 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Jun 13, 2026Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities while remaining practical to train, serve, and deploy. In this report, we present Ling-2.6 and Ring-2.6, a family of models designed to address this challenge at scale. Ling-2.6 is optimized for instant response generation and high capability per output token, whereas Ring-2.6 is tailored for deeper reasoning and more advanced agentic workflows. Instead of training from scratch, we upgrade the Ling-2.0 base model through architectural migration pre-training and large-scale post-training. This upgrade is guided by a unified co-design of model architecture, optimization objectives, serving systems, and agent training environments, enabling improvements in both model capability and deployment efficiency. At the architectural level, we introduce a hybrid linear attention design that integrates Lightning Attention with MLA, improving the efficiency of long-context training and decoding. To further enhance token efficiency, we optimize capability per output token through Evolutionary Chain-of-Thought, Linguistic Unit Policy Optimization, bidirectional preference alignment, and shortest-correct-response distillation. For agentic capabilities, we propose KPop, a reinforcement learning framework designed to support stable training of Ring-2.6-1T on large-scale environment-grounded data. KPop improves training efficiency through asynchronous scheduling across coding, search, tool use, and workflow execution, enabling scalable learning from complex agent-environment interactions. Together, Ling-2.6 and Ring-2.6 provide a practical pathway toward efficient, scalable, and open agentic systems. We open-source all checkpoints in the 2.6 family to support further research and development in practical agentic intelligence.
Focal Reward: Balanced Reinforcement Learning under Rubric-Based Rewards
May 26, 2026The open-ended generation in LLMs usually requires multi-dimensional rubrics to adequately assess quality and guide the improvement of reinforcement learning. However, a critical dilemma inherent in this training paradigm is the imbalanced reward polarization along different rubric dimensions. Under this bottleneck, even if LLMs achieve relatively high rewards after training, they may still exhibit severe deficiencies in certain dimensions, leading to a direct deterioration in user experience. To address this problem, we propose Focal Reward, a novel objective to automatically balance the training of reinforcement learning under rubric-based rewards. Specifically, we first leverage an inverse reward projection mechanism to estimate the saturation degree of each criterion in the rubric, which forms the basis to calibrate the reward direction. Then, the final objective is designed with an automatically reweighting coefficient for each criterion to achieve the fine-grained balancing. Extensive experiments across three model scales and six benchmarks demonstrate that our Focal Reward method outperforms the strongest static aggregation baseline in all 18 model-benchmark comparisons. Rollout, mechanism, and ablation analyses further show that these gains arise from online, saturation-aware reallocation toward rubrics that still have room for improvement.
An Adaptive Placement and Parallelism Framework for Accelerating RLHF Training
Dec 19, 2023



Recently, ChatGPT or InstructGPT like large language models (LLM) has made a significant impact in the AI world. These models are incredibly versatile, capable of performing language tasks on par or even exceeding the capabilities of human experts. Many works have attempted to reproduce the complex InstructGPT's RLHF (Reinforcement Learning with Human Feedback) training pipeline. However, the mainstream distributed RLHF training methods typically adopt a fixed model placement strategy, referred to as the Flattening strategy. This strategy treats all four models involved in RLHF as a single entity and places them on all devices, regardless of their differences. Unfortunately, this strategy exacerbates the generation bottlenecks in the RLHF training and degrades the overall training efficiency. To address these issues, we propose an adaptive model placement framework that offers two flexible model placement strategies. These strategies allow for the agile allocation of models across devices in a fine-grained manner. The Interleaving strategy helps reduce memory redundancy and communication costs during RLHF training. On the other hand, the Separation strategy improves the throughput of model training by separating the training and generation stages of the RLHF pipeline. Notably, this framework seamlessly integrates with other mainstream techniques for acceleration and enables automatic hyperparameter search. Extensive experiments have demonstrated that our Interleaving and Separation strategies can achieve notable improvements up to 11x, compared to the current state-of-the-art (SOTA) approaches. These experiments encompassed a wide range of training scenarios, involving models of varying sizes and devices of different scales. The results highlight the effectiveness and superiority of our approaches in accelerating the training of distributed RLHF.
