 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMAD: Evidence-Centric Grounded Multimodal Diagnosis for Alzheimer's Disease
Feb 22, 2026Deep learning models for medical image analysis often act as black boxes, seldom aligning with clinical guidelines or explicitly linking decisions to supporting evidence. This is especially critical in Alzheimer's disease (AD), where predictions should be grounded in both anatomical and clinical findings. We present EMAD, a vision-language framework that generates structured AD diagnostic reports in which each claim is explicitly grounded in multimodal evidence. EMAD uses a hierarchical Sentence-Evidence-Anatomy (SEA) grounding mechanism: (i) sentence-to-evidence grounding links generated sentences to clinical evidence phrases, and (ii) evidence-to-anatomy grounding localizes corresponding structures on 3D brain MRI. To reduce dense annotation requirements, we propose GTX-Distill, which transfers grounding behavior from a teacher trained with limited supervision to a student operating on model-generated reports. We further introduce Executable-Rule GRPO, a reinforcement fine-tuning scheme with verifiable rewards that enforces clinical consistency, protocol adherence, and reasoning-diagnosis coherence. On the AD-MultiSense dataset, EMAD achieves state-of-the-art diagnostic accuracy and produces more transparent, anatomically faithful reports than existing methods. We will release code and grounding annotations to support future research in trustworthy medical vision-language models.
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Jun 18, 2025We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
AntDT: A Self-Adaptive Distributed Training Framework for Leader and Straggler Nodes
Apr 15, 2024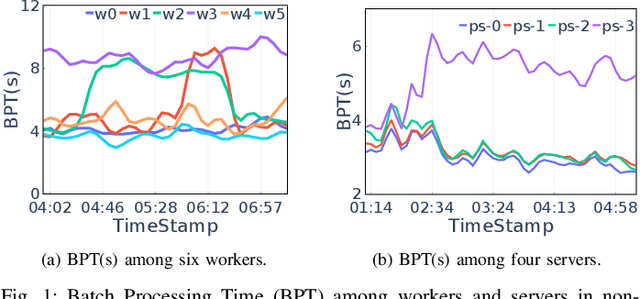
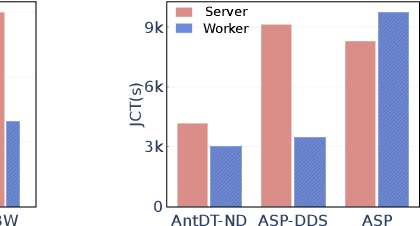
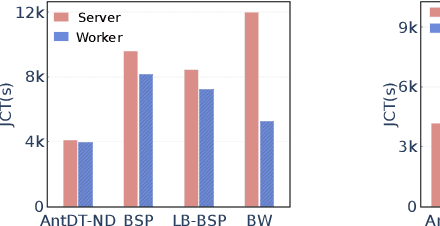
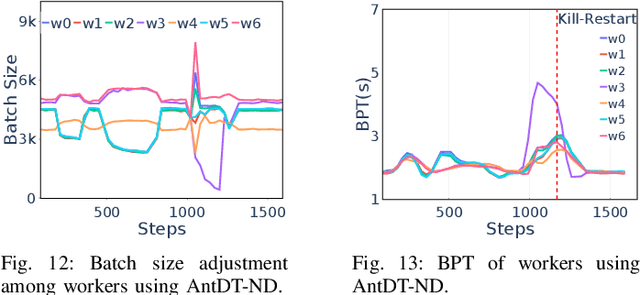
Many distributed training techniques like Parameter Server and AllReduce have been proposed to take advantage of the increasingly large data and rich features. However, stragglers frequently occur in distributed training due to resource contention and hardware heterogeneity, which significantly hampers the training efficiency. Previous works only address part of the stragglers and could not adaptively solve various stragglers in practice. Additionally, it is challenging to use a systematic framework to address all stragglers because different stragglers require diverse data allocation and fault-tolerance mechanisms. Therefore, this paper proposes a unified distributed training framework called AntDT (Ant Distributed Training Framework) to adaptively solve the straggler problems. Firstly, the framework consists of four components, including the Stateful Dynamic Data Sharding service, Monitor, Controller, and Agent. These components work collaboratively to efficiently distribute workloads and provide a range of pre-defined straggler mitigation methods with fault tolerance, thereby hiding messy details of data allocation and fault handling. Secondly, the framework provides a high degree of flexibility, allowing for the customization of straggler mitigation solutions based on the specific circumstances of the cluster. Leveraging this flexibility, we introduce two straggler mitigation solutions, namely AntDT-ND for non-dedicated clusters and AntDT-DD for dedicated clusters, as practical examples to resolve various types of stragglers at Ant Group. Justified by our comprehensive experiments and industrial deployment statistics, AntDT outperforms other SOTA methods more than 3x in terms of training efficiency. Additionally, in Alipay's homepage recommendation scenario, using AntDT reduces the training duration of the ranking model from 27.8 hours to just 5.4 hours.
