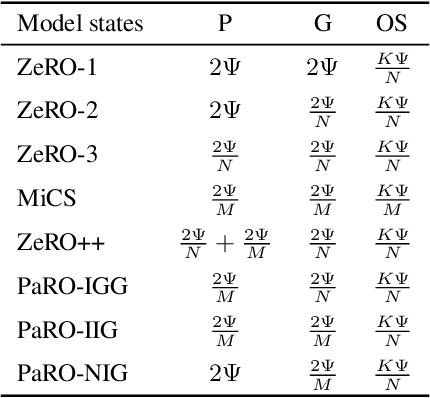
As model sizes and training datasets continue to increase, large-scale model training frameworks reduce memory consumption by various sharding techniques. However, the huge communication overhead reduces the training efficiency, especially in public cloud environments with varying network bandwidths. In this paper, we rethink the impact of memory consumption and communication overhead on the training speed of large language model, and propose a memory-communication balanced \underline{Pa}rtial \underline{R}edundancy \underline{O}ptimizer (PaRO). PaRO reduces the amount and frequency of inter-group communication by grouping GPU clusters and introducing minor intra-group memory redundancy, thereby improving the training efficiency of the model. Additionally, we propose a Hierarchical Overlapping Ring (HO-Ring) communication topology to enhance communication efficiency between nodes or across switches in large model training. Our experiments demonstrate that the HO-Ring algorithm improves communication efficiency by 32.6\% compared to the traditional Ring algorithm. Compared to the baseline ZeRO, PaRO significantly improves training throughput by 1.2x-2.6x and achieves a near-linear scalability. Therefore, the PaRO strategy provides more fine-grained options for the trade-off between memory consumption and communication overhead in different training scenarios.
Trust in AutoML: Exploring Information Needs for Establishing Trust in Automated Machine Learning Systems
Jan 17, 2020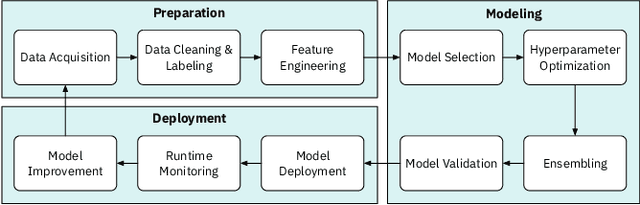

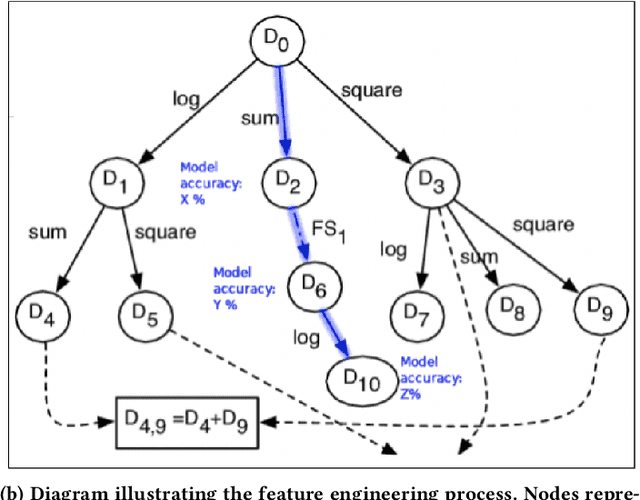
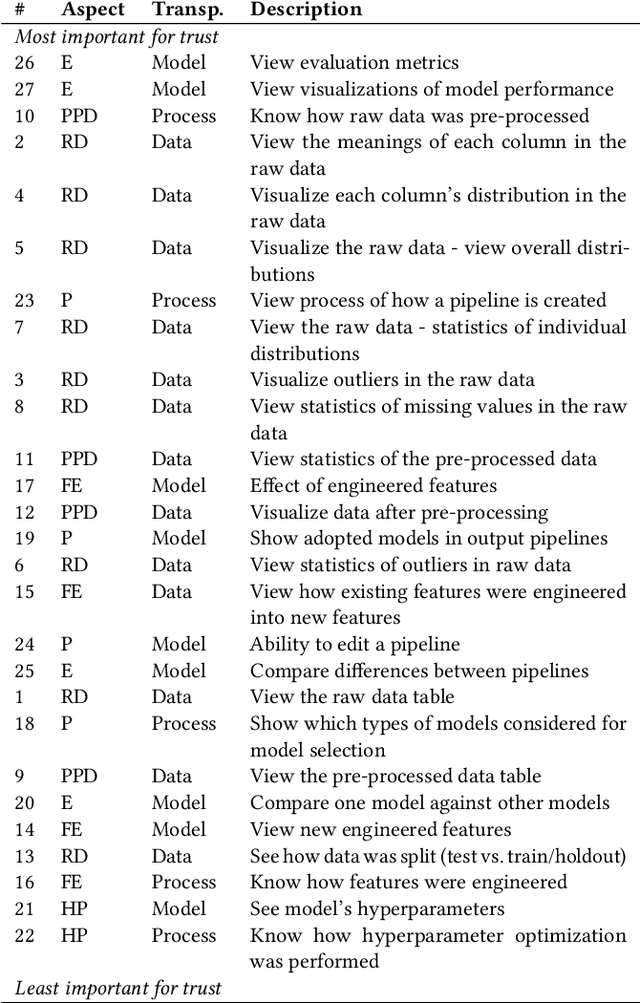
We explore trust in a relatively new area of data science: Automated Machine Learning (AutoML). In AutoML, AI methods are used to generate and optimize machine learning models by automatically engineering features, selecting models, and optimizing hyperparameters. In this paper, we seek to understand what kinds of information influence data scientists' trust in the models produced by AutoML? We operationalize trust as a willingness to deploy a model produced using automated methods. We report results from three studies -- qualitative interviews, a controlled experiment, and a card-sorting task -- to understand the information needs of data scientists for establishing trust in AutoML systems. We find that including transparency features in an AutoML tool increased user trust and understandability in the tool; and out of all proposed features, model performance metrics and visualizations are the most important information to data scientists when establishing their trust with an AutoML tool.