Modeling Event Propagation via Graph Biased Temporal Point Process
Aug 05, 2019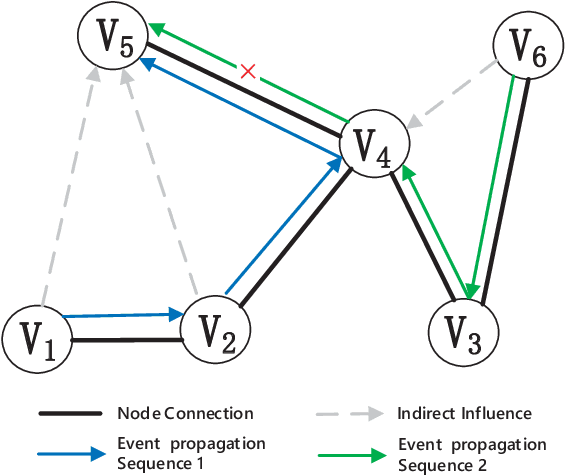
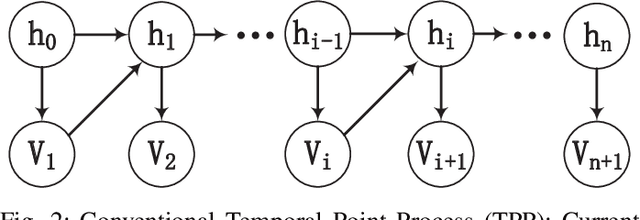
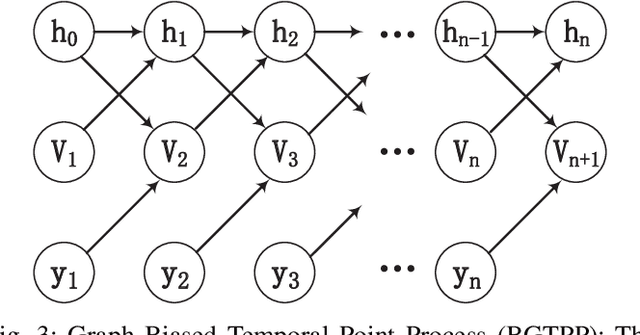
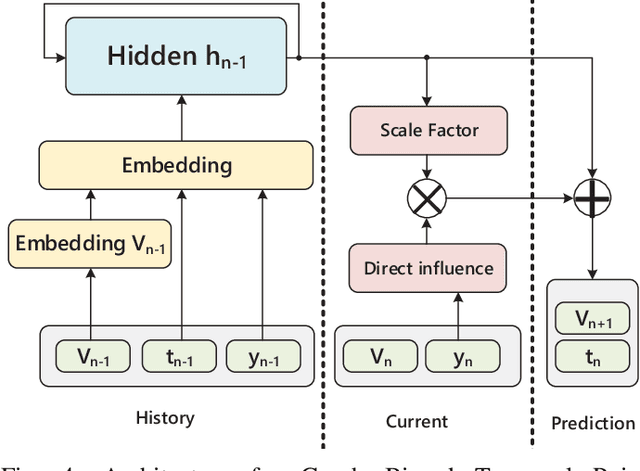
Temporal point process is widely used for sequential data modeling. In this paper, we focus on the problem of modeling sequential event propagation in graph, such as retweeting by social network users, news transmitting between websites, etc. Given a collection of event propagation sequences, conventional point process model consider only the event history, i.e. embed event history into a vector, not the latent graph structure. We propose a Graph Biased Temporal Point Process (GBTPP) leveraging the structural information from graph representation learning, where the direct influence between nodes and indirect influence from event history is modeled respectively. Moreover, the learned node embedding vector is also integrated into the embedded event history as side information. Experiments on a synthetic dataset and two real-world datasets show the efficacy of our model compared to conventional methods and state-of-the-art.
