 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Policy Mixture Model for Temporal Point Processes Clustering
Paper and Code
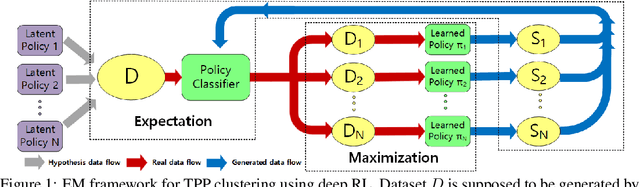

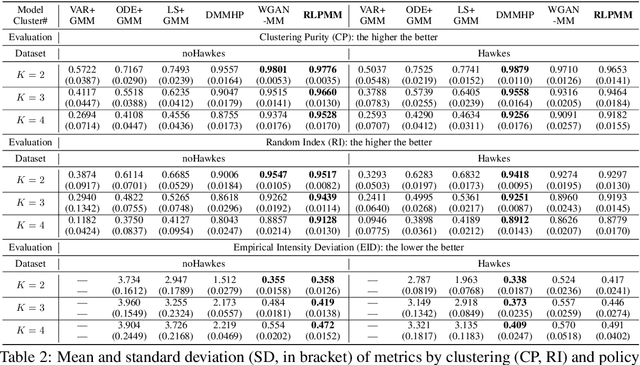

Temporal point process is an expressive tool for modeling event sequences over time. In this paper, we take a reinforcement learning view whereby the observed sequences are assumed to be generated from a mixture of latent policies. The purpose is to cluster the sequences with different temporal patterns into the underlying policies while learning each of the policy model. The flexibility of our model lies in: i) all the components are networks including the policy network for modeling the intensity function of temporal point process; ii) to handle varying-length event sequences, we resort to inverse reinforcement learning by decomposing the observed sequence into states (RNN hidden embedding of history) and actions (time interval to next event) in order to learn the reward function, thus achieving better performance or increasing efficiency compared to existing methods using rewards over the entire sequence such as log-likelihood or Wasserstein distance. We adopt an expectation-maximization framework with the E-step estimating the cluster labels for each sequence, and the M-step aiming to learn the respective policy. Extensive experiments show the efficacy of our method against state-of-the-arts.