 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Memory and Communication Cost for Efficient Large Language Model Training
Oct 09, 2023
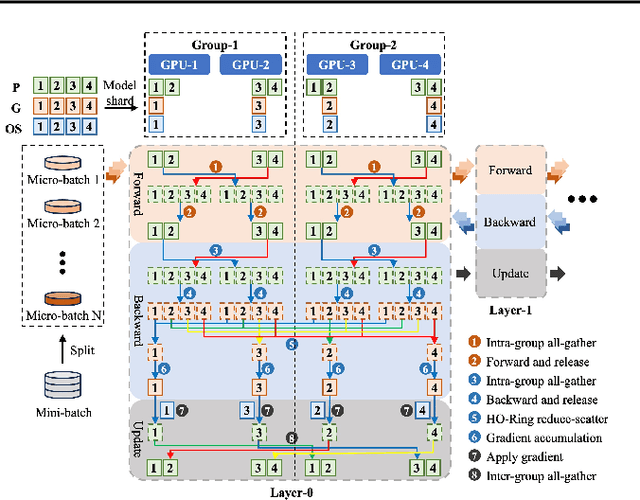
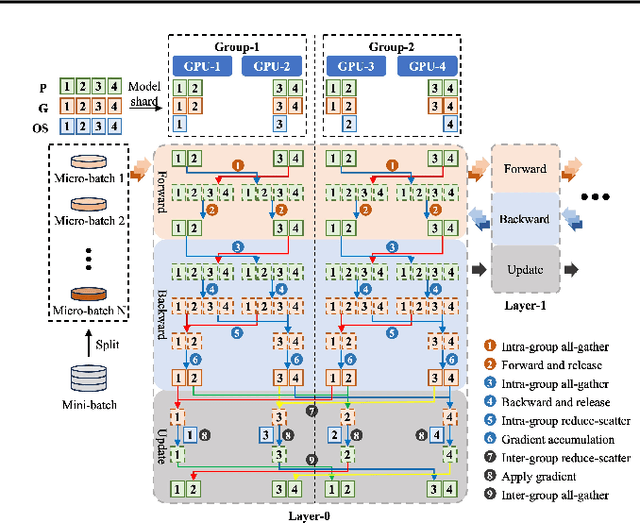
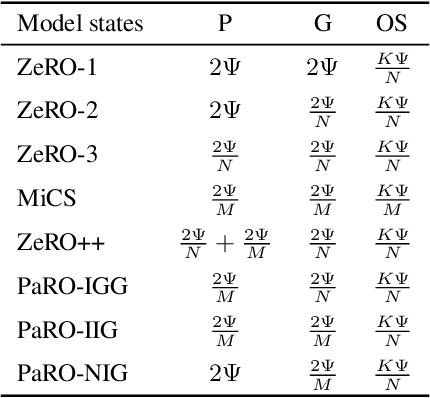
As model sizes and training datasets continue to increase, large-scale model training frameworks reduce memory consumption by various sharding techniques. However, the huge communication overhead reduces the training efficiency, especially in public cloud environments with varying network bandwidths. In this paper, we rethink the impact of memory consumption and communication overhead on the training speed of large language model, and propose a memory-communication balanced \underline{Pa}rtial \underline{R}edundancy \underline{O}ptimizer (PaRO). PaRO reduces the amount and frequency of inter-group communication by grouping GPU clusters and introducing minor intra-group memory redundancy, thereby improving the training efficiency of the model. Additionally, we propose a Hierarchical Overlapping Ring (HO-Ring) communication topology to enhance communication efficiency between nodes or across switches in large model training. Our experiments demonstrate that the HO-Ring algorithm improves communication efficiency by 32.6\% compared to the traditional Ring algorithm. Compared to the baseline ZeRO, PaRO significantly improves training throughput by 1.2x-2.6x and achieves a near-linear scalability. Therefore, the PaRO strategy provides more fine-grained options for the trade-off between memory consumption and communication overhead in different training scenarios.