Reinforcement Learning with Policy Mixture Model for Temporal Point Processes Clustering
Jun 05, 2019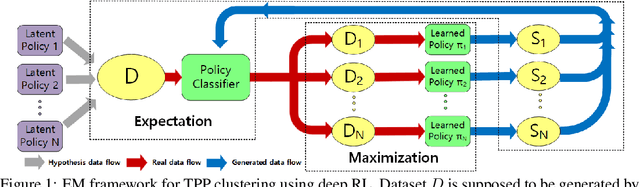

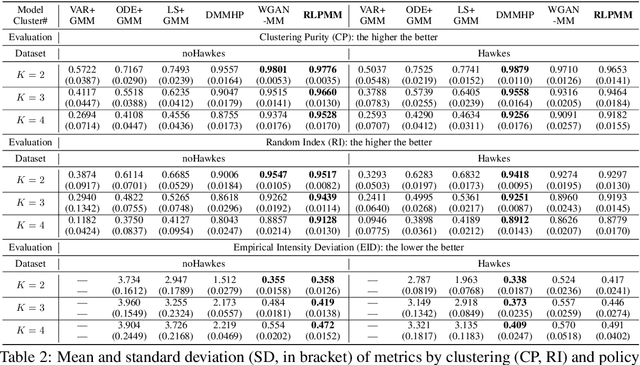

Temporal point process is an expressive tool for modeling event sequences over time. In this paper, we take a reinforcement learning view whereby the observed sequences are assumed to be generated from a mixture of latent policies. The purpose is to cluster the sequences with different temporal patterns into the underlying policies while learning each of the policy model. The flexibility of our model lies in: i) all the components are networks including the policy network for modeling the intensity function of temporal point process; ii) to handle varying-length event sequences, we resort to inverse reinforcement learning by decomposing the observed sequence into states (RNN hidden embedding of history) and actions (time interval to next event) in order to learn the reward function, thus achieving better performance or increasing efficiency compared to existing methods using rewards over the entire sequence such as log-likelihood or Wasserstein distance. We adopt an expectation-maximization framework with the E-step estimating the cluster labels for each sequence, and the M-step aiming to learn the respective policy. Extensive experiments show the efficacy of our method against state-of-the-arts.
Decoupled Learning for Factorial Marked Temporal Point Processes
Jan 21, 2018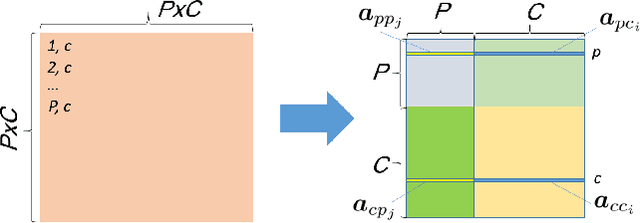
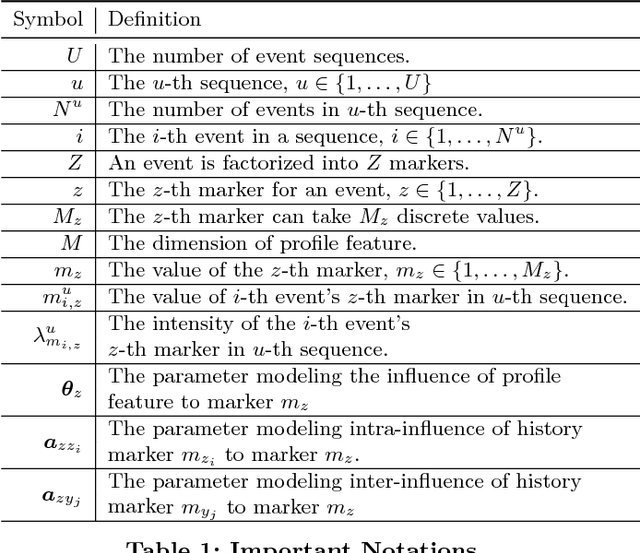
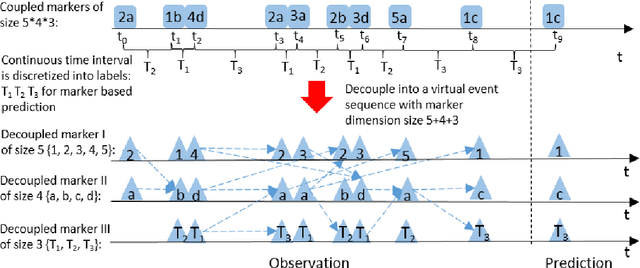

This paper introduces the factorial marked temporal point process model and presents efficient learning methods. In conventional (multi-dimensional) marked temporal point process models, event is often encoded by a single discrete variable i.e. a marker. In this paper, we describe the factorial marked point processes whereby time-stamped event is factored into multiple markers. Accordingly the size of the infectivity matrix modeling the effect between pairwise markers is in power order w.r.t. the number of the discrete marker space. We propose a decoupled learning method with two learning procedures: i) directly solving the model based on two techniques: Alternating Direction Method of Multipliers and Fast Iterative Shrinkage-Thresholding Algorithm; ii) involving a reformulation that transforms the original problem into a Logistic Regression model for more efficient learning. Moreover, a sparse group regularizer is added to identify the key profile features and event labels. Empirical results on real world datasets demonstrate the efficiency of our decoupled and reformulated method. The source code is available online.
