 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntBatchInfer: Elastic Batch Inference in the Kubernetes Cluster
Paper and Code
Apr 15, 2024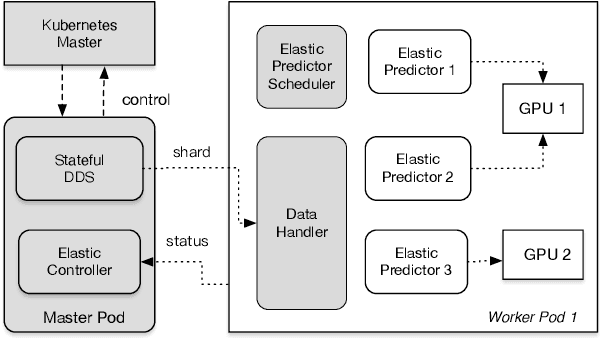
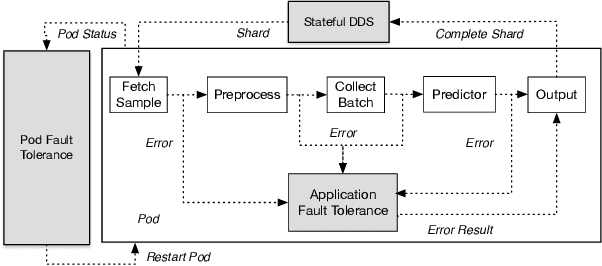
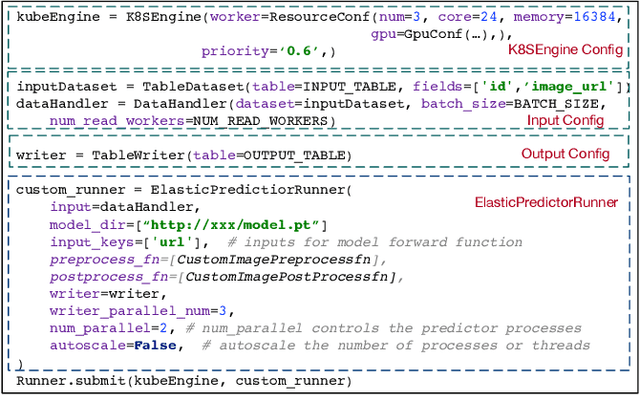
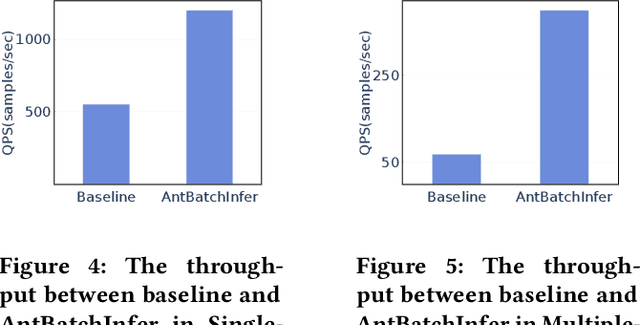
Offline batch inference is a common task in the industry for deep learning applications, but it can be challenging to ensure stability and performance when dealing with large amounts of data and complicated inference pipelines. This paper demonstrated AntBatchInfer, an elastic batch inference framework, which is specially optimized for the non-dedicated cluster. AntBatchInfer addresses these challenges by providing multi-level fault-tolerant capabilities, enabling the stable execution of versatile and long-running inference tasks. It also improves inference efficiency by pipelining, intra-node, and inter-node scaling. It further optimizes the performance in complicated multiple-model batch inference scenarios. Through extensive experiments and real-world statistics, we demonstrate the superiority of our framework in terms of stability and efficiency. In the experiment, it outperforms the baseline by at least $2\times$ and $6\times$ in the single-model or multiple-model batch inference. Also, it is widely used at Ant Group, with thousands of daily jobs from various scenarios, including DLRM, CV, and NLP, which proves its practicability in the industry.