G-Meta: Distributed Meta Learning in GPU Clusters for Large-Scale Recommender Systems
Jan 09, 2024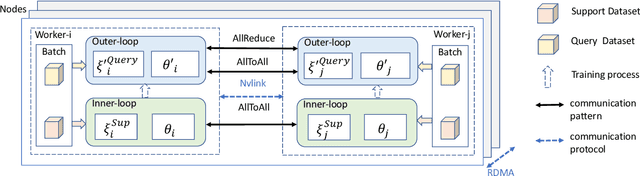
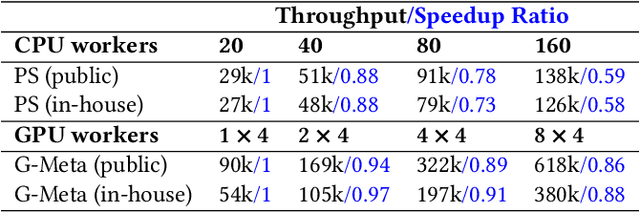
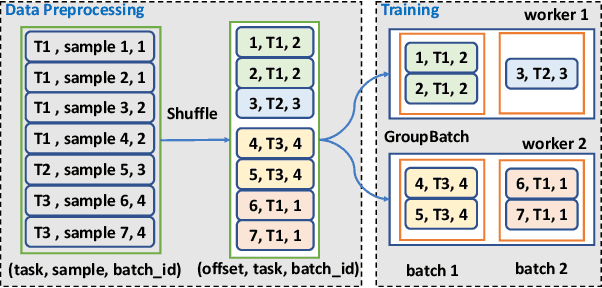
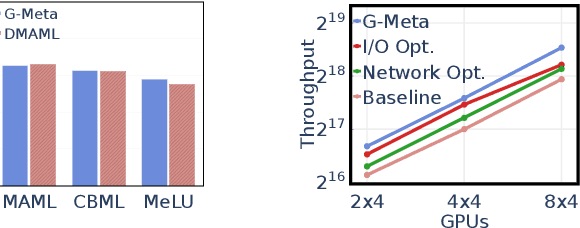
Recently, a new paradigm, meta learning, has been widely applied to Deep Learning Recommendation Models (DLRM) and significantly improves statistical performance, especially in cold-start scenarios. However, the existing systems are not tailored for meta learning based DLRM models and have critical problems regarding efficiency in distributed training in the GPU cluster. It is because the conventional deep learning pipeline is not optimized for two task-specific datasets and two update loops in meta learning. This paper provides a high-performance framework for large-scale training for Optimization-based Meta DLRM models over the \textbf{G}PU cluster, namely \textbf{G}-Meta. Firstly, G-Meta utilizes both data parallelism and model parallelism with careful orchestration regarding computation and communication efficiency, to enable high-speed distributed training. Secondly, it proposes a Meta-IO pipeline for efficient data ingestion to alleviate the I/O bottleneck. Various experimental results show that G-Meta achieves notable training speed without loss of statistical performance. Since early 2022, G-Meta has been deployed in Alipay's core advertising and recommender system, shrinking the continuous delivery of models by four times. It also obtains 6.48\% improvement in Conversion Rate (CVR) and 1.06\% increase in CPM (Cost Per Mille) in Alipay's homepage display advertising, with the benefit of larger training samples and tasks.
An Adaptive Placement and Parallelism Framework for Accelerating RLHF Training
Dec 19, 2023



Recently, ChatGPT or InstructGPT like large language models (LLM) has made a significant impact in the AI world. These models are incredibly versatile, capable of performing language tasks on par or even exceeding the capabilities of human experts. Many works have attempted to reproduce the complex InstructGPT's RLHF (Reinforcement Learning with Human Feedback) training pipeline. However, the mainstream distributed RLHF training methods typically adopt a fixed model placement strategy, referred to as the Flattening strategy. This strategy treats all four models involved in RLHF as a single entity and places them on all devices, regardless of their differences. Unfortunately, this strategy exacerbates the generation bottlenecks in the RLHF training and degrades the overall training efficiency. To address these issues, we propose an adaptive model placement framework that offers two flexible model placement strategies. These strategies allow for the agile allocation of models across devices in a fine-grained manner. The Interleaving strategy helps reduce memory redundancy and communication costs during RLHF training. On the other hand, the Separation strategy improves the throughput of model training by separating the training and generation stages of the RLHF pipeline. Notably, this framework seamlessly integrates with other mainstream techniques for acceleration and enables automatic hyperparameter search. Extensive experiments have demonstrated that our Interleaving and Separation strategies can achieve notable improvements up to 11x, compared to the current state-of-the-art (SOTA) approaches. These experiments encompassed a wide range of training scenarios, involving models of varying sizes and devices of different scales. The results highlight the effectiveness and superiority of our approaches in accelerating the training of distributed RLHF.