Patient Flow Prediction via Discriminative Learning of Mutually-Correcting Processes
Nov 10, 2016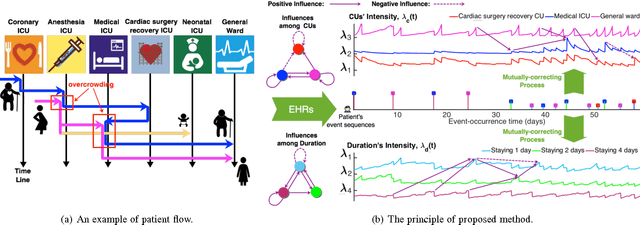
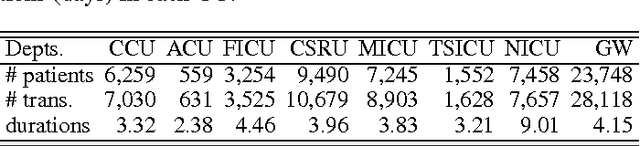
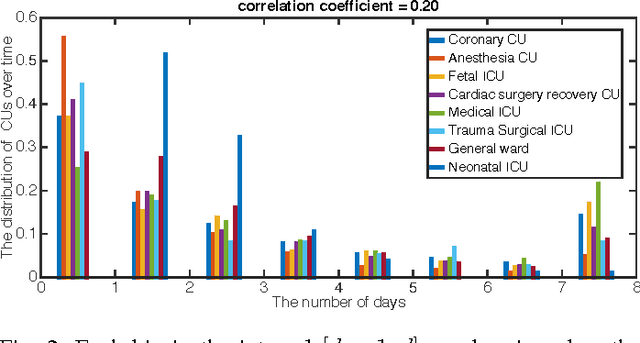

Over the past decade the rate of care unit (CU) use in the United States has been increasing. With an aging population and ever-growing demand for medical care, effective management of patients' transitions among different care facilities will prove indispensible for shortening the length of hospital stays, improving patient outcomes, allocating critical care resources, and reducing preventable re-admissions. In this paper, we focus on an important problem of predicting the so-called "patient flow" from longitudinal electronic health records (EHRs), which has not been explored via existing machine learning techniques. By treating a sequence of transition events as a point process, we develop a novel framework for modeling patient flow through various CUs and jointly predicting patients' destination CUs and duration days. Instead of learning a generative point process model via maximum likelihood estimation, we propose a novel discriminative learning algorithm aiming at improving the prediction of transition events in the case of sparse data. By parameterizing the proposed model as a mutually-correcting process, we formulate the estimation problem via generalized linear models, which lends itself to efficient learning based on alternating direction method of multipliers (ADMM). Furthermore, we achieve simultaneous feature selection and learning by adding a group-lasso regularizer to the ADMM algorithm. Additionally, for suppressing the negative influence of data imbalance on the learning of model, we synthesize auxiliary training data for the classes with extremely few samples, and improve the robustness of our learning method accordingly. Testing on real-world data, we show that our method obtains superior performance in terms of accuracy of predicting the destination CU transition and duration of each CU occupancy.