 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Sequence Parallelism Approach for Long Context Generative AI
May 15, 2024Sequence parallelism (SP), which divides the sequence dimension of input tensors across multiple computational devices, is becoming key to unlocking the long-context capabilities of generative AI models. This paper investigates the state-of-the-art SP approaches, i.e. DeepSpeed-Ulysses and Ring-Attention, and proposes a unified SP approach, which is more robust to transformer model architectures and network hardware topology. This paper compares the communication and memory cost of SP and existing parallelism, including data/tensor/zero/expert/pipeline parallelism, and discusses the best practices for designing hybrid 4D parallelism involving SP. We achieved 86% MFU on two 8xA800 nodes using SP for sequence length 208K for the LLAMA3-8B model. Our code is publicly available on \url{https://github.com/feifeibear/long-context-attention}.
G-Meta: Distributed Meta Learning in GPU Clusters for Large-Scale Recommender Systems
Jan 09, 2024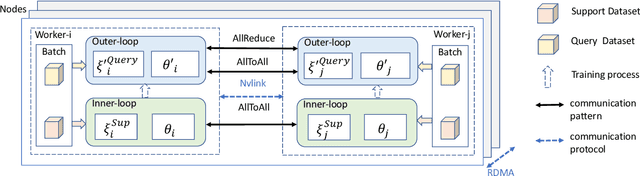
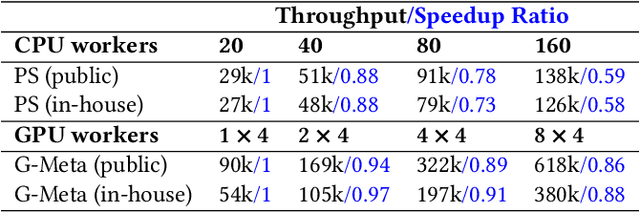
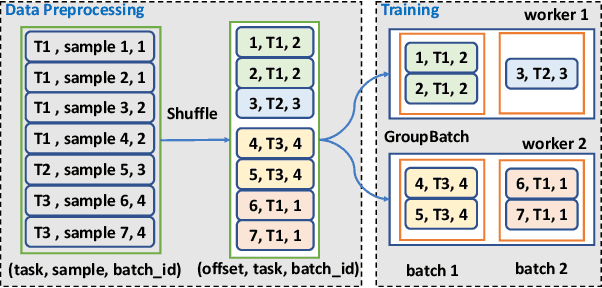
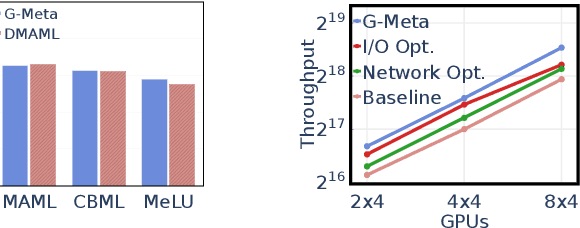
Recently, a new paradigm, meta learning, has been widely applied to Deep Learning Recommendation Models (DLRM) and significantly improves statistical performance, especially in cold-start scenarios. However, the existing systems are not tailored for meta learning based DLRM models and have critical problems regarding efficiency in distributed training in the GPU cluster. It is because the conventional deep learning pipeline is not optimized for two task-specific datasets and two update loops in meta learning. This paper provides a high-performance framework for large-scale training for Optimization-based Meta DLRM models over the \textbf{G}PU cluster, namely \textbf{G}-Meta. Firstly, G-Meta utilizes both data parallelism and model parallelism with careful orchestration regarding computation and communication efficiency, to enable high-speed distributed training. Secondly, it proposes a Meta-IO pipeline for efficient data ingestion to alleviate the I/O bottleneck. Various experimental results show that G-Meta achieves notable training speed without loss of statistical performance. Since early 2022, G-Meta has been deployed in Alipay's core advertising and recommender system, shrinking the continuous delivery of models by four times. It also obtains 6.48\% improvement in Conversion Rate (CVR) and 1.06\% increase in CPM (Cost Per Mille) in Alipay's homepage display advertising, with the benefit of larger training samples and tasks.
An Adaptive Placement and Parallelism Framework for Accelerating RLHF Training
Dec 19, 2023



Recently, ChatGPT or InstructGPT like large language models (LLM) has made a significant impact in the AI world. These models are incredibly versatile, capable of performing language tasks on par or even exceeding the capabilities of human experts. Many works have attempted to reproduce the complex InstructGPT's RLHF (Reinforcement Learning with Human Feedback) training pipeline. However, the mainstream distributed RLHF training methods typically adopt a fixed model placement strategy, referred to as the Flattening strategy. This strategy treats all four models involved in RLHF as a single entity and places them on all devices, regardless of their differences. Unfortunately, this strategy exacerbates the generation bottlenecks in the RLHF training and degrades the overall training efficiency. To address these issues, we propose an adaptive model placement framework that offers two flexible model placement strategies. These strategies allow for the agile allocation of models across devices in a fine-grained manner. The Interleaving strategy helps reduce memory redundancy and communication costs during RLHF training. On the other hand, the Separation strategy improves the throughput of model training by separating the training and generation stages of the RLHF pipeline. Notably, this framework seamlessly integrates with other mainstream techniques for acceleration and enables automatic hyperparameter search. Extensive experiments have demonstrated that our Interleaving and Separation strategies can achieve notable improvements up to 11x, compared to the current state-of-the-art (SOTA) approaches. These experiments encompassed a wide range of training scenarios, involving models of varying sizes and devices of different scales. The results highlight the effectiveness and superiority of our approaches in accelerating the training of distributed RLHF.