 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntDT: A Self-Adaptive Distributed Training Framework for Leader and Straggler Nodes
Paper and Code
Apr 15, 2024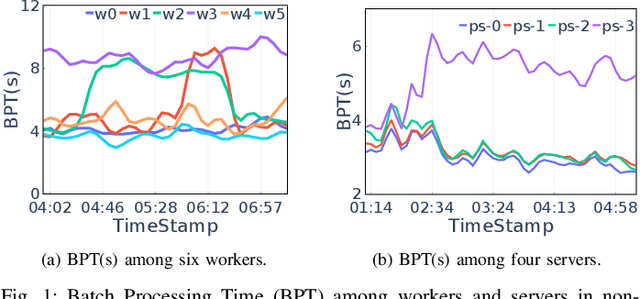
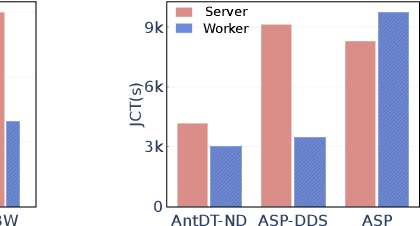
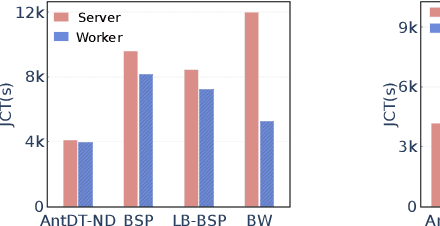
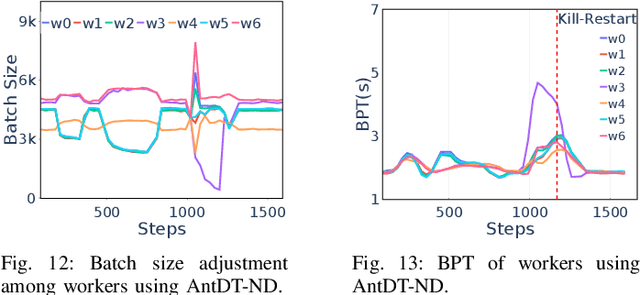
Many distributed training techniques like Parameter Server and AllReduce have been proposed to take advantage of the increasingly large data and rich features. However, stragglers frequently occur in distributed training due to resource contention and hardware heterogeneity, which significantly hampers the training efficiency. Previous works only address part of the stragglers and could not adaptively solve various stragglers in practice. Additionally, it is challenging to use a systematic framework to address all stragglers because different stragglers require diverse data allocation and fault-tolerance mechanisms. Therefore, this paper proposes a unified distributed training framework called AntDT (Ant Distributed Training Framework) to adaptively solve the straggler problems. Firstly, the framework consists of four components, including the Stateful Dynamic Data Sharding service, Monitor, Controller, and Agent. These components work collaboratively to efficiently distribute workloads and provide a range of pre-defined straggler mitigation methods with fault tolerance, thereby hiding messy details of data allocation and fault handling. Secondly, the framework provides a high degree of flexibility, allowing for the customization of straggler mitigation solutions based on the specific circumstances of the cluster. Leveraging this flexibility, we introduce two straggler mitigation solutions, namely AntDT-ND for non-dedicated clusters and AntDT-DD for dedicated clusters, as practical examples to resolve various types of stragglers at Ant Group. Justified by our comprehensive experiments and industrial deployment statistics, AntDT outperforms other SOTA methods more than 3x in terms of training efficiency. Additionally, in Alipay's homepage recommendation scenario, using AntDT reduces the training duration of the ranking model from 27.8 hours to just 5.4 hours.